 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMH-LVC: Multi-Hypothesis Temporal Prediction for Learned Conditional Residual Video Coding
Oct 14, 2025This work, termed MH-LVC, presents a multi-hypothesis temporal prediction scheme that employs long- and short-term reference frames in a conditional residual video coding framework. Recent temporal context mining approaches to conditional video coding offer superior coding performance. However, the need to store and access a large amount of implicit contextual information extracted from past decoded frames in decoding a video frame poses a challenge due to excessive memory access. Our MH-LVC overcomes this issue by storing multiple long- and short-term reference frames but limiting the number of reference frames used at a time for temporal prediction to two. Our decoded frame buffer management allows the encoder to flexibly utilize the long-term key frames to mitigate temporal cascading errors and the short-term reference frames to minimize prediction errors. Moreover, our buffering scheme enables the temporal prediction structure to be adapted to individual input videos. While this flexibility is common in traditional video codecs, it has not been fully explored for learned video codecs. Extensive experiments show that the proposed method outperforms VTM-17.0 under the low-delay B configuration in terms of PSNR-RGB across commonly used test datasets, and performs comparably to the state-of-the-art learned codecs (e.g.~DCVC-FM) while requiring less decoded frame buffer and similar decoding time.
On the Rate-Distortion-Complexity Trade-offs of Neural Video Coding
Oct 04, 2024



This paper aims to delve into the rate-distortion-complexity trade-offs of modern neural video coding. Recent years have witnessed much research effort being focused on exploring the full potential of neural video coding. Conditional autoencoders have emerged as the mainstream approach to efficient neural video coding. The central theme of conditional autoencoders is to leverage both spatial and temporal information for better conditional coding. However, a recent study indicates that conditional coding may suffer from information bottlenecks, potentially performing worse than traditional residual coding. To address this issue, recent conditional coding methods incorporate a large number of high-resolution features as the condition signal, leading to a considerable increase in the number of multiply-accumulate operations, memory footprint, and model size. Taking DCVC as the common code base, we investigate how the newly proposed conditional residual coding, an emerging new school of thought, and its variants may strike a better balance among rate, distortion, and complexity.
ComNeck: Bridging Compressed Image Latents and Multimodal LLMs via Universal Transform-Neck
Jul 29, 2024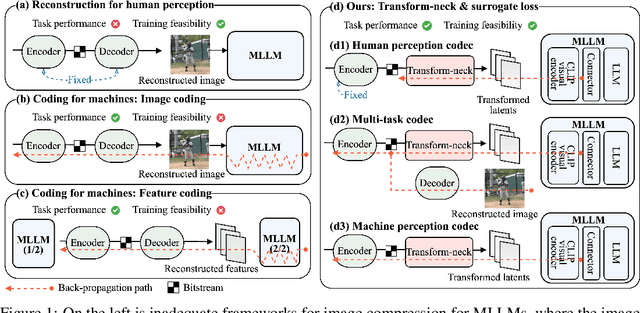

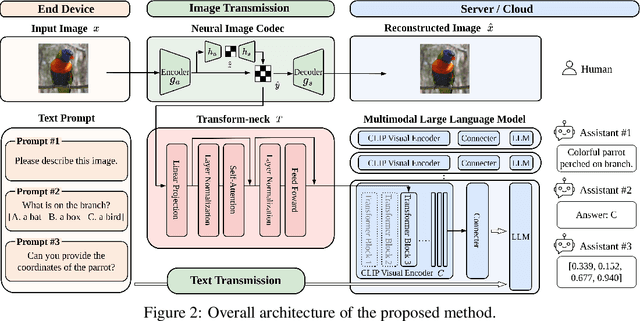
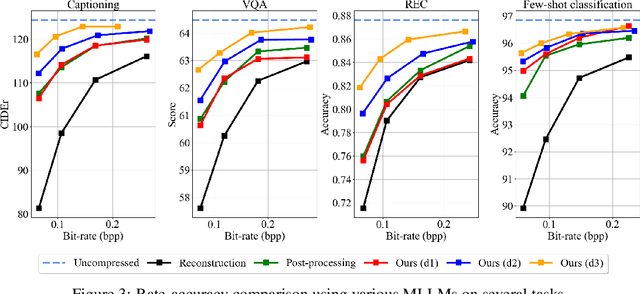
This paper presents the first-ever study of adapting compressed image latents to suit the needs of downstream vision tasks that adopt Multimodal Large Language Models (MLLMs). MLLMs have extended the success of large language models to modalities (e.g. images) beyond text, but their billion scale hinders deployment on resource-constrained end devices. While cloud-hosted MLLMs could be available, transmitting raw, uncompressed images captured by end devices to the cloud requires an efficient image compression system. To address this, we focus on emerging neural image compression and propose a novel framework with a lightweight transform-neck and a surrogate loss to adapt compressed image latents for MLLM-based vision tasks. The proposed framework is generic and applicable to multiple application scenarios, where the neural image codec can be (1) pre-trained for human perception without updating, (2) fully updated for joint human and machine perception, or (3) fully updated for only machine perception. The transform-neck trained with the surrogate loss is universal, for it can serve various downstream vision tasks enabled by a variety of MLLMs that share the same visual encoder. Our framework has the striking feature of excluding the downstream MLLMs from training the transform-neck, and potentially the neural image codec as well. This stands out from most existing coding for machine approaches that involve downstream networks in training and thus could be impractical when the networks are MLLMs. Extensive experiments on different neural image codecs and various MLLM-based vision tasks show that our method achieves great rate-accuracy performance with much less complexity, demonstrating its effectiveness.
Transformer-based Learned Image Compression for Joint Decoding and Denoising
Feb 20, 2024



