 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset for Automatic Vocal Mode Classification
Jan 26, 2026The Complete Vocal Technique (CVT) is a school of singing developed in the past decades by Cathrin Sadolin et al.. CVT groups the use of the voice into so called vocal modes, namely Neutral, Curbing, Overdrive and Edge. Knowledge of the desired vocal mode can be helpful for singing students. Automatic classification of vocal modes can thus be important for technology-assisted singing teaching. Previously, automatic classification of vocal modes has been attempted without major success, potentially due to a lack of data. Therefore, we recorded a novel vocal mode dataset consisting of sustained vowels recorded from four singers, three of which professional singers with more than five years of CVT-experience. The dataset covers the entire vocal range of the subjects, totaling 3,752 unique samples. By using four microphones, thereby offering a natural data augmentation, the dataset consists of more than 13,000 samples combined. An annotation was created using three CVT-experienced annotators, each providing an individual annotation. The merged annotation as well as the three individual annotations come with the published dataset. Additionally, we provide some baseline classification results. The best balanced accuracy across a 5-fold cross validation of 81.3\,\% was achieved with a ResNet18. The dataset can be downloaded under https://zenodo.org/records/14276415.
Comp-X: On Defining an Interactive Learned Image Compression Paradigm With Expert-driven LLM Agent
Aug 21, 2025We present Comp-X, the first intelligently interactive image compression paradigm empowered by the impressive reasoning capability of large language model (LLM) agent. Notably, commonly used image codecs usually suffer from limited coding modes and rely on manual mode selection by engineers, making them unfriendly for unprofessional users. To overcome this, we advance the evolution of image coding paradigm by introducing three key innovations: (i) multi-functional coding framework, which unifies different coding modes of various objective/requirements, including human-machine perception, variable coding, and spatial bit allocation, into one framework. (ii) interactive coding agent, where we propose an augmented in-context learning method with coding expert feedback to teach the LLM agent how to understand the coding request, mode selection, and the use of the coding tools. (iii) IIC-bench, the first dedicated benchmark comprising diverse user requests and the corresponding annotations from coding experts, which is systematically designed for intelligently interactive image compression evaluation. Extensive experimental results demonstrate that our proposed Comp-X can understand the coding requests efficiently and achieve impressive textual interaction capability. Meanwhile, it can maintain comparable compression performance even with a single coding framework, providing a promising avenue for artificial general intelligence (AGI) in image compression.
Pruning-aware Loss Functions for STOI-Optimized Pruned Recurrent Autoencoders for the Compression of the Stimulation Patterns of Cochlear Implants at Zero Delay
Feb 04, 2025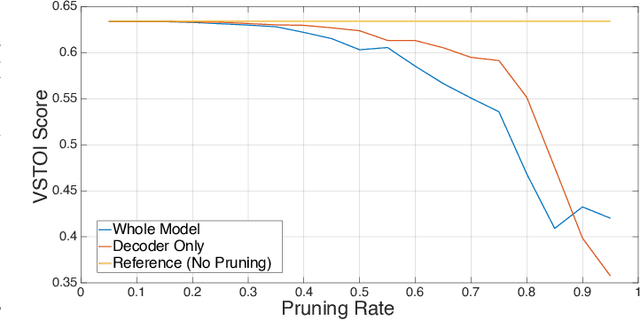
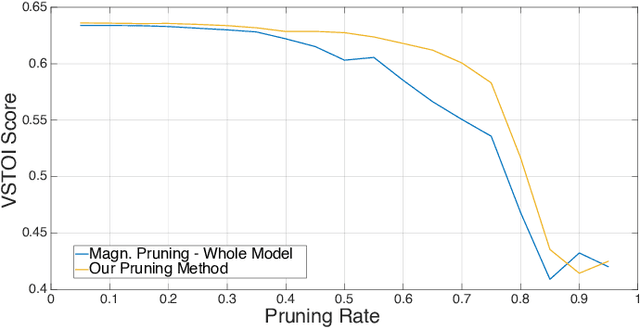
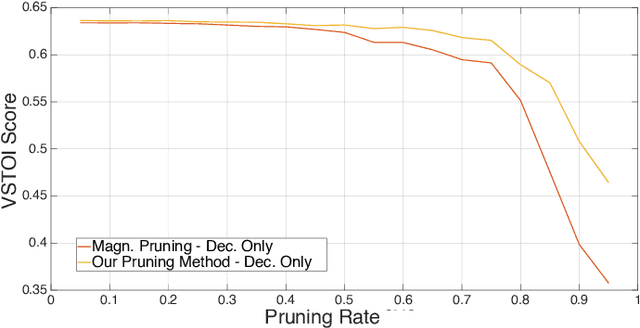
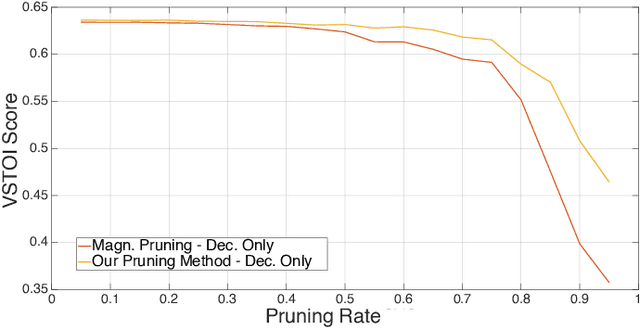
