 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSGaussian: Progressive Rate-Distortion Compression and Segmentation for 3D Gaussian Splatting
Jan 19, 2026We present the first unified framework for rate-distortion-optimized compression and segmentation of 3D Gaussian Splatting (3DGS). While 3DGS has proven effective for both real-time rendering and semantic scene understanding, prior works have largely treated these tasks independently, leaving their joint consideration unexplored. Inspired by recent advances in rate-distortion-optimized 3DGS compression, this work integrates semantic learning into the compression pipeline to support decoder-side applications--such as scene editing and manipulation--that extend beyond traditional scene reconstruction and view synthesis. Our scheme features a lightweight implicit neural representation-based hyperprior, enabling efficient entropy coding of both color and semantic attributes while avoiding costly grid-based hyperprior as seen in many prior works. To facilitate compression and segmentation, we further develop compression-guided segmentation learning, consisting of quantization-aware training to enhance feature separability and a quality-aware weighting mechanism to suppress unreliable Gaussian primitives. Extensive experiments on the LERF and 3D-OVS datasets demonstrate that our approach significantly reduces transmission cost while preserving high rendering quality and strong segmentation performance.
MH-LVC: Multi-Hypothesis Temporal Prediction for Learned Conditional Residual Video Coding
Oct 14, 2025This work, termed MH-LVC, presents a multi-hypothesis temporal prediction scheme that employs long- and short-term reference frames in a conditional residual video coding framework. Recent temporal context mining approaches to conditional video coding offer superior coding performance. However, the need to store and access a large amount of implicit contextual information extracted from past decoded frames in decoding a video frame poses a challenge due to excessive memory access. Our MH-LVC overcomes this issue by storing multiple long- and short-term reference frames but limiting the number of reference frames used at a time for temporal prediction to two. Our decoded frame buffer management allows the encoder to flexibly utilize the long-term key frames to mitigate temporal cascading errors and the short-term reference frames to minimize prediction errors. Moreover, our buffering scheme enables the temporal prediction structure to be adapted to individual input videos. While this flexibility is common in traditional video codecs, it has not been fully explored for learned video codecs. Extensive experiments show that the proposed method outperforms VTM-17.0 under the low-delay B configuration in terms of PSNR-RGB across commonly used test datasets, and performs comparably to the state-of-the-art learned codecs (e.g.~DCVC-FM) while requiring less decoded frame buffer and similar decoding time.
TFIC: End-to-End Text-Focused Image Compression for Coding for Machines
Mar 25, 2025

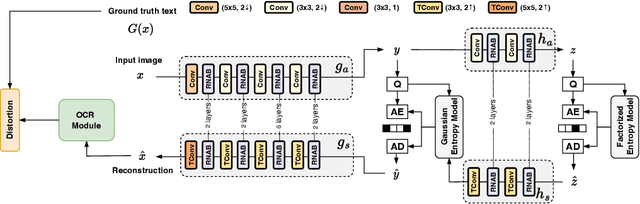

Traditional image compression methods aim to faithfully reconstruct images for human perception. In contrast, Coding for Machines focuses on compressing images to preserve information relevant to a specific machine task. In this paper, we present an image compression system designed to retain text-specific features for subsequent Optical Character Recognition (OCR). Our encoding process requires half the time needed by the OCR module, making it especially suitable for devices with limited computational capacity. In scenarios where on-device OCR is computationally prohibitive, images are compressed and later processed to recover the text content. Experimental results demonstrate that our method achieves significant improvements in text extraction accuracy at low bitrates, even improving over the accuracy of OCR performed on uncompressed images, thus acting as a local pre-processing step.
Is JPEG AI going to change image forensics?
