 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid Augmentations for Time Series (RATS): A High-Performance Library for Time Series Augmentation
Jan 06, 2026Time series augmentation is critical for training robust deep learning models, particularly in domains where labelled data is scarce and expensive to obtain. However, existing augmentation libraries for time series, mainly written in Python, suffer from performance bottlenecks, where running time grows exponentially as dataset sizes increase -- an aspect limiting their applicability in large-scale, production-grade systems. We introduce RATS (Rapid Augmentations for Time Series), a high-performance library for time series augmentation written in Rust with Python bindings (RATSpy). RATS implements multiple augmentation methods spanning basic transformations, frequency-domain operations and time warping techniques, all accessible through a unified pipeline interface with built-in parallelisation. Comprehensive benchmarking of RATSpy versus a commonly used library (tasug) on 143 datasets demonstrates that RATSpy achieves an average speedup of 74.5\% over tsaug (up to 94.8\% on large datasets), with up to 47.9\% less peak memory usage.
Guidelines for the Quality Assessment of Energy-Aware NAS Benchmarks
May 21, 2025Neural Architecture Search (NAS) accelerates progress in deep learning through systematic refinement of model architectures. The downside is increasingly large energy consumption during the search process. Surrogate-based benchmarking mitigates the cost of full training by querying a pre-trained surrogate to obtain an estimate for the quality of the model. Specifically, energy-aware benchmarking aims to make it possible for NAS to favourably trade off model energy consumption against accuracy. Towards this end, we propose three design principles for such energy-aware benchmarks: (i) reliable power measurements, (ii) a wide range of GPU usage, and (iii) holistic cost reporting. We analyse EA-HAS-Bench based on these principles and find that the choice of GPU measurement API has a large impact on the quality of results. Using the Nvidia System Management Interface (SMI) on top of its underlying library influences the sampling rate during the initial data collection, returning faulty low-power estimations. This results in poor correlation with accurate measurements obtained from an external power meter. With this study, we bring to attention several key considerations when performing energy-aware surrogate-based benchmarking and derive first guidelines that can help design novel benchmarks. We show a narrow usage range of the four GPUs attached to our device, ranging from 146 W to 305 W in a single-GPU setting, and narrowing down even further when using all four GPUs. To improve holistic energy reporting, we propose calibration experiments over assumptions made in popular tools, such as Code Carbon, thus achieving reductions in the maximum inaccuracy from 10.3 % to 8.9 % without and to 6.6 % with prior estimation of the expected load on the device.
TinyverseGP: Towards a Modular Cross-domain Benchmarking Framework for Genetic Programming
Apr 14, 2025Over the years, genetic programming (GP) has evolved, with many proposed variations, especially in how they represent a solution. Being essentially a program synthesis algorithm, it is capable of tackling multiple problem domains. Current benchmarking initiatives are fragmented, as the different representations are not compared with each other and their performance is not measured across the different domains. In this work, we propose a unified framework, dubbed TinyverseGP (inspired by tinyGP), which provides support to multiple representations and problem domains, including symbolic regression, logic synthesis and policy search.
