 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgecarps: A Framework for Comparing N Hyperparameter Optimizers on M Benchmarks
Jun 06, 2025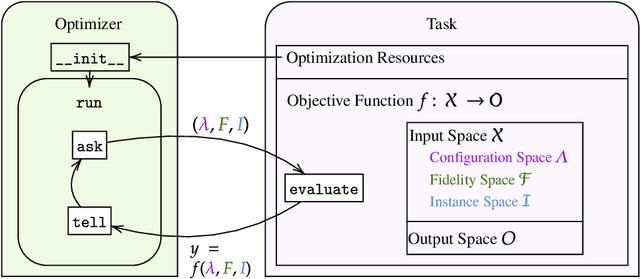

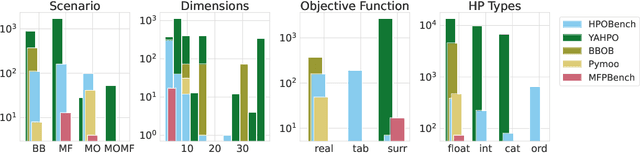
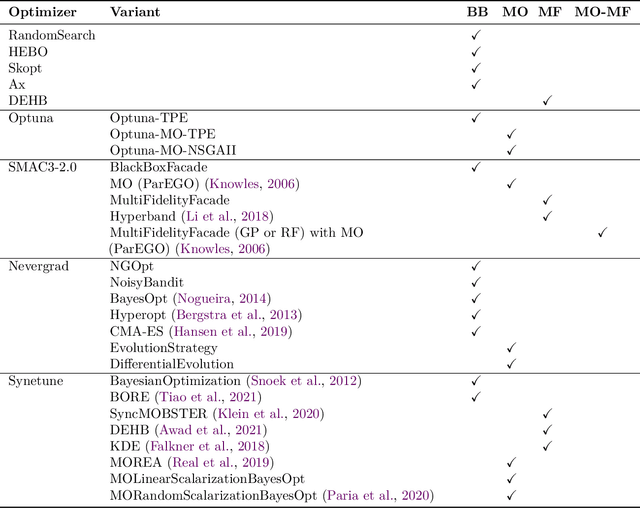
Hyperparameter Optimization (HPO) is crucial to develop well-performing machine learning models. In order to ease prototyping and benchmarking of HPO methods, we propose carps, a benchmark framework for Comprehensive Automated Research Performance Studies allowing to evaluate N optimizers on M benchmark tasks. In this first release of carps, we focus on the four most important types of HPO task types: blackbox, multi-fidelity, multi-objective and multi-fidelity-multi-objective. With 3 336 tasks from 5 community benchmark collections and 28 variants of 9 optimizer families, we offer the biggest go-to library to date to evaluate and compare HPO methods. The carps framework relies on a purpose-built, lightweight interface, gluing together optimizers and benchmark tasks. It also features an analysis pipeline, facilitating the evaluation of optimizers on benchmarks. However, navigating a huge number of tasks while developing and comparing methods can be computationally infeasible. To address this, we obtain a subset of representative tasks by minimizing the star discrepancy of the subset, in the space spanned by the full set. As a result, we propose an initial subset of 10 to 30 diverse tasks for each task type, and include functionality to re-compute subsets as more benchmarks become available, enabling efficient evaluations. We also establish a first set of baseline results on these tasks as a measure for future comparisons. With carps (https://www.github.com/automl/CARP-S), we make an important step in the standardization of HPO evaluation.
