 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest Practices For Empirical Meta-Algorithmic Research: Guidelines from the COSEAL Research Network
Dec 19, 2025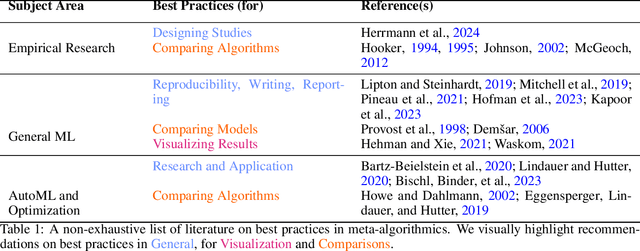
Empirical research on meta-algorithmics, such as algorithm selection, configuration, and scheduling, often relies on extensive and thus computationally expensive experiments. With the large degree of freedom we have over our experimental setup and design comes a plethora of possible error sources that threaten the scalability and validity of our scientific insights. Best practices for meta-algorithmic research exist, but they are scattered between different publications and fields, and continue to evolve separately from each other. In this report, we collect good practices for empirical meta-algorithmic research across the subfields of the COSEAL community, encompassing the entire experimental cycle: from formulating research questions and selecting an experimental design, to executing experiments, and ultimately, analyzing and presenting results impartially. It establishes the current state-of-the-art practices within meta-algorithmic research and serves as a guideline to both new researchers and practitioners in meta-algorithmic fields.
A Llama walks into the 'Bar': Efficient Supervised Fine-Tuning for Legal Reasoning in the Multi-state Bar Exam
Apr 07, 2025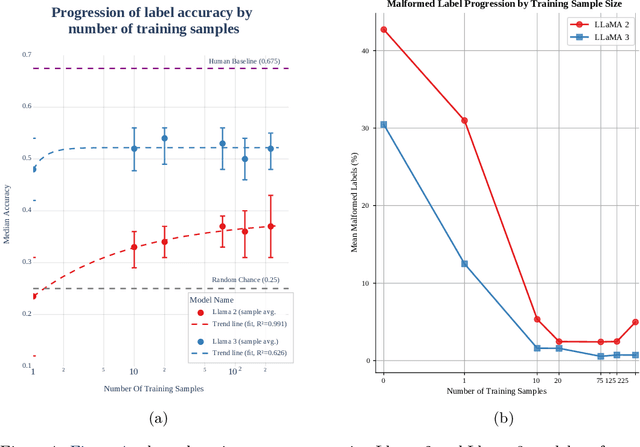
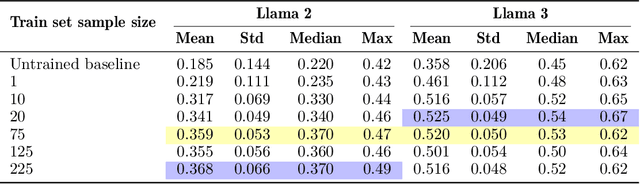
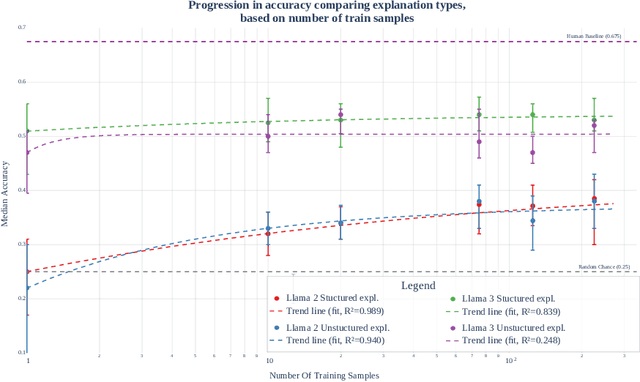
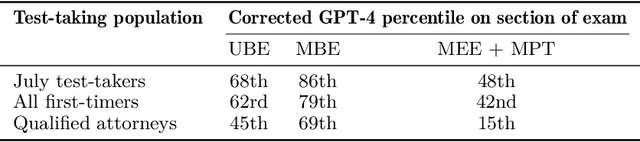
Legal reasoning tasks present unique challenges for large language models (LLMs) due to the complexity of domain-specific knowledge and reasoning processes. This paper investigates how effectively smaller language models (Llama 2 7B and Llama 3 8B) can be fine-tuned with a limited dataset of 1,514 Multi-state Bar Examination (MBE) questions to improve legal question answering accuracy. We evaluate these models on the 2022 MBE questions licensed from JD Advising, the same dataset used in the 'GPT-4 passes the Bar exam' study. Our methodology involves collecting approximately 200 questions per legal domain across 7 domains. We distill the dataset using Llama 3 (70B) to transform explanations into a structured IRAC (Issue, Rule, Application, Conclusion) format as a guided reasoning process to see if it results in better performance over the non-distilled dataset. We compare the non-fine-tuned models against their supervised fine-tuned (SFT) counterparts, trained for different sample sizes per domain, to study the effect on accuracy and prompt adherence. We also analyse option selection biases and their mitigation following SFT. In addition, we consolidate the performance across multiple variables: prompt type (few-shot vs zero-shot), answer ordering (chosen-option first vs generated-explanation first), response format (Numbered list vs Markdown vs