 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHydraMix: Multi-Image Feature Mixing for Small Data Image Classification
Jan 16, 2025



Training deep neural networks requires datasets with a large number of annotated examples. The collection and annotation of these datasets is not only extremely expensive but also faces legal and privacy problems. These factors are a significant limitation for many real-world applications. To address this, we introduce HydraMix, a novel architecture that generates new image compositions by mixing multiple different images from the same class. HydraMix learns the fusion of the content of various images guided by a segmentation-based mixing mask in feature space and is optimized via a combination of unsupervised and adversarial training. Our data augmentation scheme allows the creation of models trained from scratch on very small datasets. We conduct extensive experiments on ciFAIR-10, STL-10, and ciFAIR-100. Additionally, we introduce a novel text-image metric to assess the generality of the augmented datasets. Our results show that HydraMix outperforms existing state-of-the-art methods for image classification on small datasets.
Mastering Zero-Shot Interactions in Cooperative and Competitive Simultaneous Games
Feb 05, 2024



The combination of self-play and planning has achieved great successes in sequential games, for instance in Chess and Go. However, adapting algorithms such as AlphaZero to simultaneous games poses a new challenge. In these games, missing information about concurrent actions of other agents is a limiting factor as they may select different Nash equilibria or do not play optimally at all. Thus, it is vital to model the behavior of the other agents when interacting with them in simultaneous games. To this end, we propose Albatross: AlphaZero for Learning Bounded-rational Agents and Temperature-based Response Optimization using Simulated Self-play. Albatross learns to play the novel equilibrium concept of a Smooth Best Response Logit Equilibrium (SBRLE), which enables cooperation and competition with agents of any playing strength. We perform an extensive evaluation of Albatross on a set of cooperative and competitive simultaneous perfect-information games. In contrast to AlphaZero, Albatross is able to exploit weak agents in the competitive game of Battlesnake. Additionally, it yields an improvement of 37.6% compared to previous state of the art in the cooperative Overcooked benchmark.
POLTER: Policy Trajectory Ensemble Regularization for Unsupervised Reinforcement Learning
May 23, 2022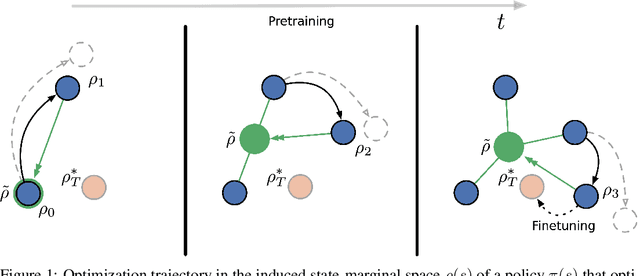

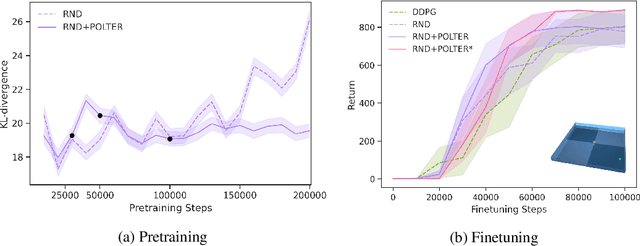
The goal of Unsupervised Reinforcement Learning (URL) is to find a reward-agnostic prior policy on a task domain, such that the sample-efficiency on supervised downstream tasks is improved. Although agents initialized with such a prior policy can achieve a significantly higher reward with fewer samples when finetuned on the downstream task, it is still an open question how an optimal pretrained prior policy can be achieved in practice. In this work, we present POLTER (Policy Trajectory Ensemble Regularization) - a general method to regularize the pretraining that can be applied to any URL algorithm and is especially useful on data- and knowledge-based URL algorithms. It utilizes an ensemble of policies that are discovered during pretraining and moves the policy of the URL algorithm closer to its optimal prior. Our method is theoretically justified, and we analyze its practical effects on a white-box benchmark, allowing us to study POLTER with full control. In our main experiments, we evaluate POLTER on the Unsupervised Reinforcement Learning Benchmark (URLB), which consists of 12 tasks in 3 domains. We demonstrate the generality of our approach by improving the performance of a diverse set of data- and knowledge-based URL algorithms by 19% on average and up to 40% in the best case. Under a fair comparison with tuned baselines and tuned POLTER, we establish a new the state-of-the-art on the URLB.