Dec 04, 2024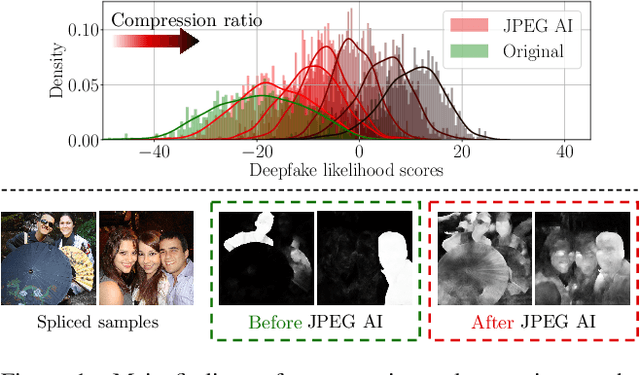
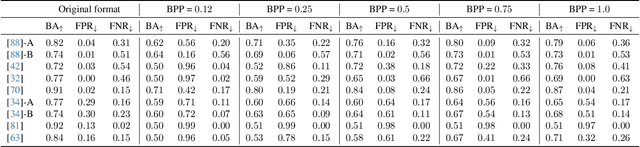
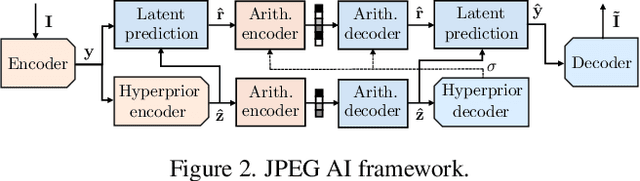
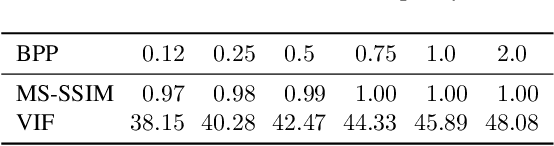
In this paper, we investigate the counter-forensic effects of the forthcoming JPEG AI standard based on neural image compression, focusing on two critical areas: deepfake image detection and image splicing localization. Neural image compression leverages advanced neural network algorithms to achieve higher compression rates while maintaining image quality. However, it introduces artifacts that closely resemble those generated by image synthesis techniques and image splicing pipelines, complicating the work of researchers when discriminating pristine from manipulated content. We comprehensively analyze JPEG AI's counter-forensic effects through extensive experiments on several state-of-the-art detectors and datasets. Our results demonstrate that an increase in false alarms impairs the performance of leading forensic detectors when analyzing genuine content processed through JPEG AI. By exposing the vulnerabilities of the available forensic tools we aim to raise the urgent need for multimedia forensics researchers to include JPEG AI images in their experimental setups and develop robust forensic techniques to distinguish between neural compression artifacts and actual manipulations.
Learning Optimal Linear Block Transform by Rate Distortion Minimization
Nov 27, 2024



Linear block transform coding remains a fundamental component of image and video compression. Although the Discrete Cosine Transform (DCT) is widely employed in all current compression standards, its sub-optimality has sparked ongoing research into discovering more efficient alternative transforms even for fields where it represents a consolidated tool. In this paper, we introduce a novel linear block transform called the Rate Distortion Learned Transform (RDLT), a data-driven transform specifically designed to minimize the rate-distortion (RD) cost when approximating residual blocks. Our approach builds on the latest end-to-end learned compression frameworks, adopting back-propagation and stochastic gradient descent for optimization. However, unlike the nonlinear transforms used in variational autoencoder (VAE)-based methods, the goal is to create a simpler yet optimal linear block transform, ensuring practical integration into existing image and video compression standards. Differently from existing data-driven methods that design transforms based on sample covariance matrices, such as the Karhunen-Lo\`eve Transform (KLT), the proposed RDLT is directly optimized from an RD perspective. Experimental results show that this transform significantly outperforms the DCT or other existing data-driven transforms. Additionally, it is shown that when simulating the integration of our RDLT into a VVC-like image compression framework, the proposed transform brings substantial improvements. All the code used in our experiments has been made publicly available at [1].