Cochlear implants (CIs) are surgically implanted hearing devices, which allow to restore a sense of hearing in people suffering from profound hearing loss. Wireless streaming of audio from external devices to CI signal processors has become common place. Specialized compression based on the stimulation patterns of a CI by deep recurrent autoencoders can decrease the power consumption in such a wireless streaming application through bit-rate reduction at zero latency. While previous research achieved considerable bit-rate reductions, model sizes were ignored, which can be of crucial importance in hearing-aids due to their limited computational resources. This work investigates maximizing objective speech intelligibility of the coded stimulation patterns of deep recurrent autoencoders while minimizing model size. For this purpose, a pruning-aware loss is proposed, which captures the impact of pruning during training. This training with a pruning-aware loss is compared to conventional magnitude-informed pruning and is found to yield considerable improvements in objective intelligibility, especially at higher pruning rates. After fine-tuning, little to no degradation of objective intelligibility is observed up to a pruning rate of about 55\,\%. The proposed pruning-aware loss yields substantial gains in objective speech intelligibility scores after pruning compared to the magnitude-informed baseline for pruning rates above 45\,\%.
* Preprint of Asilomar 2024 Paper
On the Rate-Distortion-Complexity Trade-offs of Neural Video Coding
Oct 04, 2024



This paper aims to delve into the rate-distortion-complexity trade-offs of modern neural video coding. Recent years have witnessed much research effort being focused on exploring the full potential of neural video coding. Conditional autoencoders have emerged as the mainstream approach to efficient neural video coding. The central theme of conditional autoencoders is to leverage both spatial and temporal information for better conditional coding. However, a recent study indicates that conditional coding may suffer from information bottlenecks, potentially performing worse than traditional residual coding. To address this issue, recent conditional coding methods incorporate a large number of high-resolution features as the condition signal, leading to a considerable increase in the number of multiply-accumulate operations, memory footprint, and model size. Taking DCVC as the common code base, we investigate how the newly proposed conditional residual coding, an emerging new school of thought, and its variants may strike a better balance among rate, distortion, and complexity.
MaskCRT: Masked Conditional Residual Transformer for Learned Video Compression
Dec 25, 2023Conditional coding has lately emerged as the mainstream approach to learned video compression. However, a recent study shows that it may perform worse than residual coding when the information bottleneck arises. Conditional residual coding was thus proposed, creating a new school of thought to improve on conditional coding. Notably, conditional residual coding relies heavily on the assumption that the residual frame has a lower entropy rate than that of the intra frame. Recognizing that this assumption is not always true due to dis-occlusion phenomena or unreliable motion estimates, we propose a masked conditional residual coding scheme. It learns a soft mask to form a hybrid of conditional coding and conditional residual coding in a pixel adaptive manner. We introduce a Transformer-based conditional autoencoder. Several strategies are investigated with regard to how to condition a Transformer-based autoencoder for inter-frame coding, a topic that is largely under-explored. Additionally, we propose a channel transform module (CTM) to decorrelate the image latents along the channel dimension, with the aim of using the simple hyperprior to approach similar compression performance to the channel-wise autoregressive model. Experimental results confirm the superiority of our masked conditional residual transformer (termed MaskCRT) to both conditional coding and conditional residual coding. On commonly used datasets, MaskCRT shows comparable BD-rate results to VTM-17.0 under the low delay P configuration in terms of PSNR-RGB. It also opens up a new research direction for advancing learned video compression.