Image Classification on Small Datasets via Masked Feature Mixing
Feb 23, 2022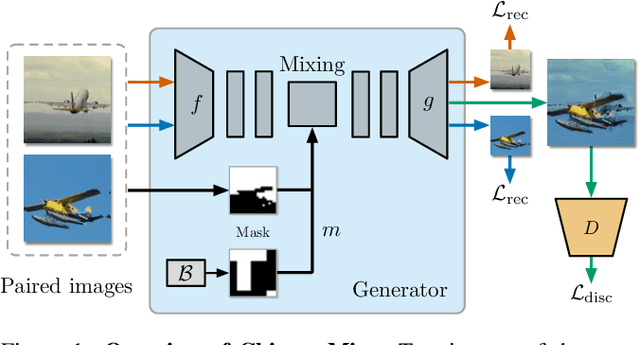
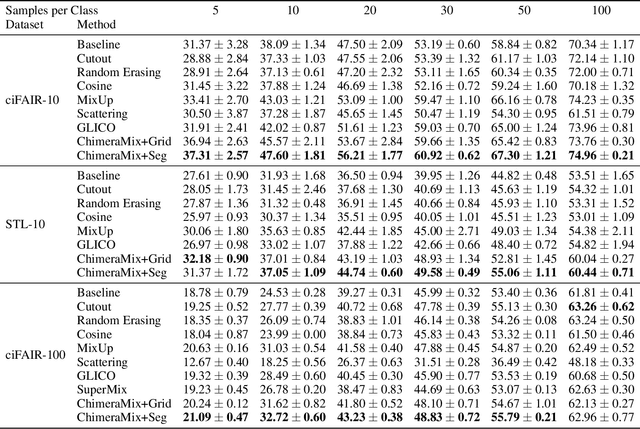

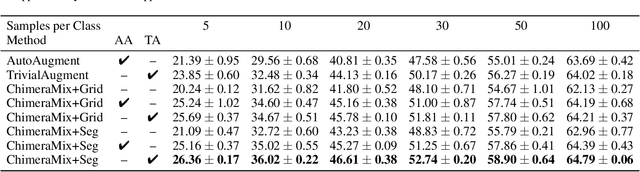
Deep convolutional neural networks require large amounts of labeled data samples. For many real-world applications, this is a major limitation which is commonly treated by augmentation methods. In this work, we address the problem of learning deep neural networks on small datasets. Our proposed architecture called ChimeraMix learns a data augmentation by generating compositions of instances. The generative model encodes images in pairs, combines the features guided by a mask, and creates new samples. For evaluation, all methods are trained from scratch without any additional data. Several experiments on benchmark datasets, e.g. ciFAIR-10, STL-10, and ciFAIR-100, demonstrate the superior performance of ChimeraMix compared to current state-of-the-art methods for classification on small datasets.