ARLBench: Flexible and Efficient Benchmarking for Hyperparameter Optimization in Reinforcement Learning
Sep 27, 2024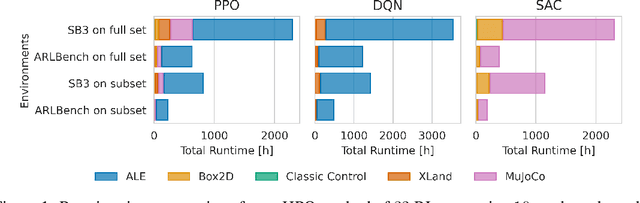


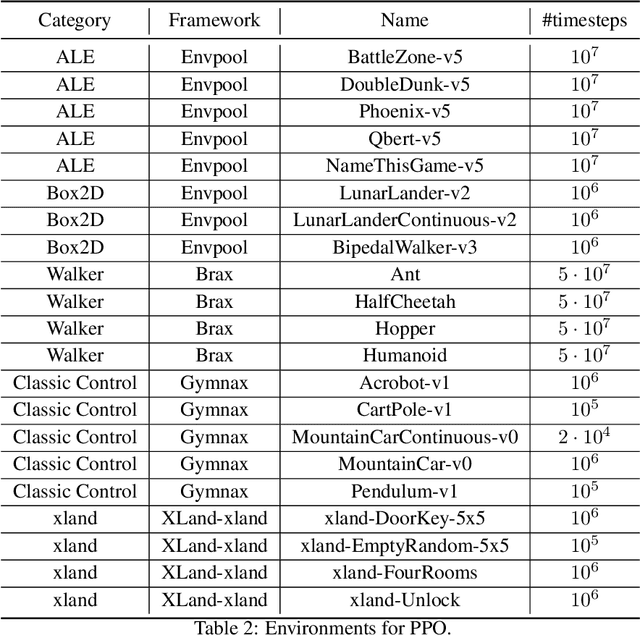
Hyperparameters are a critical factor in reliably training well-performing reinforcement learning (RL) agents. Unfortunately, developing and evaluating automated approaches for tuning such hyperparameters is both costly and time-consuming. As a result, such approaches are often only evaluated on a single domain or algorithm, making comparisons difficult and limiting insights into their generalizability. We propose ARLBench, a benchmark for hyperparameter optimization (HPO) in RL that allows comparisons of diverse HPO approaches while being highly efficient in evaluation. To enable research into HPO in RL, even in settings with low compute resources, we select a representative subset of HPO tasks spanning a variety of algorithm and environment combinations. This selection allows for generating a performance profile of an automated RL (AutoRL) method using only a fraction of the compute previously necessary, enabling a broader range of researchers to work on HPO in RL. With the extensive and large-scale dataset on hyperparameter landscapes that our selection is based on, ARLBench is an efficient, flexible, and future-oriented foundation for research on AutoRL. Both the benchmark and the dataset are available at https://github.com/automl/arlbench.
* Accepted at the 17th European Workshop on Reinforcement Learning
Instance Selection for Dynamic Algorithm Configuration with Reinforcement Learning: Improving Generalization
Jul 18, 2024Dynamic Algorithm Configuration (DAC) addresses the challenge of dynamically setting hyperparameters of an algorithm for a diverse set of instances rather than focusing solely on individual tasks. Agents trained with Deep Reinforcement Learning (RL) offer a pathway to solve such settings. However, the limited generalization performance of these agents has significantly hindered the application in DAC. Our hypothesis is that a potential bias in the training instances limits generalization capabilities. We take a step towards mitigating this by selecting a representative subset of training instances to overcome overrepresentation and then retraining the agent on this subset to improve its generalization performance. For constructing the meta-features for the subset selection, we particularly account for the dynamic nature of the RL agent by computing time series features on trajectories of actions and rewards generated by the agent's interaction with the environment. Through empirical evaluations on the Sigmoid and CMA-ES benchmarks from the standard benchmark library for DAC, called DACBench, we discuss the potentials of our selection technique compared to training on the entire instance set. Our results highlight the efficacy of instance selection in refining DAC policies for diverse instance spaces.
Self-Adjusting Weighted Expected Improvement for Bayesian Optimization
Jun 30, 2023Bayesian Optimization (BO) is a class of surrogate-based, sample-efficient algorithms for optimizing black-box problems with small evaluation budgets. The BO pipeline itself is highly configurable with many different design choices regarding the initial design, surrogate model, and acquisition function (AF). Unfortunately, our understanding of how to select suitable components for a problem at hand is very limited. In this work, we focus on the definition of the AF, whose main purpose is to balance the trade-off between exploring regions with high uncertainty and those with high promise for good solutions. We propose Self-Adjusting Weighted Expected Improvement (SAWEI), where we let the exploration-exploitation trade-off self-adjust in a data-driven manner, based on a convergence criterion for BO. On the noise-free black-box BBOB functions of the COCO benchmarking platform, our method exhibits a favorable any-time performance compared to handcrafted baselines and serves as a robust default choice for any problem structure. The suitability of our method also transfers to HPOBench. With SAWEI, we are a step closer to on-the-fly, data-driven, and robust BO designs that automatically adjust their sampling behavior to the problem at hand.