JSON), and different decoding temperatures. Our findings show that domain-specific SFT helps some model configurations achieve close to human baseline performance, despite limited computational resources and a relatively small dataset. We release both the gathered SFT dataset and the family of Supervised Fine-tuned (SFT) adapters optimised for MBE performance. This establishes a practical lower bound on resources needed towards achieving effective legal question answering in smaller LLMs.
CANDID DAC: Leveraging Coupled Action Dimensions with Importance Differences in DAC
Jul 08, 2024



High-dimensional action spaces remain a challenge for dynamic algorithm configuration (DAC). Interdependencies and varying importance between action dimensions are further known key characteristics of DAC problems. We argue that these Coupled Action Dimensions with Importance Differences (CANDID) represent aspects of the DAC problem that are not yet fully explored. To address this gap, we introduce a new white-box benchmark within the DACBench suite that simulates the properties of CANDID. Further, we propose sequential policies as an effective strategy for managing these properties. Such policies factorize the action space and mitigate exponential growth by learning a policy per action dimension. At the same time, these policies accommodate the interdependence of action dimensions by fostering implicit coordination. We show this in an experimental study of value-based policies on our new benchmark. This study demonstrates that sequential policies significantly outperform independent learning of factorized policies in CANDID action spaces. In addition, they overcome the scalability limitations associated with learning a single policy across all action dimensions. The code used for our experiments is available under https://github.com/PhilippBordne/candidDAC.
Inferring Behavior-Specific Context Improves Zero-Shot Generalization in Reinforcement Learning
Apr 15, 2024In this work, we address the challenge of zero-shot generalization (ZSG) in Reinforcement Learning (RL), where agents must adapt to entirely novel environments without additional training. We argue that understanding and utilizing contextual cues, such as the gravity level of the environment, is critical for robust generalization, and we propose to integrate the learning of context representations directly with policy learning. Our algorithm demonstrates improved generalization on various simulated domains, outperforming prior context-learning techniques in zero-shot settings. By jointly learning policy and context, our method acquires behavior-specific context representations, enabling adaptation to unseen environments and marks progress towards reinforcement learning systems that generalize across diverse real-world tasks. Our code and experiments are available at https://github.com/tidiane-camaret/contextual_rl_zero_shot.