Variable-size Symmetry-based Graph Fourier Transforms for image compression
Nov 24, 2024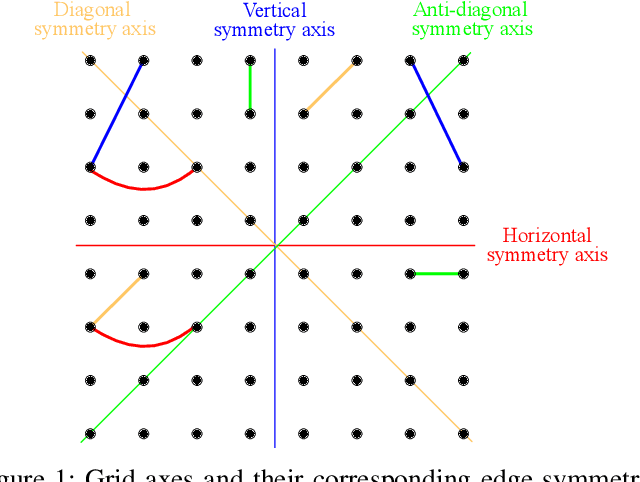
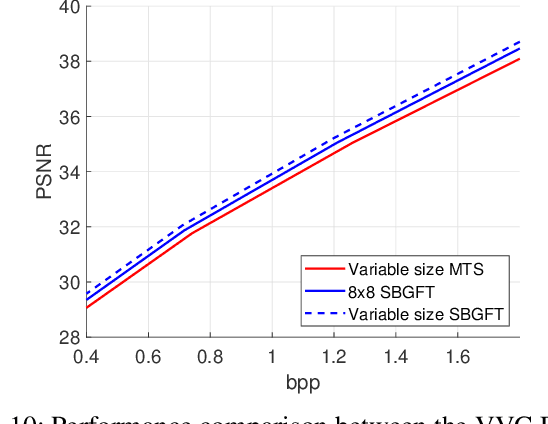
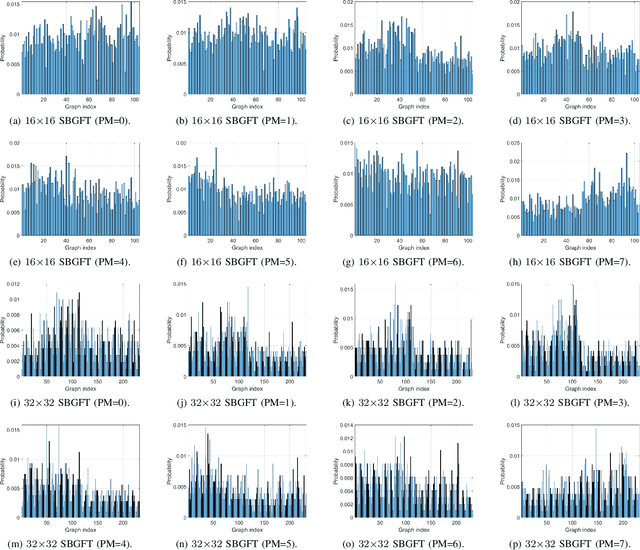
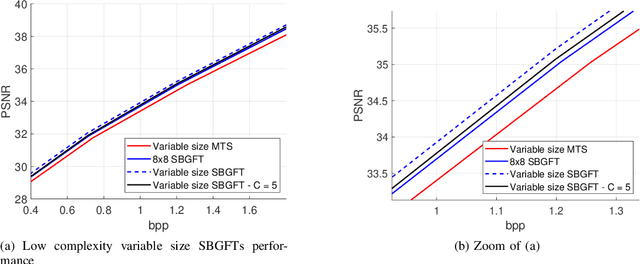
Modern compression systems use linear transformations in their encoding and decoding processes, with transforms providing compact signal representations. While multiple data-dependent transforms for image/video coding can adapt to diverse statistical characteristics, assembling large datasets to learn each transform is challenging. Also, the resulting transforms typically lack fast implementation, leading to significant computational costs. Thus, despite many papers proposing new transform families, the most recent compression standards predominantly use traditional separable sinusoidal transforms. This paper proposes integrating a new family of Symmetry-based Graph Fourier Transforms (SBGFTs) of variable sizes into a coding framework, focusing on the extension from our previously introduced 8x8 SBGFTs to the general case of NxN grids. SBGFTs are non-separable transforms that achieve sparse signal representation while maintaining low computational complexity thanks to their symmetry properties. Their design is based on our proposed algorithm, which generates symmetric graphs on the grid by adding specific symmetrical connections between nodes and does not require any data-dependent adaptation. Furthermore, for video intra-frame coding, we exploit the correlations between optimal graphs and prediction modes to reduce the cardinality of the transform sets, thus proposing a low-complexity framework. Experiments show that SBGFTs outperform the primary transforms integrated in the explicit Multiple Transform Selection (MTS) used in the latest VVC intra-coding, providing a bit rate saving percentage of 6.23%, with only a marginal increase in average complexity. A MATLAB implementation of the proposed algorithm is available online at [1].