* Accepted for presentation as a poster at the Genetic and Evolutionary Computation Conference (GECCO) and will appear in the GECCO'25 companion. GECCO'25 will be held July 14-18, 2025 in M\'alaga, Spain
ARLBench: Flexible and Efficient Benchmarking for Hyperparameter Optimization in Reinforcement Learning
Sep 27, 2024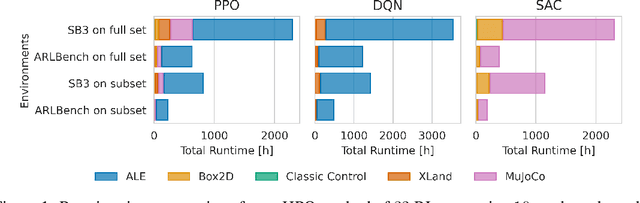


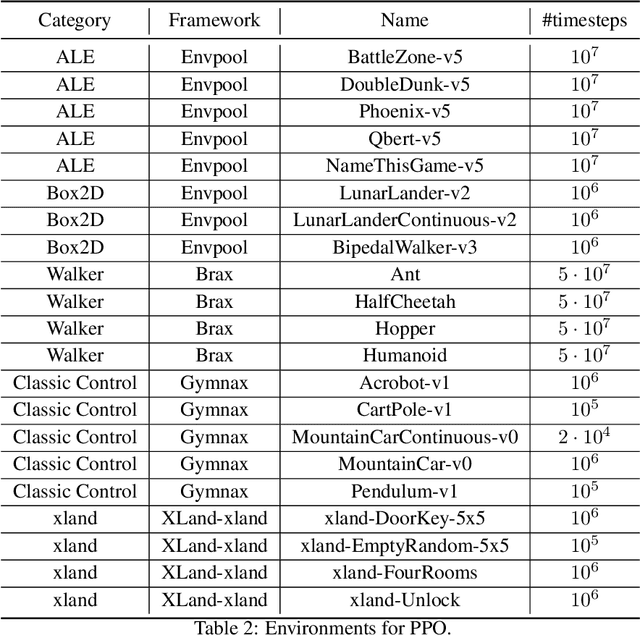
Hyperparameters are a critical factor in reliably training well-performing reinforcement learning (RL) agents. Unfortunately, developing and evaluating automated approaches for tuning such hyperparameters is both costly and time-consuming. As a result, such approaches are often only evaluated on a single domain or algorithm, making comparisons difficult and limiting insights into their generalizability. We propose ARLBench, a benchmark for hyperparameter optimization (HPO) in RL that allows comparisons of diverse HPO approaches while being highly efficient in evaluation. To enable research into HPO in RL, even in settings with low compute resources, we select a representative subset of HPO tasks spanning a variety of algorithm and environment combinations. This selection allows for generating a performance profile of an automated RL (AutoRL) method using only a fraction of the compute previously necessary, enabling a broader range of researchers to work on HPO in RL. With the extensive and large-scale dataset on hyperparameter landscapes that our selection is based on, ARLBench is an efficient, flexible, and future-oriented foundation for research on AutoRL. Both the benchmark and the dataset are available at https://github.com/automl/arlbench.
* Accepted at the 17th European Workshop on Reinforcement Learning
Q(D)O-ES: Population-based Quality (Diversity) Optimisation for Post Hoc Ensemble Selection in AutoML
Aug 02, 2023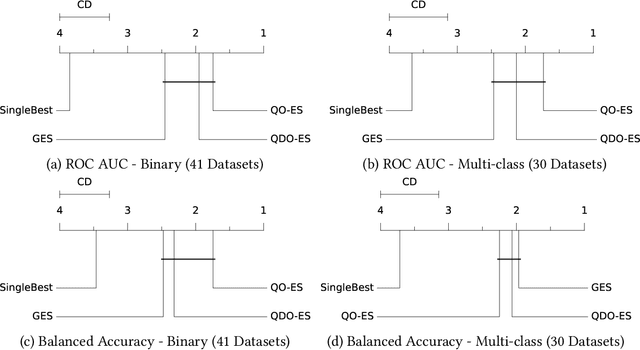
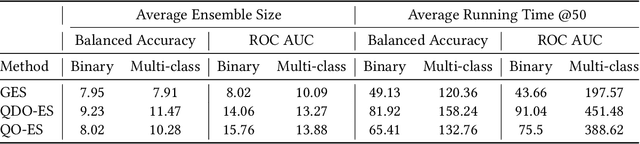
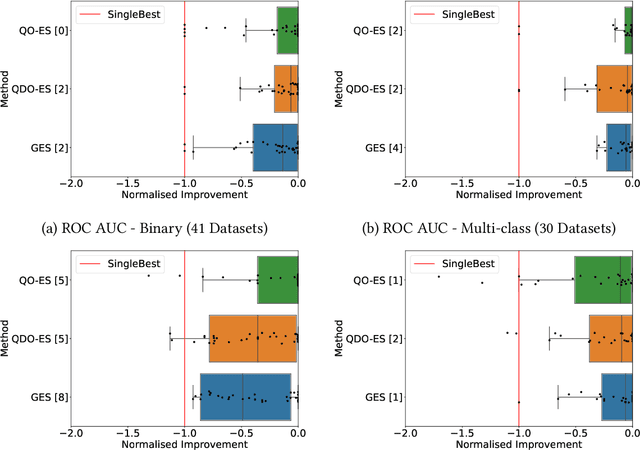
Automated machine learning (AutoML) systems commonly ensemble models post hoc to improve predictive performance, typically via greedy ensemble selection (GES). However, we believe that GES may not always be optimal, as it performs a simple deterministic greedy search. In this work, we introduce two novel population-based ensemble selection methods, QO-ES and QDO-ES, and compare them to GES. While QO-ES optimises solely for predictive performance, QDO-ES also considers the diversity of ensembles within the population, maintaining a diverse set of well-performing ensembles during optimisation based on ideas of quality diversity optimisation. The methods are evaluated using 71 classification datasets from the AutoML benchmark, demonstrating that QO-ES and QDO-ES often outrank GES, albeit only statistically significant on validation data. Our results further suggest that diversity can be beneficial for post hoc ensembling but also increases the risk of overfitting.
