 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld-GAN: a Generative Model for Minecraft Worlds
Jun 18, 2021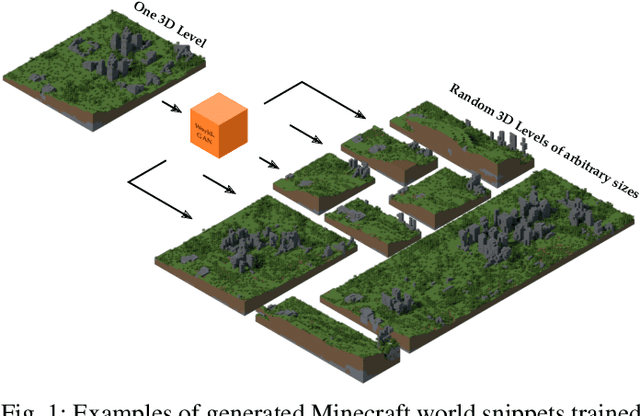
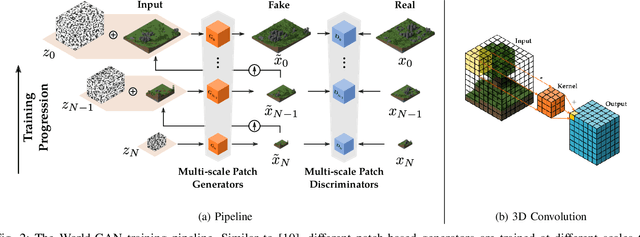
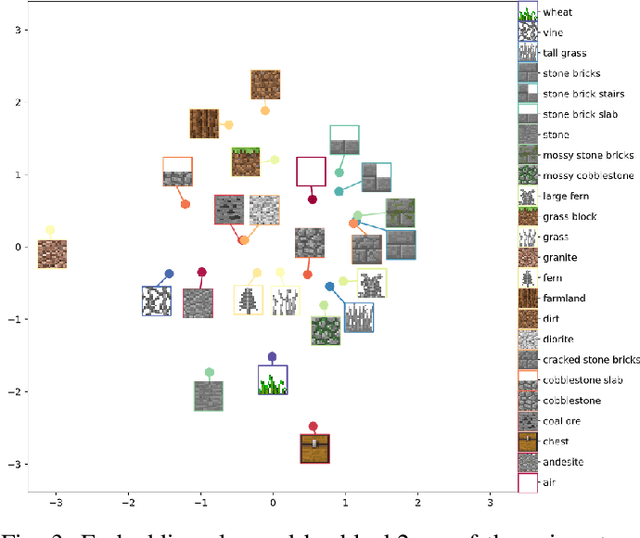
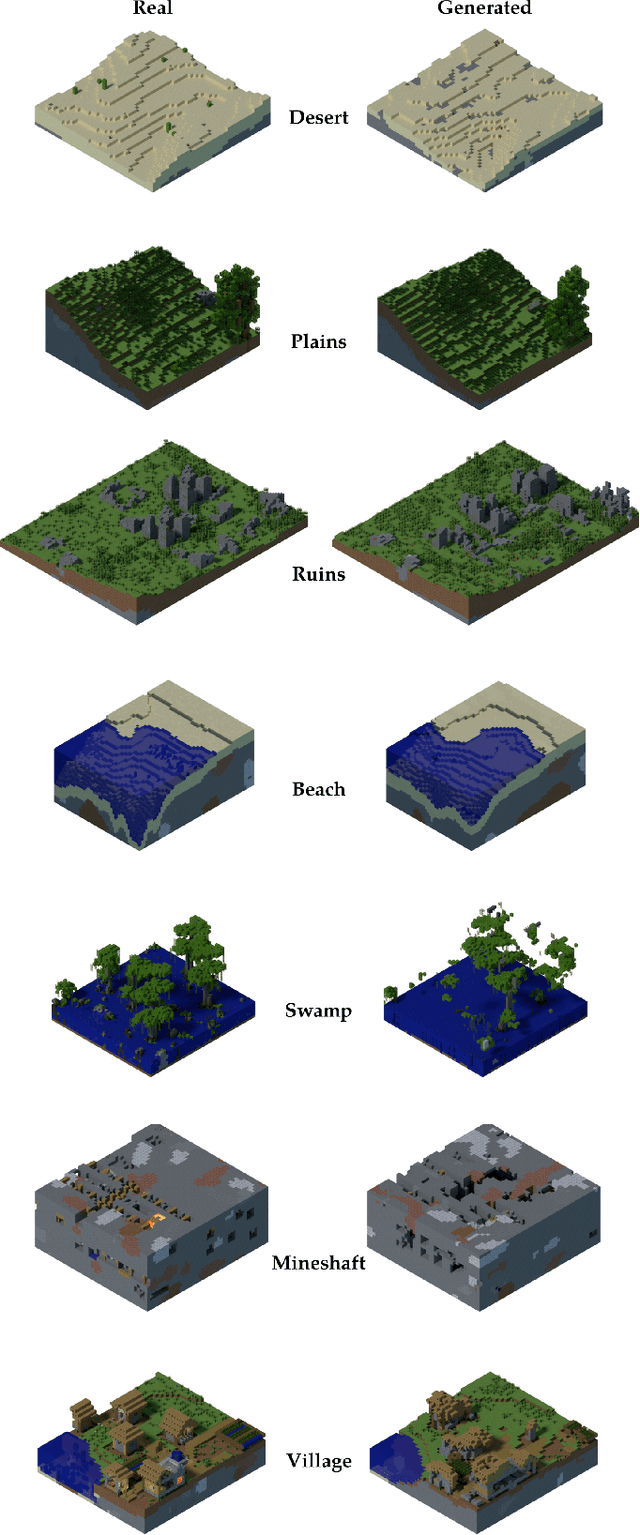
This work introduces World-GAN, the first method to perform data-driven Procedural Content Generation via Machine Learning in Minecraft from a single example. Based on a 3D Generative Adversarial Network (GAN) architecture, we are able to create arbitrarily sized world snippets from a given sample. We evaluate our approach on creations from the community as well as structures generated with the Minecraft World Generator. Our method is motivated by the dense representations used in Natural Language Processing (NLP) introduced with word2vec [1]. The proposed block2vec representations make World-GAN independent from the number of different blocks, which can vary a lot in Minecraft, and enable the generation of larger levels. Finally, we demonstrate that changing this new representation space allows us to change the generated style of an already trained generator. World-GAN enables its users to generate Minecraft worlds based on parts of their creations.
TOAD-GAN: Coherent Style Level Generation from a Single Example
Aug 04, 2020



In this work, we present TOAD-GAN (Token-based One-shot Arbitrary Dimension Generative Adversarial Network), a novel Procedural Content Generation (PCG) algorithm that generates token-based video game levels. TOAD-GAN follows the SinGAN architecture and can be trained using only one example. We demonstrate its application for Super Mario Bros. levels and are able to generate new levels of similar style in arbitrary sizes. We achieve state-of-the-art results in modeling the patterns of the training level and provide a comparison with different baselines under several metrics. Additionally, we present an extension of the method that allows the user to control the generation process of certain token structures to ensure a coherent global level layout. We provide this tool to the community to spur further research by publishing our source code.
Learning Disentangled Representations via Independent Subspaces
Aug 26, 2019



Image generating neural networks are mostly viewed as black boxes, where any change in the input can have a number of globally effective changes on the output. In this work, we propose a method for learning disentangled representations to allow for localized image manipulations. We use face images as our example of choice. Depending on the image region, identity and other facial attributes can be modified. The proposed network can transfer parts of a face such as shape and color of eyes, hair, mouth, etc.~directly between persons while all other parts of the face remain unchanged. The network allows to generate modified images which appear like realistic images. Our model learns disentangled representations by weak supervision. We propose a localized resnet autoencoder optimized using several loss functions including a loss based on the semantic segmentation, which we interpret as masks, and a loss which enforces disentanglement by decomposition of the latent space into statistically independent subspaces. We evaluate the proposed solution w.r.t. disentanglement and generated image quality. Convincing results are demonstrated using the CelebA dataset.