Dreaming of Many Worlds: Learning Contextual World Models Aids Zero-Shot Generalization
Mar 16, 2024



Zero-shot generalization (ZSG) to unseen dynamics is a major challenge for creating generally capable embodied agents. To address the broader challenge, we start with the simpler setting of contextual reinforcement learning (cRL), assuming observability of the context values that parameterize the variation in the system's dynamics, such as the mass or dimensions of a robot, without making further simplifying assumptions about the observability of the Markovian state. Toward the goal of ZSG to unseen variation in context, we propose the contextual recurrent state-space model (cRSSM), which introduces changes to the world model of the Dreamer (v3) (Hafner et al., 2023). This allows the world model to incorporate context for inferring latent Markovian states from the observations and modeling the latent dynamics. Our experiments show that such systematic incorporation of the context improves the ZSG of the policies trained on the ``dreams'' of the world model. We further find qualitatively that our approach allows Dreamer to disentangle the latent state from context, allowing it to extrapolate its dreams to the many worlds of unseen contexts. The code for all our experiments is available at \url{https://github.com/sai-prasanna/dreaming_of_many_worlds}.
Hierarchical Transformers are Efficient Meta-Reinforcement Learners
Feb 09, 2024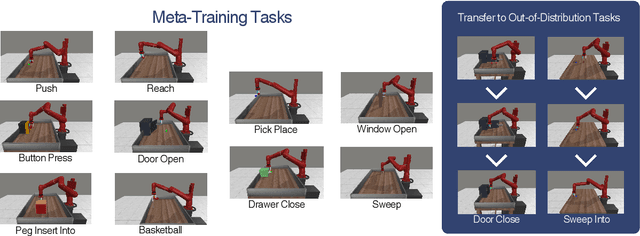

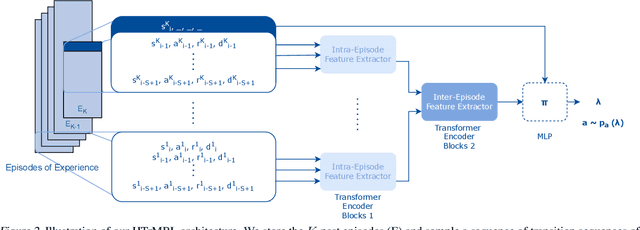
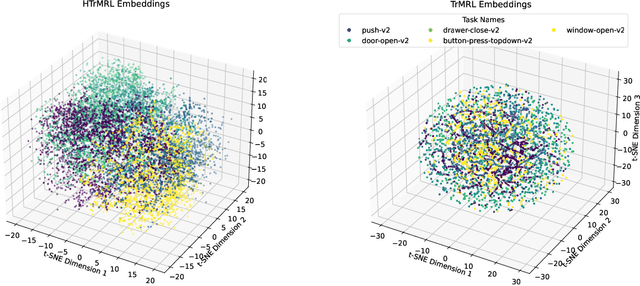
We introduce Hierarchical Transformers for Meta-Reinforcement Learning (HTrMRL), a powerful online meta-reinforcement learning approach. HTrMRL aims to address the challenge of enabling reinforcement learning agents to perform effectively in previously unseen tasks. We demonstrate how past episodes serve as a rich source of information, which our model effectively distills and applies to new contexts. Our learned algorithm is capable of outperforming the previous state-of-the-art and provides more efficient meta-training while significantly improving generalization capabilities. Experimental results, obtained across various simulated tasks of the Meta-World Benchmark, indicate a significant improvement in learning efficiency and adaptability compared to the state-of-the-art on a variety of tasks. Our approach not only enhances the agent's ability to generalize from limited data but also paves the way for more robust and versatile AI systems.