ComNeck: Bridging Compressed Image Latents and Multimodal LLMs via Universal Transform-Neck
Jul 29, 2024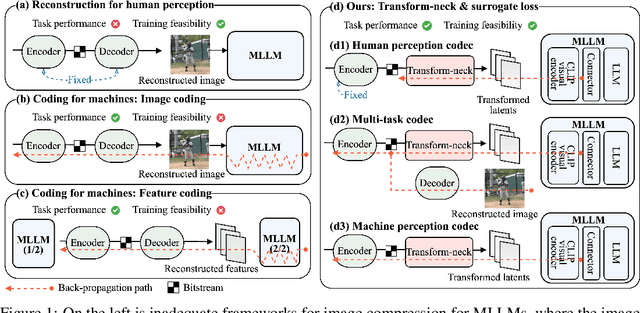

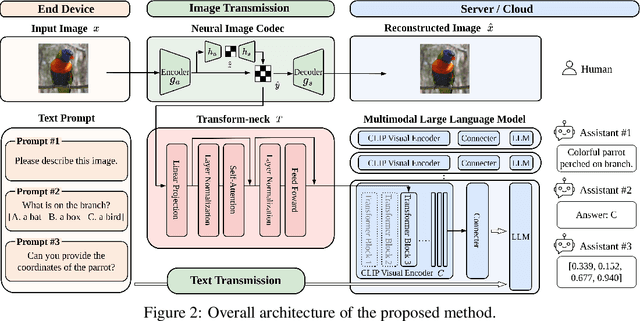
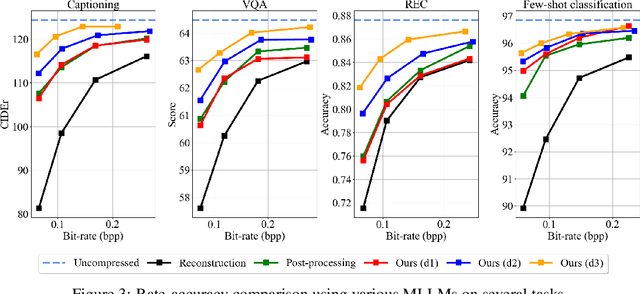
This paper presents the first-ever study of adapting compressed image latents to suit the needs of downstream vision tasks that adopt Multimodal Large Language Models (MLLMs). MLLMs have extended the success of large language models to modalities (e.g. images) beyond text, but their billion scale hinders deployment on resource-constrained end devices. While cloud-hosted MLLMs could be available, transmitting raw, uncompressed images captured by end devices to the cloud requires an efficient image compression system. To address this, we focus on emerging neural image compression and propose a novel framework with a lightweight transform-neck and a surrogate loss to adapt compressed image latents for MLLM-based vision tasks. The proposed framework is generic and applicable to multiple application scenarios, where the neural image codec can be (1) pre-trained for human perception without updating, (2) fully updated for joint human and machine perception, or (3) fully updated for only machine perception. The transform-neck trained with the surrogate loss is universal, for it can serve various downstream vision tasks enabled by a variety of MLLMs that share the same visual encoder. Our framework has the striking feature of excluding the downstream MLLMs from training the transform-neck, and potentially the neural image codec as well. This stands out from most existing coding for machine approaches that involve downstream networks in training and thus could be impractical when the networks are MLLMs. Extensive experiments on different neural image codecs and various MLLM-based vision tasks show that our method achieves great rate-accuracy performance with much less complexity, demonstrating its effectiveness.
Transformer-based Learned Image Compression for Joint Decoding and Denoising
Feb 20, 2024



This work introduces a Transformer-based image compression system. It has the flexibility to switch between the standard image reconstruction and the denoising reconstruction from a single compressed bitstream. Instead of training separate decoders for these tasks, we incorporate two add-on modules to adapt a pre-trained image decoder from performing the standard image reconstruction to joint decoding and denoising. Our scheme adopts a two-pronged approach. It features a latent refinement module to refine the latent representation of a noisy input image for reconstructing a noise-free image. Additionally, it incorporates an instance-specific prompt generator that adapts the decoding process to improve on the latent refinement. Experimental results show that our method achieves a similar level of denoising quality to training a separate decoder for joint decoding and denoising at the expense of only a modest increase in the decoder's model size and computational complexity.