AutoRL Hyperparameter Landscapes
Apr 11, 2023Although Reinforcement Learning (RL) has shown to be capable of producing impressive results, its use is limited by the impact of its hyperparameters on performance. This often makes it difficult to achieve good results in practice. Automated RL (AutoRL) addresses this difficulty, yet little is known about the dynamics of the hyperparameter landscapes that hyperparameter optimization (HPO) methods traverse in search of optimal configurations. In view of existing AutoRL approaches dynamically adjusting hyperparameter configurations, we propose an approach to build and analyze these hyperparameter landscapes not just for one point in time but at multiple points in time throughout training. Addressing an important open question on the legitimacy of such dynamic AutoRL approaches, we provide thorough empirical evidence that the hyperparameter landscapes strongly vary over time across representative algorithms from RL literature (DQN and SAC) in different kinds of environments (Cartpole and Hopper). This supports the theory that hyperparameters should be dynamically adjusted during training and shows the potential for more insights on AutoRL problems that can be gained through landscape analyses.
Hyperparameters in Contextual RL are Highly Situational
Dec 21, 2022Although Reinforcement Learning (RL) has shown impressive results in games and simulation, real-world application of RL suffers from its instability under changing environment conditions and hyperparameters. We give a first impression of the extent of this instability by showing that the hyperparameters found by automatic hyperparameter optimization (HPO) methods are not only dependent on the problem at hand, but even on how well the state describes the environment dynamics. Specifically, we show that agents in contextual RL require different hyperparameters if they are shown how environmental factors change. In addition, finding adequate hyperparameter configurations is not equally easy for both settings, further highlighting the need for research into how hyperparameters influence learning and generalization in RL.
Towards Automated Design of Bayesian Optimization via Exploratory Landscape Analysis
Nov 17, 2022



Bayesian optimization (BO) algorithms form a class of surrogate-based heuristics, aimed at efficiently computing high-quality solutions for numerical black-box optimization problems. The BO pipeline is highly modular, with different design choices for the initial sampling strategy, the surrogate model, the acquisition function (AF), the solver used to optimize the AF, etc. We demonstrate in this work that a dynamic selection of the AF can benefit the BO design. More precisely, we show that already a na\"ive random forest regression model, built on top of exploratory landscape analysis features that are computed from the initial design points, suffices to recommend AFs that outperform any static choice, when considering performance over the classic BBOB benchmark suite for derivative-free numerical optimization methods on the COCO platform. Our work hence paves a way towards AutoML-assisted, on-the-fly BO designs that adjust their behavior on a run-by-run basis.
PI is back! Switching Acquisition Functions in Bayesian Optimization
Nov 02, 2022



Bayesian Optimization (BO) is a powerful, sample-efficient technique to optimize expensive-to-evaluate functions. Each of the BO components, such as the surrogate model, the acquisition function (AF), or the initial design, is subject to a wide range of design choices. Selecting the right components for a given optimization task is a challenging task, which can have significant impact on the quality of the obtained results. In this work, we initiate the analysis of which AF to favor for which optimization scenarios. To this end, we benchmark SMAC3 using Expected Improvement (EI) and Probability of Improvement (PI) as acquisition functions on the 24 BBOB functions of the COCO environment. We compare their results with those of schedules switching between AFs. One schedule aims to use EI's explorative behavior in the early optimization steps, and then switches to PI for a better exploitation in the final steps. We also compare this to a random schedule and round-robin selection of EI and PI. We observe that dynamic schedules oftentimes outperform any single static one. Our results suggest that a schedule that allocates the first 25 % of the optimization budget to EI and the last 75 % to PI is a reliable default. However, we also observe considerable performance differences for the 24 functions, suggesting that a per-instance allocation, possibly learned on the fly, could offer significant improvement over the state-of-the-art BO designs.