This work introduces a Transformer-based image compression system. It has the flexibility to switch between the standard image reconstruction and the denoising reconstruction from a single compressed bitstream. Instead of training separate decoders for these tasks, we incorporate two add-on modules to adapt a pre-trained image decoder from performing the standard image reconstruction to joint decoding and denoising. Our scheme adopts a two-pronged approach. It features a latent refinement module to refine the latent representation of a noisy input image for reconstructing a noise-free image. Additionally, it incorporates an instance-specific prompt generator that adapts the decoding process to improve on the latent refinement. Experimental results show that our method achieves a similar level of denoising quality to training a separate decoder for joint decoding and denoising at the expense of only a modest increase in the decoder's model size and computational complexity.
LiDAR Depth Map Guided Image Compression Model
Jan 12, 2024

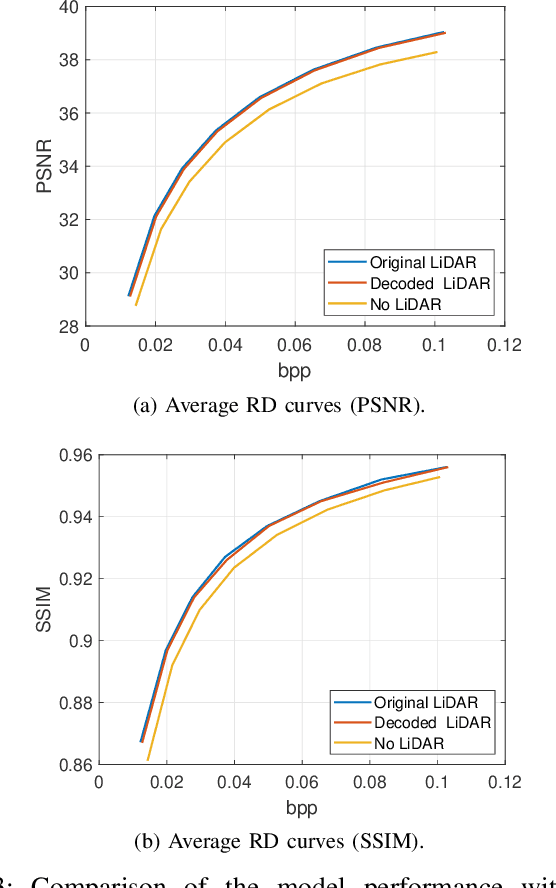

The incorporation of LiDAR technology into some high-end smartphones has unlocked numerous possibilities across various applications, including photography, image restoration, augmented reality, and more. In this paper, we introduce a novel direction that harnesses LiDAR depth maps to enhance the compression of the corresponding RGB camera images. Specifically, we propose a Transformer-based learned image compression system capable of achieving variable-rate compression using a single model while utilizing the LiDAR depth map as supplementary information for both the encoding and decoding processes. Experimental results demonstrate that integrating LiDAR yields an average PSNR gain of 0.83 dB and an average bitrate reduction of 16% as compared to its absence.
MaskCRT: Masked Conditional Residual Transformer for Learned Video Compression
Dec 25, 2023Conditional coding has lately emerged as the mainstream approach to learned video compression. However, a recent study shows that it may perform worse than residual coding when the information bottleneck arises. Conditional residual coding was thus proposed, creating a new school of thought to improve on conditional coding. Notably, conditional residual coding relies heavily on the assumption that the residual frame has a lower entropy rate than that of the intra frame. Recognizing that this assumption is not always true due to dis-occlusion