Contextualize Me -- The Case for Context in Reinforcement Learning
Feb 09, 2022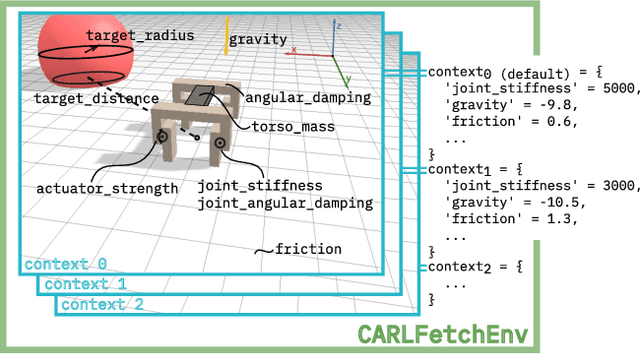
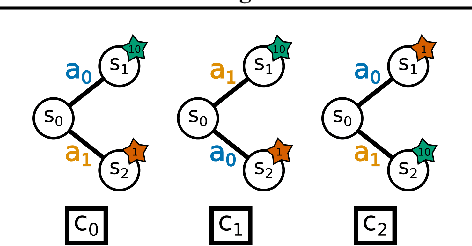
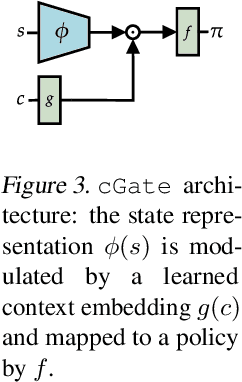
While Reinforcement Learning (RL) has made great strides towards solving increasingly complicated problems, many algorithms are still brittle to even slight changes in environments. Contextual Reinforcement Learning (cRL) provides a theoretical framework to model such changes in a principled manner, thereby enabling flexible, precise and interpretable task specification and generation. Thus, cRL is an important formalization for studying generalization in RL. In this work, we reason about solving cRL in theory and practice. We show that theoretically optimal behavior in contextual Markov Decision Processes requires explicit context information. In addition, we empirically explore context-based task generation, utilizing context information in training and propose cGate, our state-modulating policy architecture. To this end, we introduce the first benchmark library designed for generalization based on cRL extensions of popular benchmarks, CARL. In short: Context matters!
CARL: A Benchmark for Contextual and Adaptive Reinforcement Learning
Oct 11, 2021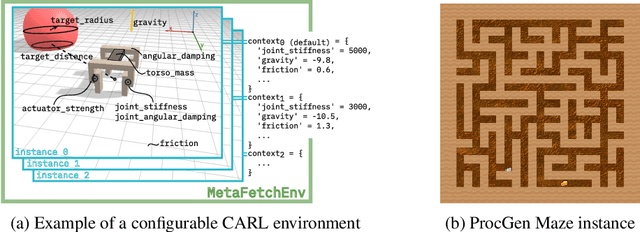
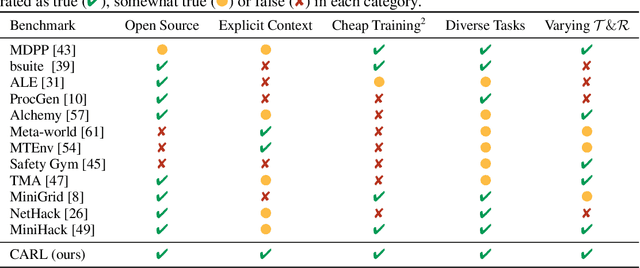
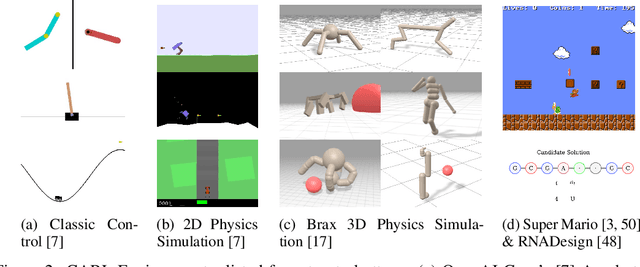

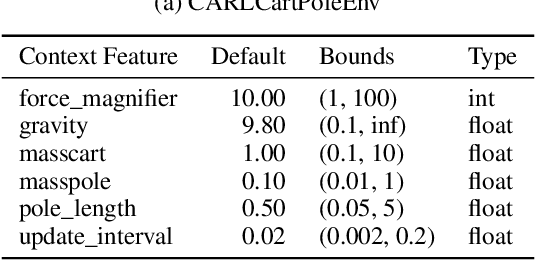
While Reinforcement Learning has made great strides towards solving ever more complicated tasks, many algorithms are still brittle to even slight changes in their environment. This is a limiting factor for real-world applications of RL. Although the research community continuously aims at improving both robustness and generalization of RL algorithms, unfortunately it still lacks an open-source set of well-defined benchmark problems based on a consistent theoretical framework, which allows comparing different approaches in a fair, reliable and reproducibleway. To fill this gap, we propose CARL, a collection of well-known RL environments extended to contextual RL problems to study generalization. We show the urgent need of such benchmarks by demonstrating that even simple toy environments become challenging for commonly used approaches if different contextual instances of this task have to be considered. Furthermore, CARL allows us to provide first evidence that disentangling representation learning of the states from the policy learning with the context facilitates better generalization. By providing variations of diverse benchmarks from classic control, physical simulations, games and a real-world application of RNA design, CARL will allow the community to derive many more such insights on a solid empirical foundation.
