 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARL: A Benchmark for Contextual and Adaptive Reinforcement Learning
Paper and Code
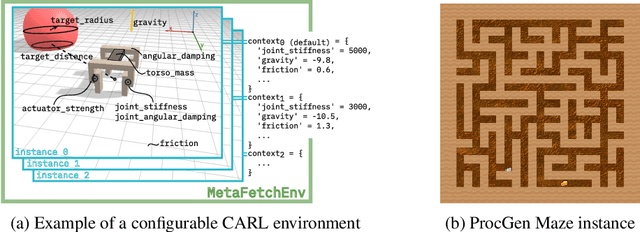
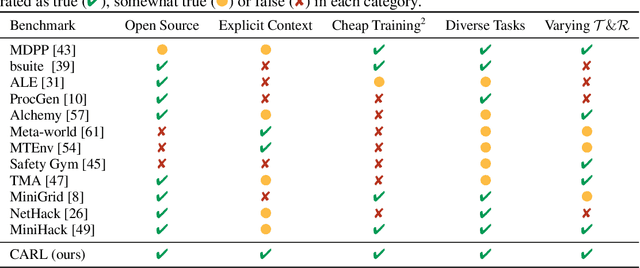
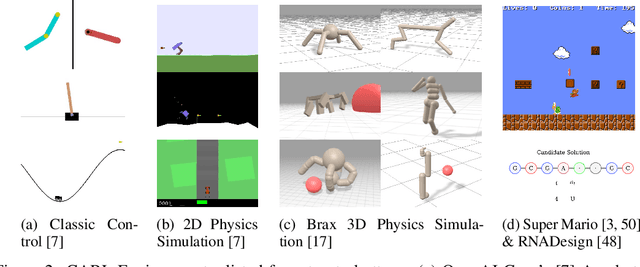

While Reinforcement Learning has made great strides towards solving ever more complicated tasks, many algorithms are still brittle to even slight changes in their environment. This is a limiting factor for real-world applications of RL. Although the research community continuously aims at improving both robustness and generalization of RL algorithms, unfortunately it still lacks an open-source set of well-defined benchmark problems based on a consistent theoretical framework, which allows comparing different approaches in a fair, reliable and reproducibleway. To fill this gap, we propose CARL, a collection of well-known RL environments extended to contextual RL problems to study generalization. We show the urgent need of such benchmarks by demonstrating that even simple toy environments become challenging for commonly used approaches if different contextual instances of this task have to be considered. Furthermore, CARL allows us to provide first evidence that disentangling representation learning of the states from the policy learning with the context facilitates better generalization. By providing variations of diverse benchmarks from classic control, physical simulations, games and a real-world application of RNA design, CARL will allow the community to derive many more such insights on a solid empirical foundation.