phenomena or unreliable motion estimates, we propose a masked conditional residual coding scheme. It learns a soft mask to form a hybrid of conditional coding and conditional residual coding in a pixel adaptive manner. We introduce a Transformer-based conditional autoencoder. Several strategies are investigated with regard to how to condition a Transformer-based autoencoder for inter-frame coding, a topic that is largely under-explored. Additionally, we propose a channel transform module (CTM) to decorrelate the image latents along the channel dimension, with the aim of using the simple hyperprior to approach similar compression performance to the channel-wise autoregressive model. Experimental results confirm the superiority of our masked conditional residual transformer (termed MaskCRT) to both conditional coding and conditional residual coding. On commonly used datasets, MaskCRT shows comparable BD-rate results to VTM-17.0 under the low delay P configuration in terms of PSNR-RGB. It also opens up a new research direction for advancing learned video compression.
Transformer-based Image Compression with Variable Image Quality Objectives
Sep 22, 2023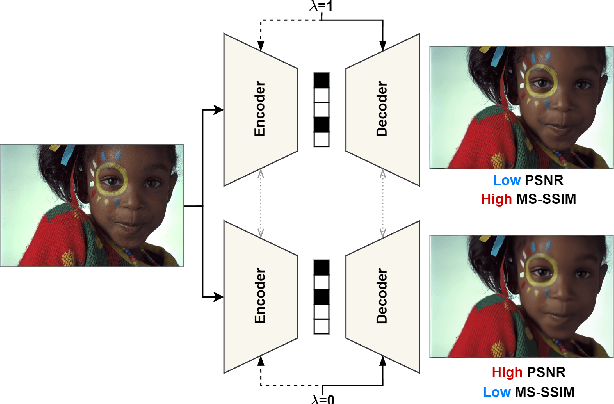
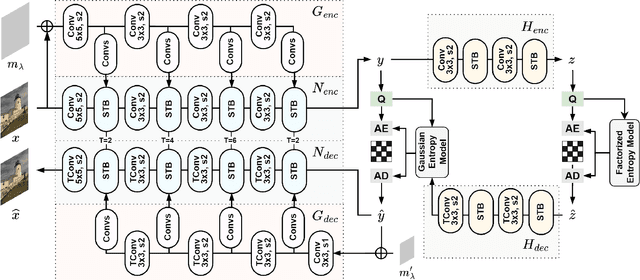
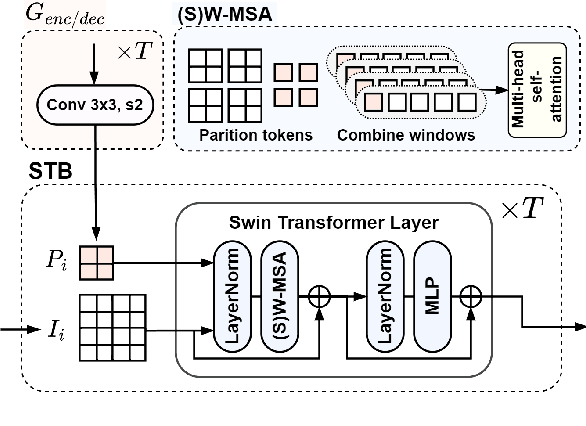
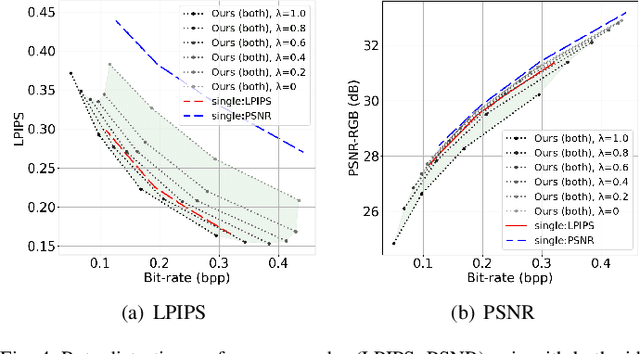
This paper presents a Transformer-based image compression system that allows for a variable image quality objective according to the user's preference. Optimizing a learned codec for different quality objectives leads to reconstructed images with varying visual characteristics. Our method provides the user with the flexibility to choose a trade-off between two image quality objectives using a single, shared model. Motivated by the success of prompt-tuning techniques, we introduce prompt tokens to condition our Transformer-based autoencoder. These prompt tokens are generated adaptively based on the user's preference and input image through learning a prompt generation network. Extensive experiments on commonly used quality metrics demonstrate the effectiveness of our method in adapting the encoding and/or decoding processes to a variable quality objective. While offering the additional flexibility, our proposed method performs comparably to the single-objective methods in terms of rate-distortion performance.
MoTIF: Learning Motion Trajectories with Local Implicit Neural Functions for Continuous Space-Time Video Super-Resolution
Jul 16, 2023