DeepCAVE: An Interactive Analysis Tool for Automated Machine Learning
Jun 07, 2022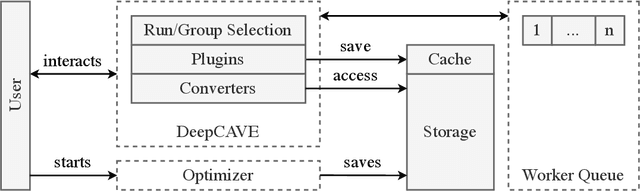
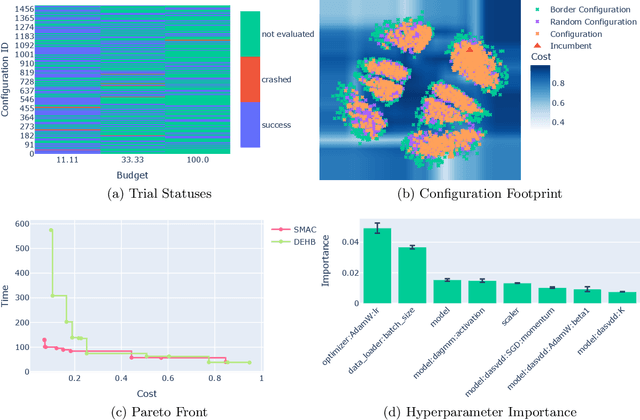
Automated Machine Learning (AutoML) is used more than ever before to support users in determining efficient hyperparameters, neural architectures, or even full machine learning pipelines. However, users tend to mistrust the optimization process and its results due to a lack of transparency, making manual tuning still widespread. We introduce DeepCAVE, an interactive framework to analyze and monitor state-of-the-art optimization procedures for AutoML easily and ad hoc. By aiming for full and accessible transparency, DeepCAVE builds a bridge between users and AutoML and contributes to establishing trust. Our framework's modular and easy-to-extend nature provides users with automatically generated text, tables, and graphic visualizations. We show the value of DeepCAVE in an exemplary use-case of outlier detection, in which our framework makes it easy to identify problems, compare multiple runs and interpret optimization processes. The package is freely available on GitHub https://github.com/automl/DeepCAVE.
Automated Dynamic Algorithm Configuration
May 27, 2022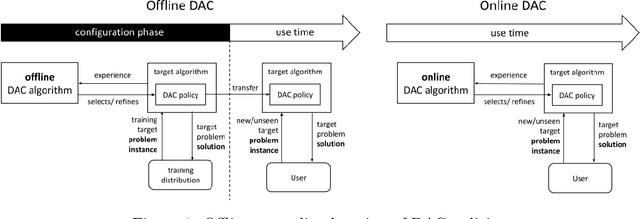

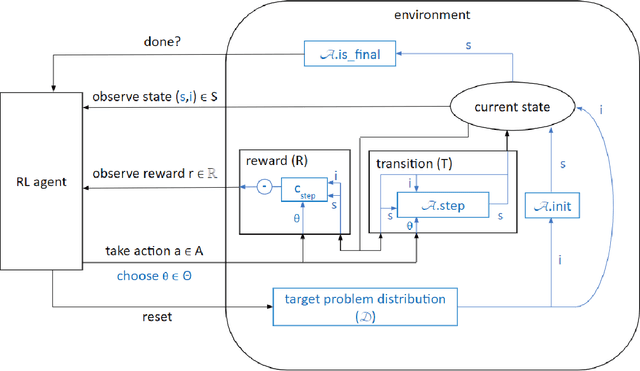
The performance of an algorithm often critically depends on its parameter configuration. While a variety of automated algorithm configuration methods have been proposed to relieve users from the tedious and error-prone task of manually tuning parameters, there is still a lot of untapped potential as the learned configuration is static, i.e., parameter settings remain fixed throughout the run. However, it has been shown that some algorithm parameters are best adjusted dynamically during execution, e.g., to adapt to the current part of the optimization landscape. Thus far, this is most commonly achieved through hand-crafted heuristics. A promising recent alternative is to automatically learn such dynamic parameter adaptation policies from data. In this article, we give the first comprehensive account of this new field of automated dynamic algorithm configuration (DAC), present a series of recent advances, and provide a solid foundation for future research in this field. Specifically, we (i) situate DAC in the broader historical context of AI research; (ii) formalize DAC as a computational problem; (iii) identify the methods used in prior-art to tackle this problem; (iv) conduct empirical case studies for using DAC in evolutionary optimization, AI planning, and machine learning.