The Configurable SAT Solver Challenge (CSSC)
Aug 02, 2016
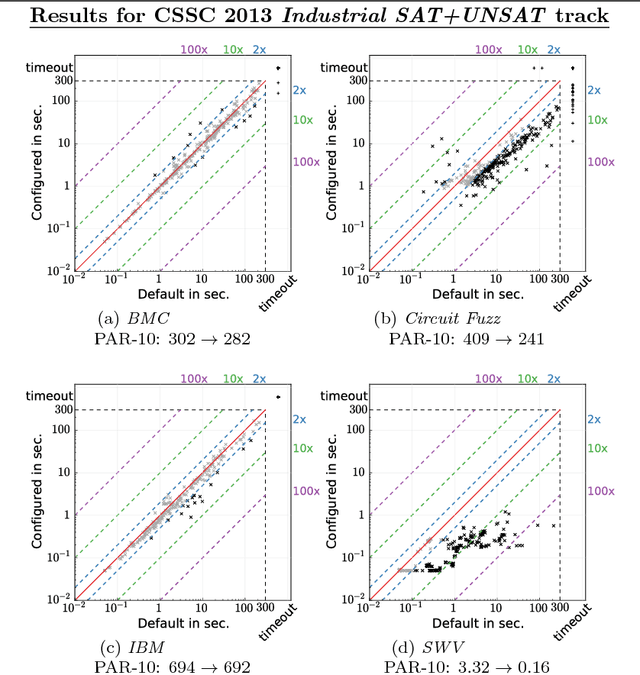


It is well known that different solution strategies work well for different types of instances of hard combinatorial problems. As a consequence, most solvers for the propositional satisfiability problem (SAT) expose parameters that allow them to be customized to a particular family of instances. In the international SAT competition series, these parameters are ignored: solvers are run using a single default parameter setting (supplied by the authors) for all benchmark instances in a given track. While this competition format rewards solvers with robust default settings, it does not reflect the situation faced by a practitioner who only cares about performance on one particular application and can invest some time into tuning solver parameters for this application. The new Configurable SAT Solver Competition (CSSC) compares solvers in this latter setting, scoring each solver by the performance it achieved after a fully automated configuration step. This article describes the CSSC in more detail, and reports the results obtained in its two instantiations so far, CSSC 2013 and 2014.
ASlib: A Benchmark Library for Algorithm Selection
Apr 06, 2016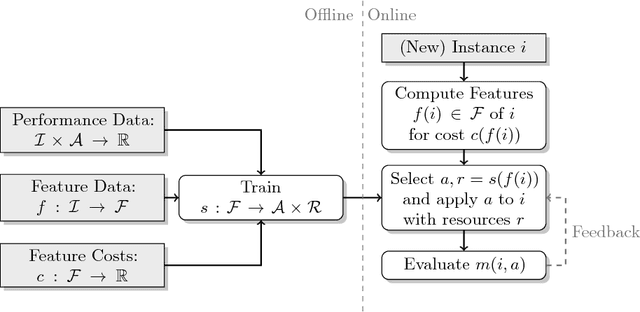
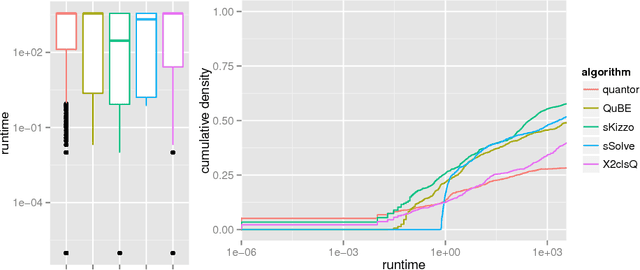
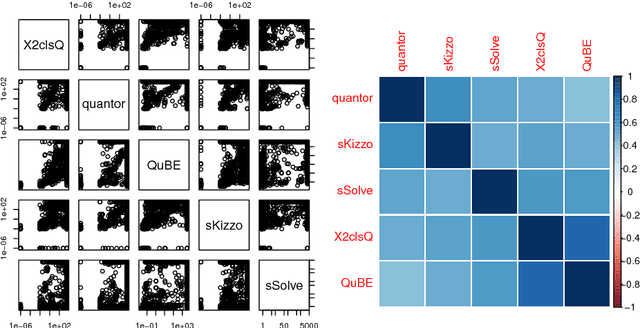
The task of algorithm selection involves choosing an algorithm from a set of algorithms on a per-instance basis in order to exploit the varying performance of algorithms over a set of instances. The algorithm selection problem is attracting increasing attention from researchers and practitioners in AI. Years of fruitful applications in a number of domains have resulted in a large amount of data, but the community lacks a standard format or repository for this data. This situation makes it difficult to share and compare different approaches effectively, as is done in other, more established fields. It also unnecessarily hinders new researchers who want to work in this area. To address this problem, we introduce a