SegForestNet: Spatial-Partitioning-Based Aerial Image Segmentation
Feb 03, 2023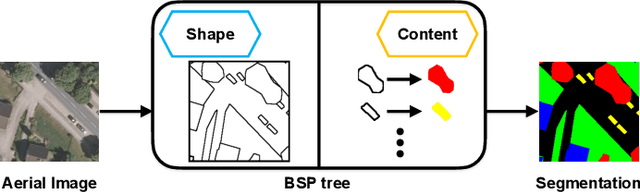

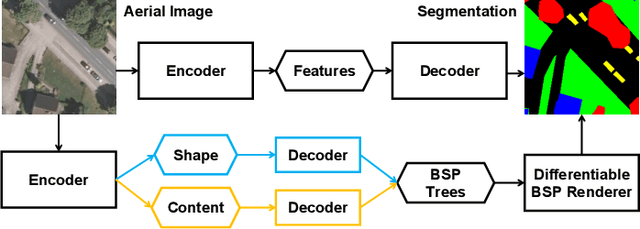
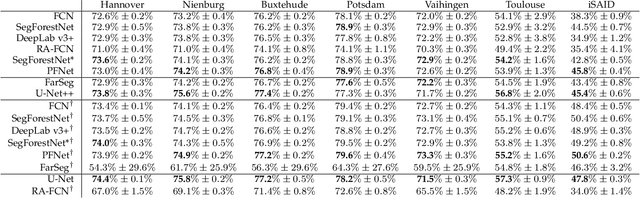
Aerial image analysis, specifically the semantic segmentation thereof, is the basis for applications such as automatically creating and updating maps, tracking city growth, or tracking deforestation. In true orthophotos, which are often used in these applications, many objects and regions can be approximated well by polygons. However, this fact is rarely exploited by state-of-the-art semantic segmentation models. Instead, most models allow unnecessary degrees of freedom in their predictions by allowing arbitrary region shapes. We therefore present a refinement of our deep learning model which predicts binary space partitioning trees, an efficient polygon representation. The refinements include a new feature decoder architecture and a new differentiable BSP tree renderer which both avoid vanishing gradients. Additionally, we designed a novel loss function specifically designed to improve the spatial partitioning defined by the predicted trees. Furthermore, our expanded model can predict multiple trees at once and thus can predict class-specific segmentations. Taking all modifications together, our model achieves state-of-the-art performance while using up to 60% fewer model parameters when using a small backbone model or up to 20% fewer model parameters when using a large backbone model.
Two-Stream Aural-Visual Affect Analysis in the Wild
Mar 03, 2020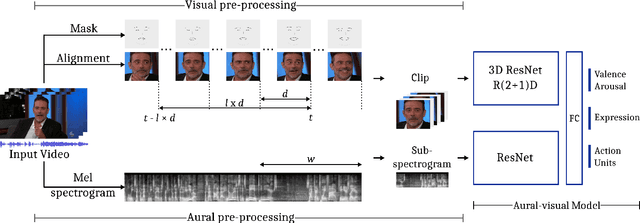
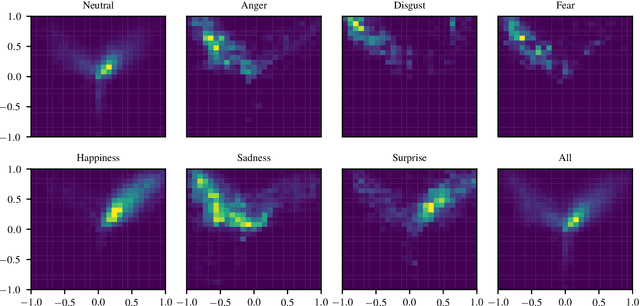

Human affect recognition is an essential part of natural human-computer interaction. However, current methods are still in their infancy, especially for in-the-wild data. In this work, we introduce our submission to the Affective Behavior Analysis in-the-wild (ABAW) 2020 competition. We propose a two-stream aural-visual analysis model to recognize affective behavior from videos. Audio and image streams are first processed separately and fed into a convolutional neural network. Instead of applying recurrent architectures for temporal analysis we only use temporal convolutions. Furthermore, the model is given access to additional features extracted during face-alignment. At training time, we exploit correlations between different emotion representations to improve performance. Our model achieves promising results on the challenging Aff-Wild2 database.