POLTER: Policy Trajectory Ensemble Regularization for Unsupervised Reinforcement Learning
May 23, 2022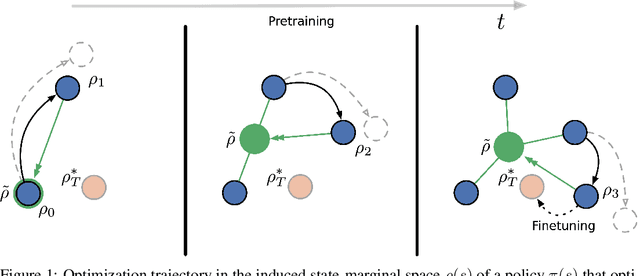

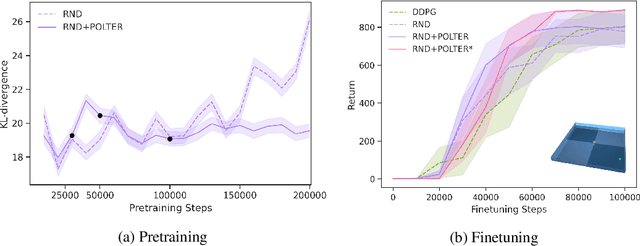
The goal of Unsupervised Reinforcement Learning (URL) is to find a reward-agnostic prior policy on a task domain, such that the sample-efficiency on supervised downstream tasks is improved. Although agents initialized with such a prior policy can achieve a significantly higher reward with fewer samples when finetuned on the downstream task, it is still an open question how an optimal pretrained prior policy can be achieved in practice. In this work, we present POLTER (Policy Trajectory Ensemble Regularization) - a general method to regularize the pretraining that can be applied to any URL algorithm and is especially useful on data- and knowledge-based URL algorithms. It utilizes an ensemble of policies that are discovered during pretraining and moves the policy of the URL algorithm closer to its optimal prior. Our method is theoretically justified, and we analyze its practical effects on a white-box benchmark, allowing us to study POLTER with full control. In our main experiments, we evaluate POLTER on the Unsupervised Reinforcement Learning Benchmark (URLB), which consists of 12 tasks in 3 domains. We demonstrate the generality of our approach by improving the performance of a diverse set of data- and knowledge-based URL algorithms by 19% on average and up to 40% in the best case. Under a fair comparison with tuned baselines and tuned POLTER, we establish a new the state-of-the-art on the URLB.
Contextualize Me -- The Case for Context in Reinforcement Learning
Feb 09, 2022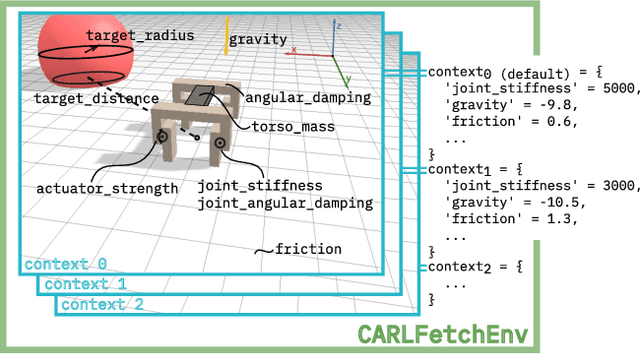
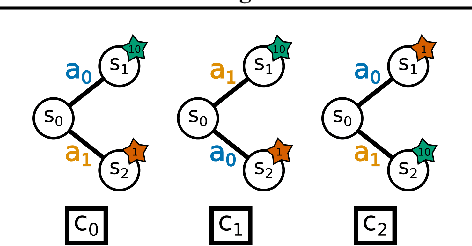
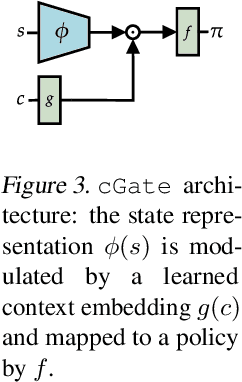
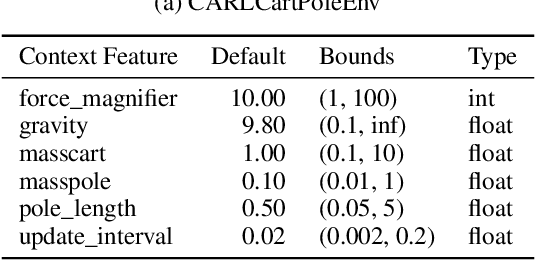
While Reinforcement Learning (RL) has made great strides towards solving increasingly complicated problems, many algorithms are still brittle to even slight changes in environments. Contextual Reinforcement Learning (cRL) provides a theoretical framework to model such changes in a principled manner, thereby enabling flexible, precise and interpretable task specification and generation. Thus, cRL is an important formalization for studying generalization in RL. In this work, we reason about solving cRL in theory and practice. We show that theoretically optimal behavior in contextual Markov Decision Processes requires explicit context information. In addition, we empirically explore context-based task generation, utilizing context information in training and propose cGate, our state-modulating policy architecture. To this end, we introduce the first benchmark library designed for generalization based on cRL extensions of popular benchmarks, CARL. In short: Context matters!