LiDAR Depth Map Guided Image Compression Model
Jan 12, 2024

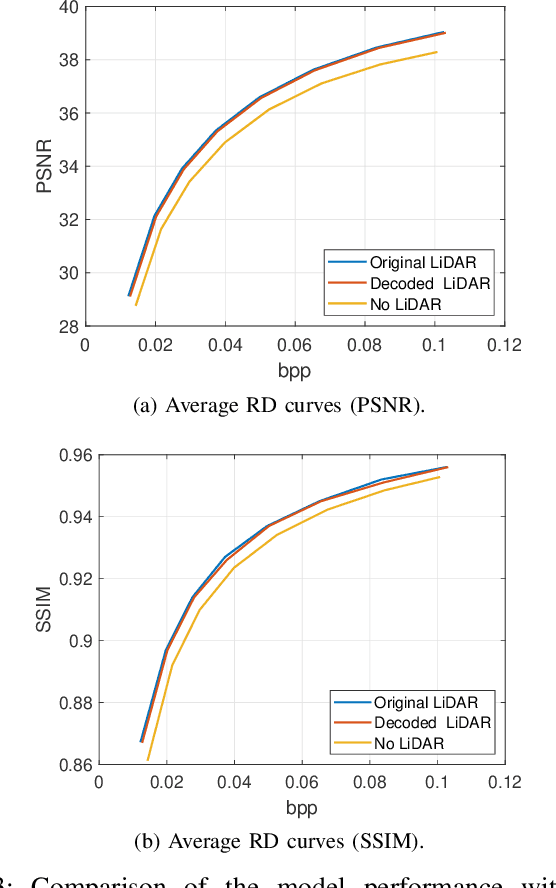

The incorporation of LiDAR technology into some high-end smartphones has unlocked numerous possibilities across various applications, including photography, image restoration, augmented reality, and more. In this paper, we introduce a novel direction that harnesses LiDAR depth maps to enhance the compression of the corresponding RGB camera images. Specifically, we propose a Transformer-based learned image compression system capable of achieving variable-rate compression using a single model while utilizing the LiDAR depth map as supplementary information for both the encoding and decoding processes. Experimental results demonstrate that integrating LiDAR yields an average PSNR gain of 0.83 dB and an average bitrate reduction of 16% as compared to its absence.
CANF-VC: Conditional Augmented Normalizing Flows for Video Compression
Jul 18, 2022
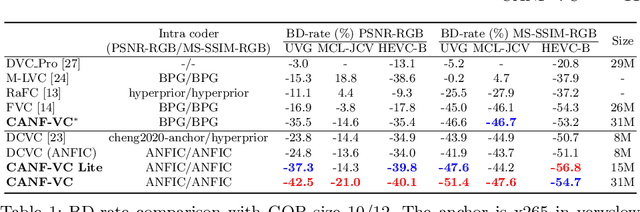

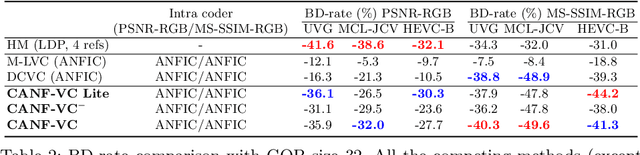
This paper presents an end-to-end learning-based video compression system, termed CANF-VC, based on conditional augmented normalizing flows (CANF). Most learned video compression systems adopt the same hybrid-based coding architecture as the traditional codecs. Recent research on conditional coding has shown the sub-optimality of the hybrid-based coding and opens up opportunities for deep generative models to take a key role in creating new coding frameworks. CANF-VC represents a new attempt that leverages the conditional ANF to learn a video generative model for conditional inter-frame coding. We choose ANF because it is a special type of generative model, which includes variational autoencoder as a special case and is able to achieve better expressiveness. CANF-VC also extends the idea of conditional coding to motion coding, forming a purely conditional coding framework. Extensive experimental results on commonly used datasets confirm the superiority of CANF-VC to the state-of-the-art methods. The source code of CANF-VC is available at https://github.com/NYCU-MAPL/CANF-VC.