Unsupervised Features for Facial Expression Intensity Estimation over Time
May 03, 2018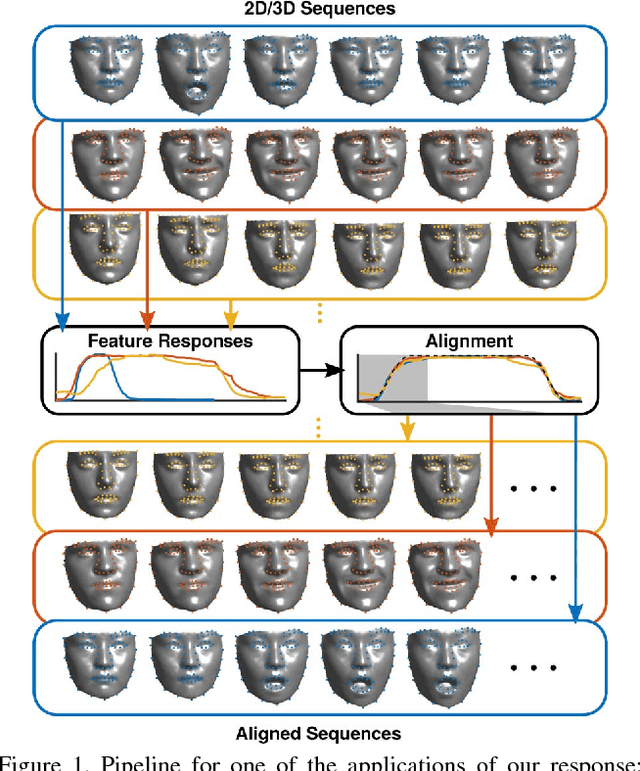
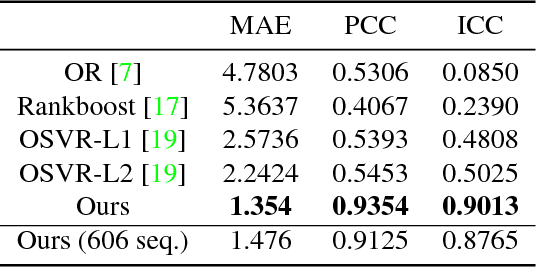
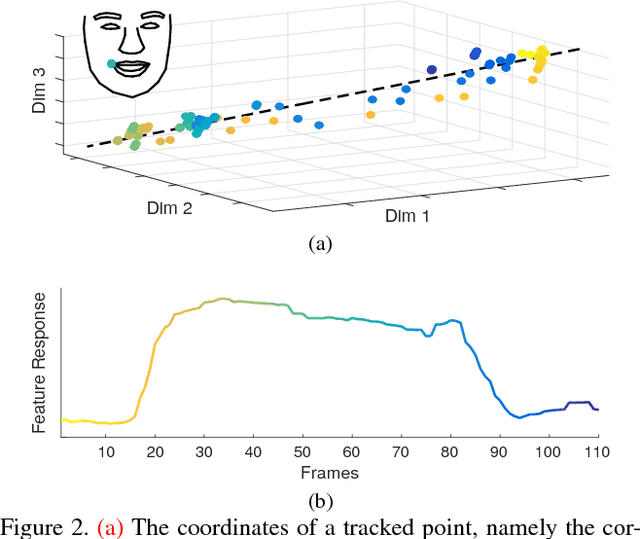
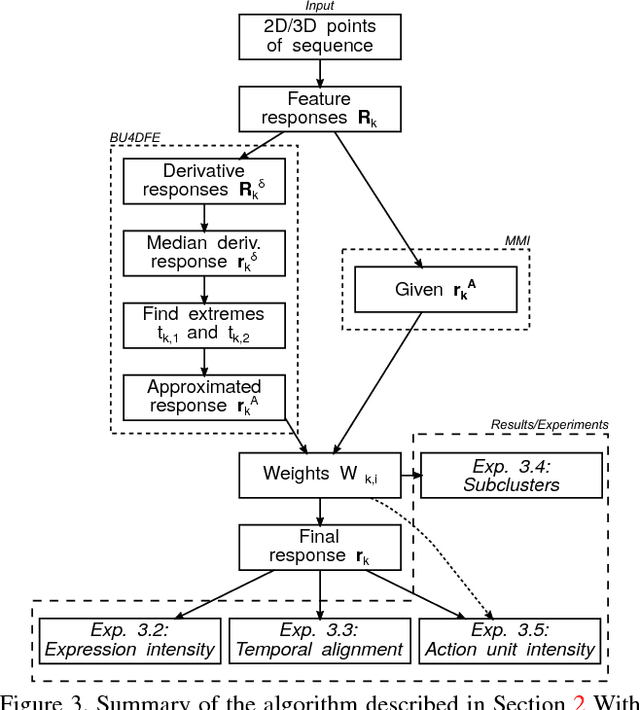
The diversity of facial shapes and motions among persons is one of the greatest challenges for automatic analysis of facial expressions. In this paper, we propose a feature describing expression intensity over time, while being invariant to person and the type of performed expression. Our feature is a weighted combination of the dynamics of multiple points adapted to the overall expression trajectory. We evaluate our method on several tasks all related to temporal analysis of facial expression. The proposed feature is compared to a state-of-the-art method for expression intensity estimation, which it outperforms. We use our proposed feature to temporally align multiple sequences of recorded 3D facial expressions. Furthermore, we show how our feature can