HEVC Inter Coding Using Deep Recurrent Neural Networks and Artificial Reference Pictures
Dec 05, 2018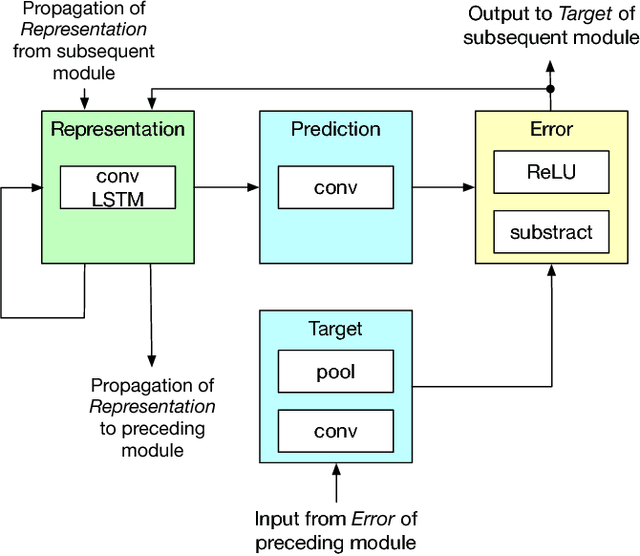
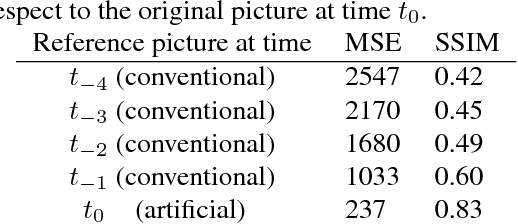
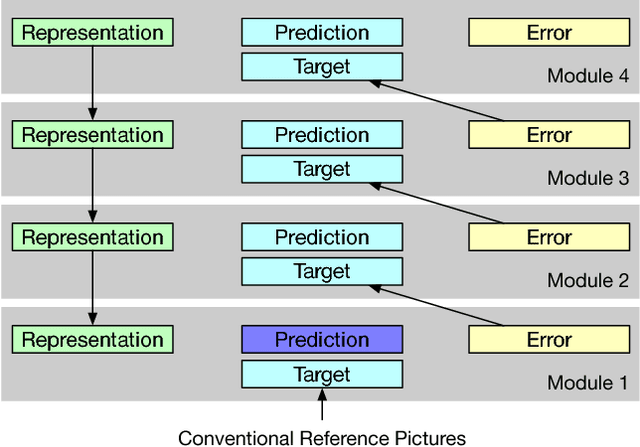
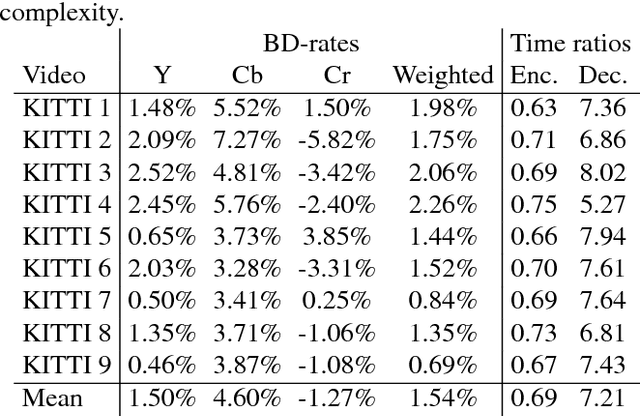
The efficiency of motion compensated prediction in modern video codecs highly depends on the available reference pictures. Occlusions and non-linear motion pose challenges for the motion compensation and often result in high bit rates for the prediction error. We propose the generation of artificial reference pictures using deep recurrent neural networks. Conceptually, a reference picture at the time instance of the currently coded picture is generated from previously reconstructed conventional reference pictures. Based on these artificial reference pictures, we propose a complete coding pipeline based on HEVC. By using the artificial reference pictures for motion compensated prediction, average BD-rate gains of 1.5% over HEVC are achieved.