Contextualize Me -- The Case for Context in Reinforcement Learning
Feb 09, 2022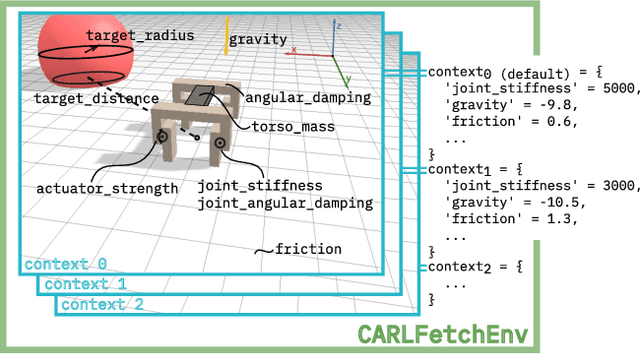
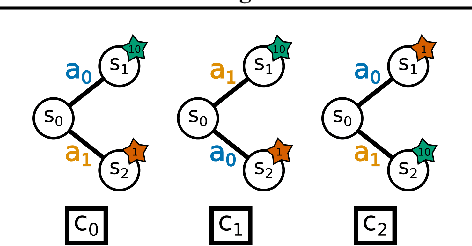
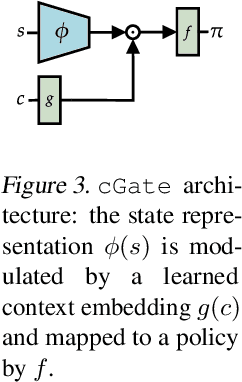
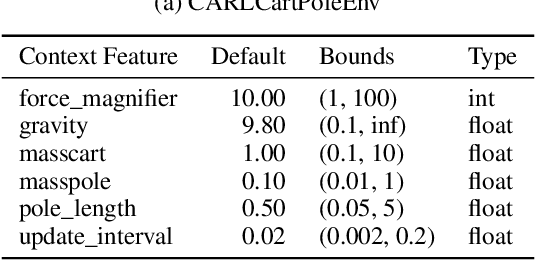
While Reinforcement Learning (RL) has made great strides towards solving increasingly complicated problems, many algorithms are still brittle to even slight changes in environments. Contextual Reinforcement Learning (cRL) provides a theoretical framework to model such changes in a principled manner, thereby enabling flexible, precise and interpretable task specification and generation. Thus, cRL is an important formalization for studying generalization in RL. In this work, we reason about solving cRL in theory and practice. We show that theoretically optimal behavior in contextual Markov Decision Processes requires explicit context information. In addition, we empirically explore context-based task generation, utilizing context information in training and propose cGate, our state-modulating policy architecture. To this end, we introduce the first benchmark library designed for generalization based on cRL extensions of popular benchmarks, CARL. In short: Context matters!