World-GAN: a Generative Model for Minecraft Worlds
Jun 18, 2021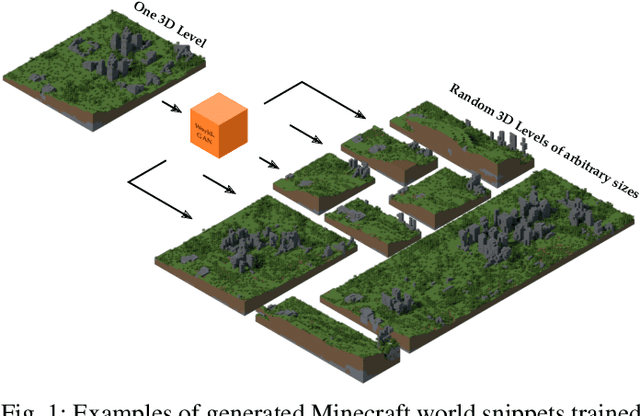
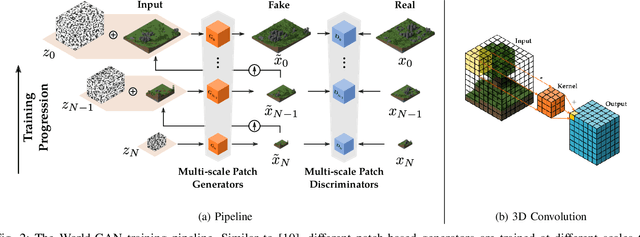
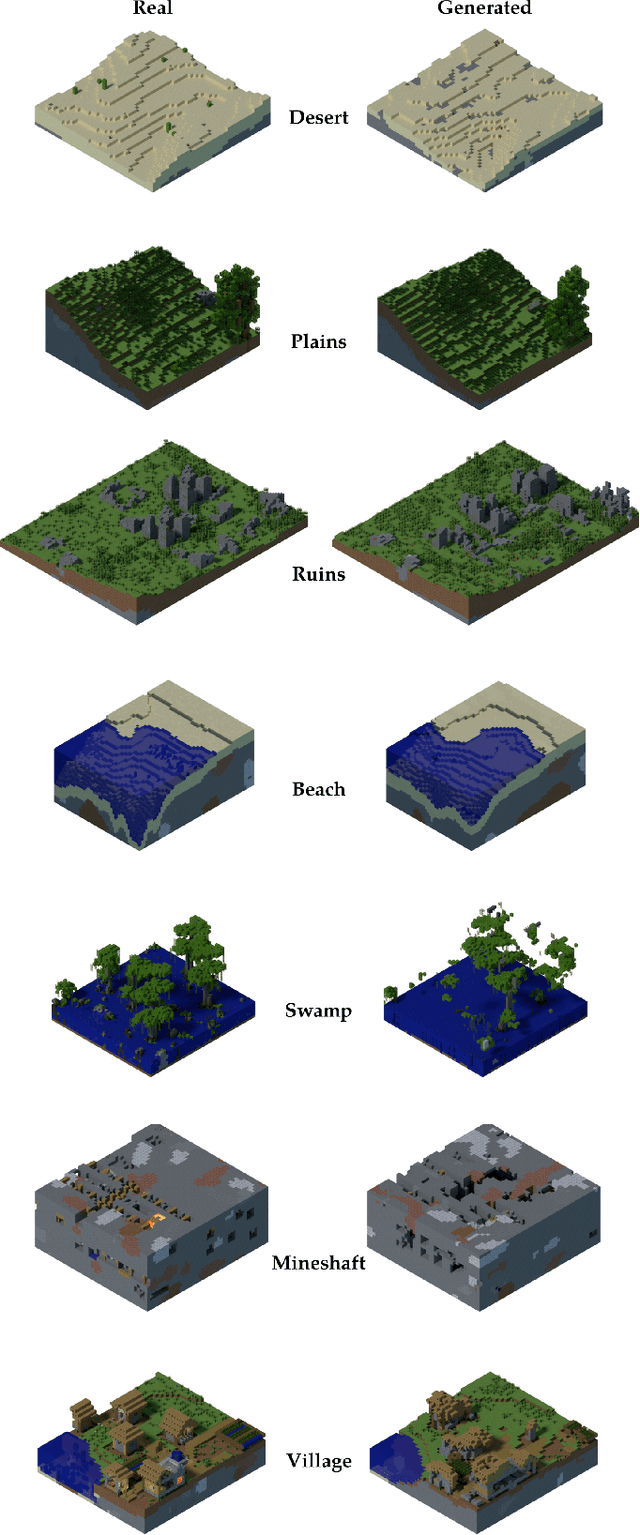
This work introduces World-GAN, the first method to perform data-driven Procedural Content Generation via Machine Learning in Minecraft from a single example. Based on a 3D Generative Adversarial Network (GAN) architecture, we are able to create arbitrarily sized world snippets from a given sample. We evaluate our approach on creations from the community as well as structures generated with the Minecraft World Generator. Our method is motivated by the dense representations used in Natural Language Processing (NLP) introduced with word2vec [1]. The proposed block2vec representations make World-GAN independent from the number of different blocks, which can vary a lot in Minecraft, and enable the generation of larger levels. Finally, we demonstrate that changing this new representation space allows us to change the generated style of an already trained generator. World-GAN enables its users to generate Minecraft worlds based on parts of their creations.
Automatic Risk Adaptation in Distributional Reinforcement Learning
Jun 11, 2021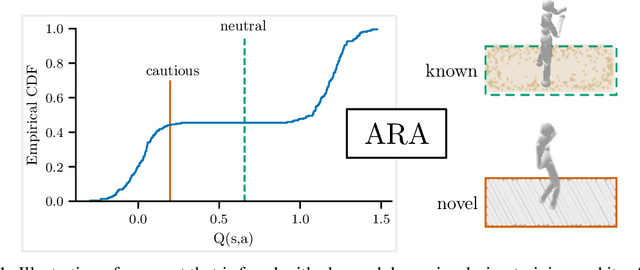


The use of Reinforcement Learning (RL) agents in practical applications requires the consideration of suboptimal outcomes, depending on the familiarity of the agent with its environment. This is especially important in safety-critical environments, where errors can lead to high costs or damage. In distributional RL, the risk-sensitivity can be controlled via different distortion measures of the estimated return distribution. However, these distortion functions require an estimate of the risk level, which is difficult to obtain and depends on the current state. In this work, we demonstrate the suboptimality of a static risk level estimation and propose a method to dynamically select risk levels at each environment step. Our method ARA (Automatic Risk Adaptation) estimates the appropriate risk level in both known and unknown environments using a Random Network Distillation error. We show reduced failure rates by up to a factor of 7 and improved generalization performance by up to 14% compared to both risk-aware and risk-agnostic agents in several locomotion environments.
TOAD-GAN: Coherent Style Level Generation from a Single Example
Aug 04, 2020



In this work, we present TOAD-GAN (Token-based One-shot Arbitrary Dimension Generative Adversarial Network), a novel Procedural Content Generation (PCG) algorithm that generates token-based video game levels. TOAD-GAN follows the SinGAN architecture and can be trained using only one example. We demonstrate its application for Super Mario Bros. levels and are able to generate new levels of similar style in arbitrary sizes. We achieve state-of-the-art results in modeling the patterns of the training level and provide a comparison with different baselines under several metrics. Additionally, we present an extension of the method that allows the user to control the generation process of certain token structures to ensure a coherent global level layout. We provide this tool to the community to spur further research by publishing our source code.