be used to reveal person-specific differences in performances of facial expressions. Additionally, we apply our feature to identify the local changes in face video sequences based on action unit labels. For all the experiments our feature proves to be robust against noise and outliers, making it applicable to a variety of applications for analysis of facial movements.
Markov Chain Neural Networks
May 02, 2018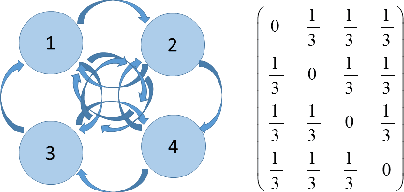

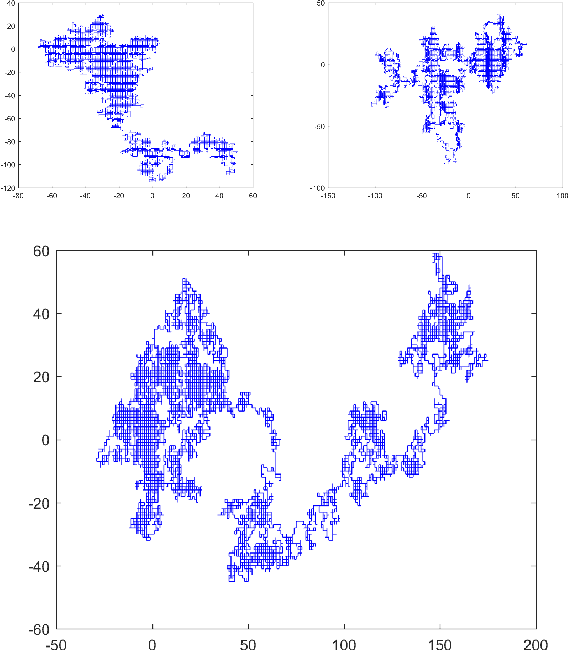
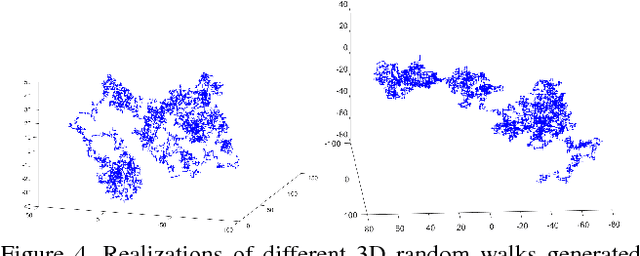
In this work we present a modified neural network model which is capable to simulate Markov Chains. We show how to express and train such a network, how to ensure given statistical properties reflected in the training data and we demonstrate several applications where the network produces non-deterministic outcomes. One example is a random walker model, e.g. useful for simulation of Brownian motions or a natural Tic-Tac-Toe network which ensures non-deterministic game behavior.