standardized format for representing algorithm selection scenarios and a repository that contains a growing number of data sets from the literature. Our format has been designed to be able to express a wide variety of different scenarios. Demonstrating the breadth and power of our platform, we describe a set of example experiments that build and evaluate algorithm selection models through a common interface. The results display the potential of algorithm selection to achieve significant performance improvements across a broad range of problems and algorithms.
claspfolio 2: Advances in Algorithm Selection for Answer Set Programming
May 07, 2014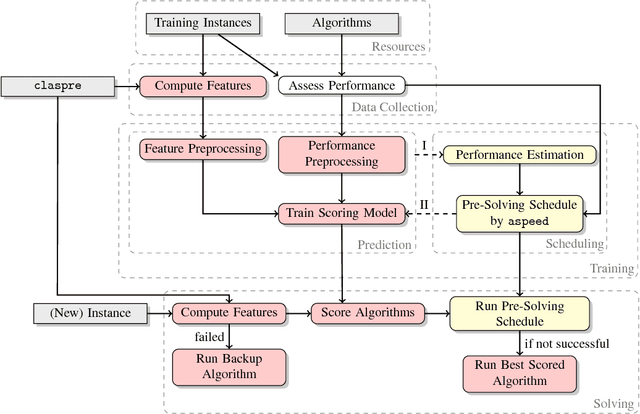


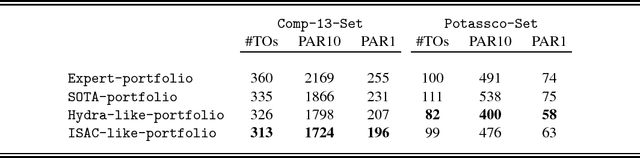
To appear in Theory and Practice of Logic Programming (TPLP). Building on the award-winning, portfolio-based ASP solver claspfolio, we present claspfolio 2, a modular and open solver architecture that integrates several different portfolio-based algorithm selection approaches and techniques. The claspfolio 2 solver framework supports various feature generators, solver selection approaches, solver portfolios, as well as solver-schedule-based pre-solving techniques. The default configuration of claspfolio 2 relies on a light-weight version of the ASP solver clasp to generate static and dynamic instance features. The flexible open design of claspfolio 2 is a distinguishing factor even beyond ASP. As such, it provides a unique framework for comparing and combining existing portfolio-based algorithm selection approaches and techniques in a single, unified framework. Taking advantage of this, we conducted an extensive experimental study to assess the impact of different feature sets, selection approaches and base solver portfolios. In addition to gaining substantial insights into the utility of the various approaches and techniques, we identified a default configuration of claspfolio 2 that achieves substantial performance gains not only over clasp's default configuration and the earlier version of claspfolio 2, but also over manually tuned configurations of clasp.