This work addresses continuous space-time video super-resolution (C-STVSR) that aims to up-scale an input video both spatially and temporally by any scaling factors. One key challenge of C-STVSR is to propagate information temporally among the input video frames. To this end, we introduce a space-time local implicit neural function. It has the striking feature of learning forward motion for a continuum of pixels. We motivate the use of forward motion from the perspective of learning individual motion trajectories, as opposed to learning a mixture of motion trajectories with backward motion. To ease motion interpolation, we encode sparsely sampled forward motion extracted from the input video as the contextual input. Along with a reliability-aware splatting and decoding scheme, our framework, termed MoTIF, achieves the state-of-the-art performance on C-STVSR. The source code of MoTIF is available at https://github.com/sichun233746/MoTIF.
TransTIC: Transferring Transformer-based Image Compression from Human Visualization to Machine Perception
Jun 08, 2023

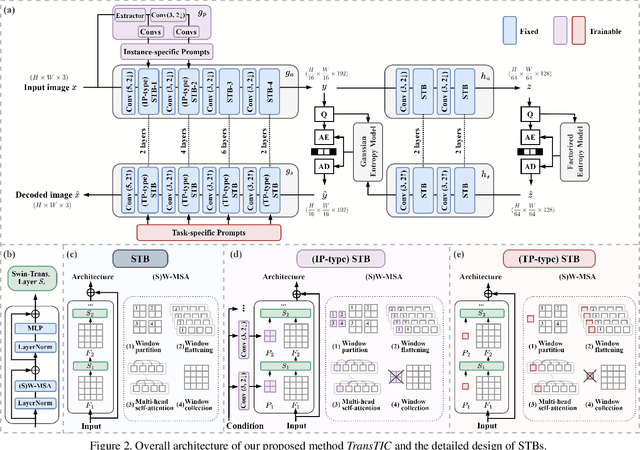
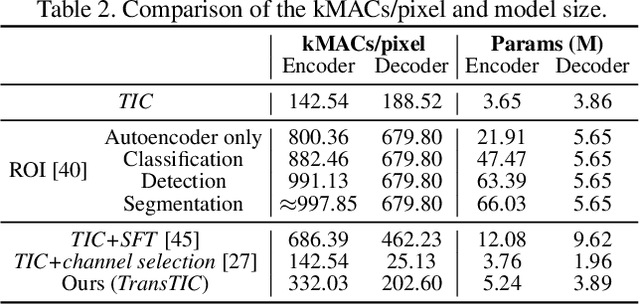
This work aims for transferring a Transformer-based image compression codec from human vision to machine perception without fine-tuning the codec. We propose a transferable Transformer-based image compression framework, termed TransTIC. Inspired by visual prompt tuning, we propose an instance-specific prompt generator to inject instance-specific prompts to the encoder and task-specific prompts to the decoder. Extensive experiments show that our proposed method is capable of transferring the codec to various machine tasks and outshining the competing methods significantly. To our best knowledge, this work is the first attempt to utilize prompting on the low-level image compression task.
Transformer-based Variable-rate Image Compression with Region-of-interest Control
May 18, 2023This paper proposes a transformer-based learned image compression system. It is capable of achieving variable-rate compression with a single model while supporting the region-of-interest (ROI) functionality. Inspired by prompt tuning, we introduce prompt generation networks to condition the transformer-based autoencoder of compression. Our prompt generation networks generate content-adaptive tokens according to the input image, an ROI mask, and a rate parameter. The separation of the ROI mask and the rate parameter allows an intuitive way to achieve variable-rate and ROI coding simultaneously. Extensive experiments validate the effectiveness of our proposed method and confirm its superiority over the other competing methods.