Theory-inspired Parameter Control Benchmarks for Dynamic Algorithm Configuration
Feb 07, 2022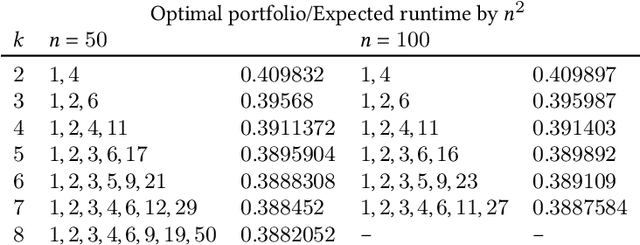
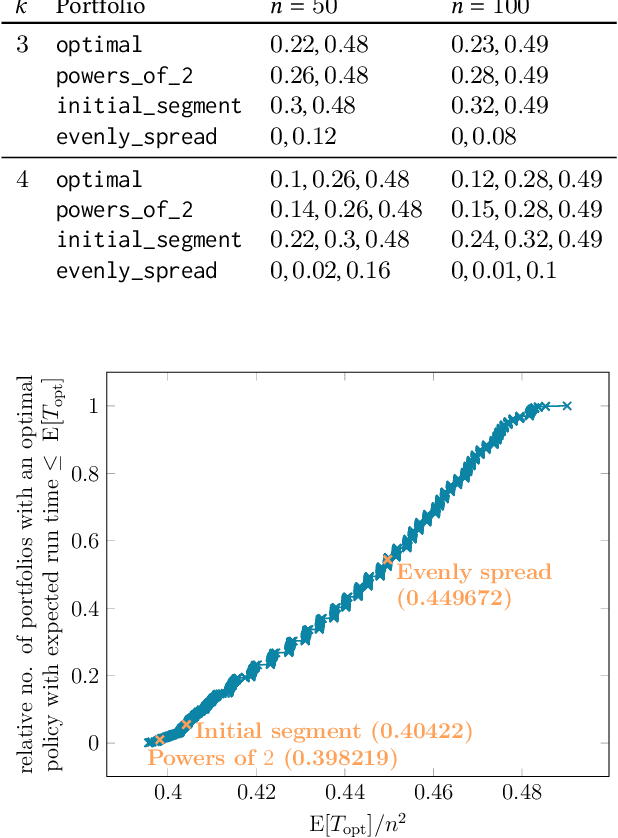
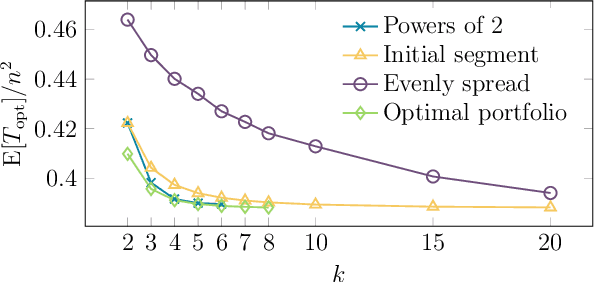
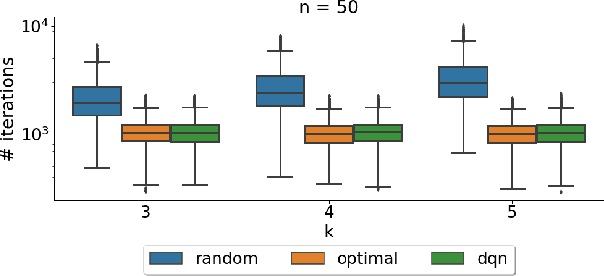
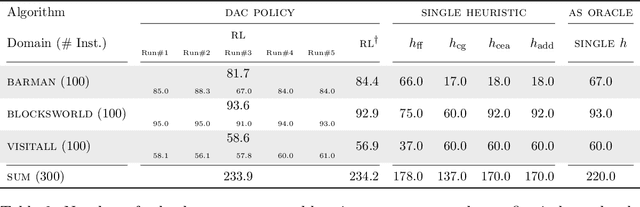
It has long been observed that the performance of evolutionary algorithms and other randomized search heuristics can benefit from a non-static choice of the parameters that steer their optimization behavior. Mechanisms that identify suitable configurations on the fly ("parameter control") or via a dedicated training process ("dynamic algorithm configuration") are therefore an important component of modern evolutionary computation frameworks. Several approaches to address the dynamic parameter setting problem exist, but we barely understand which ones to prefer for which applications. As in classical benchmarking, problem collections with a known ground truth can offer very meaningful insights in this context. Unfortunately, settings with well-understood control policies are very rare. One of the few exceptions for which we know which parameter settings minimize the expected runtime is the LeadingOnes problem. We extend this benchmark by analyzing optimal control policies that can select the parameters only from a given portfolio of possible values. This also allows us to compute optimal parameter portfolios of a given size. We demonstrate the usefulness of our benchmarks by analyzing the behavior of the DDQN reinforcement learning approach for dynamic algorithm configuration.