Neural Network Compression using Transform Coding and Clustering
May 18, 2018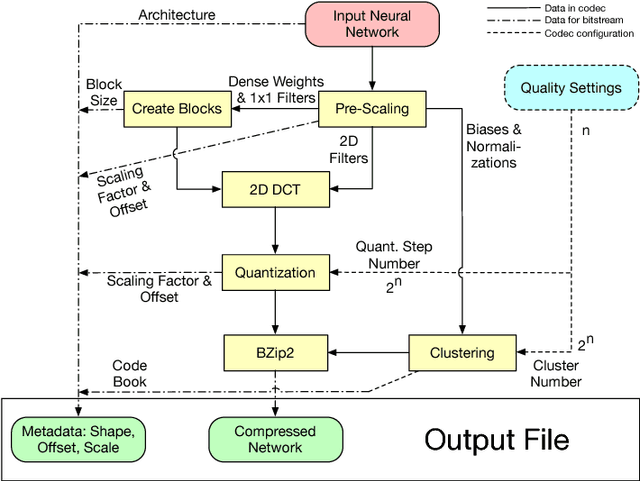
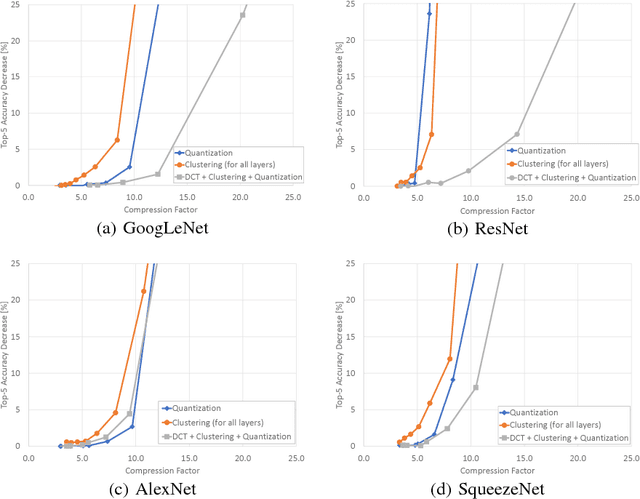
With the deployment of neural networks on mobile devices and the necessity of transmitting neural networks over limited or expensive channels, the file size of the trained model was identified as bottleneck. In this paper, we propose a codec for the compression of neural networks which is based on transform coding for convolutional and dense layers and on clustering for biases and normalizations. By using this codec, we achieve average compression factors between 7.9-9.3 while the accuracy of the compressed networks for image classification decreases only by 1%-2%, respectively.
Unsupervised Features for Facial Expression Intensity Estimation over Time
May 03, 2018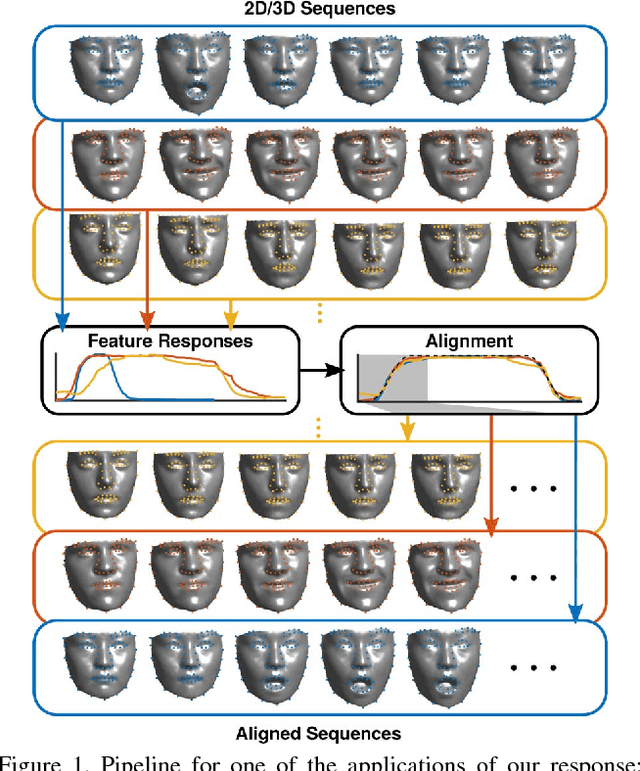
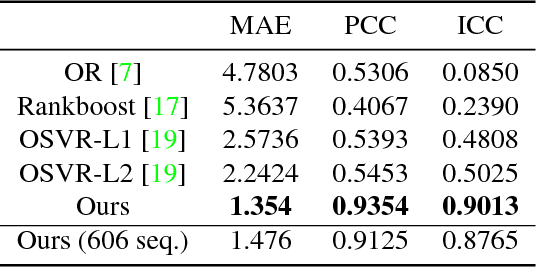
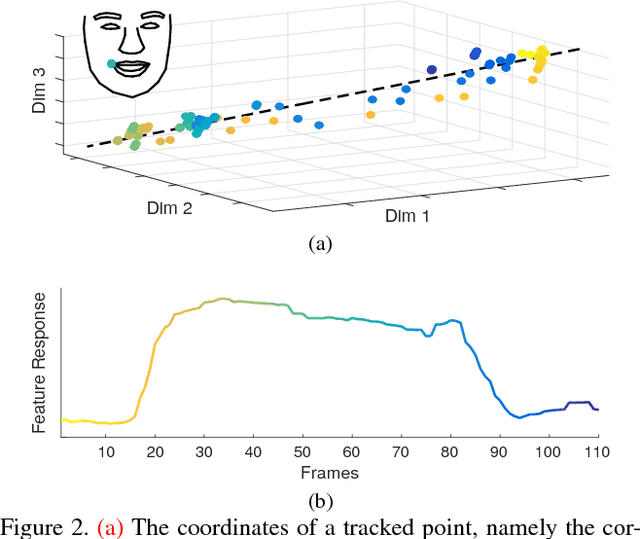
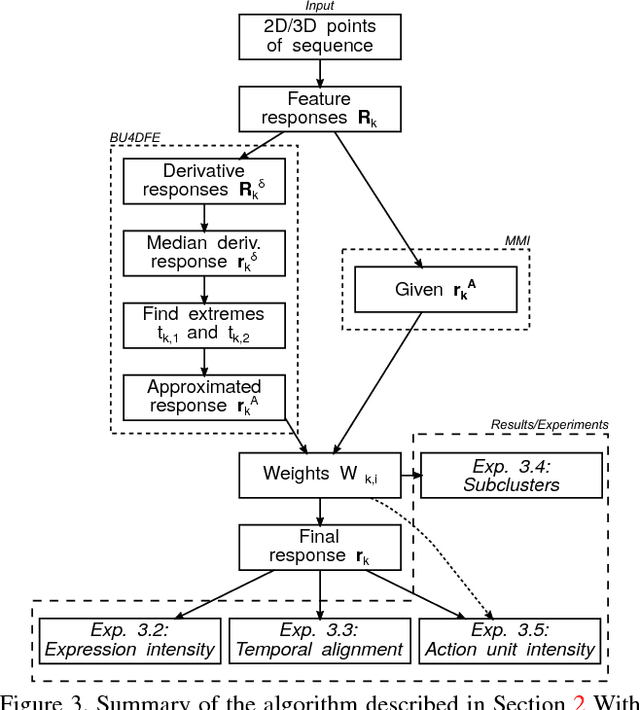
The diversity of facial shapes and motions among persons is one of the greatest challenges for automatic analysis of facial expressions. In this paper, we propose a feature describing expression intensity over time, while being invariant to person and the type of performed expression. Our feature is a weighted combination of the dynamics of multiple points adapted to the overall expression trajectory. We evaluate our method on several tasks all related to temporal analysis of facial expression. The proposed feature is compared to a state-of-the-art method for expression intensity estimation, which it outperforms. We use our proposed feature to temporally align multiple sequences of recorded 3D facial expressions. Furthermore, we show how our feature can be used to reveal person-specific differences in performances of facial expressions. Additionally, we apply our feature to identify the local changes in face video sequences based on action unit labels. For all the experiments our feature proves to be robust against noise and outliers, making it applicable to a variety of applications for analysis of facial movements.