Solver Scheduling via Answer Set Programming
Jan 06, 2014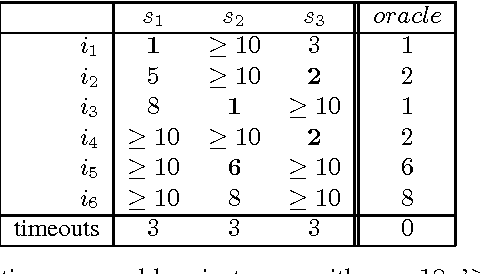
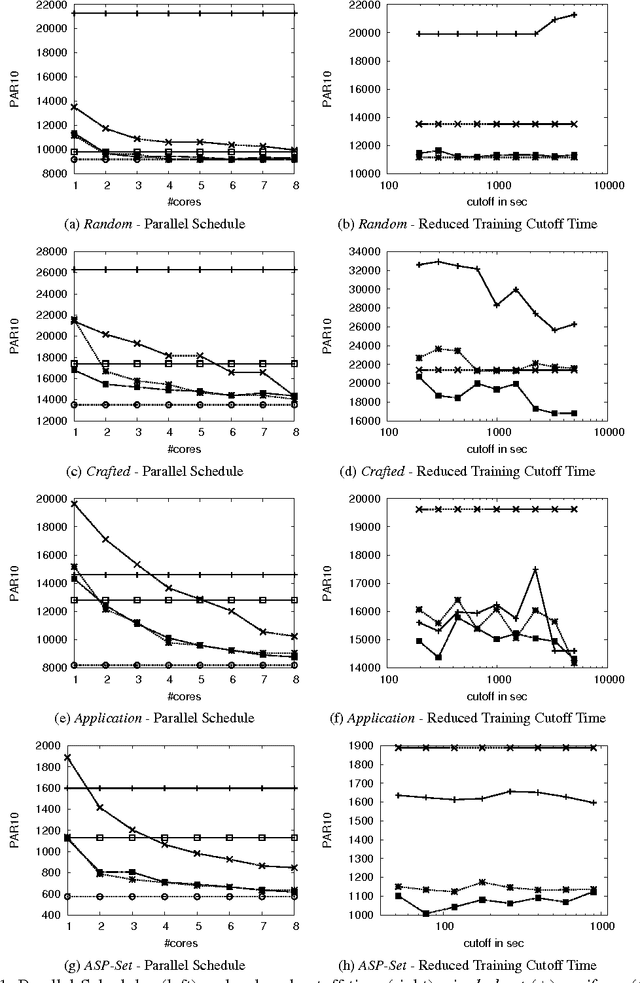
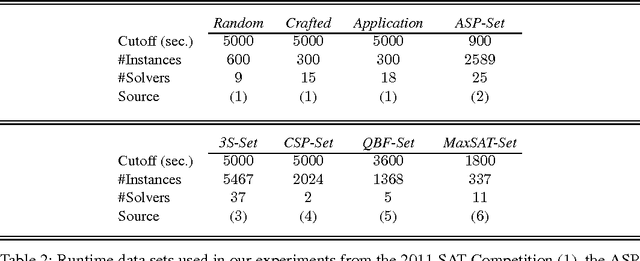
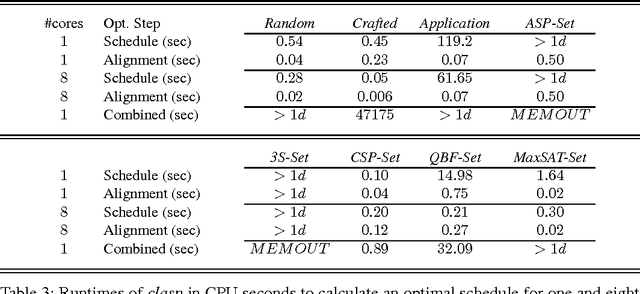
Although Boolean Constraint Technology has made tremendous progress over the last decade, the efficacy of state-of-the-art solvers is known to vary considerably across different types of problem instances and is known to depend strongly on algorithm parameters. This problem was addressed by means of a simple, yet effective approach using handmade, uniform and unordered schedules of multiple solvers in ppfolio, which showed very impressive performance in the 2011 SAT Competition. Inspired by this, we take advantage of the modeling and solving capacities of Answer Set Programming (ASP) to automatically determine more refined, that is, non-uniform and ordered solver schedules from existing benchmarking data. We begin by formulating the determination of such schedules as multi-criteria optimization problems and provide corresponding ASP encodings. The resulting encodings are easily customizable for different settings and the computation of optimum schedules can mostly be done in the blink of an eye, even when dealing with large runtime data sets stemming from many solvers on hundreds to thousands of instances. Also, the fact that our approach can be customized easily enabled us to swiftly adapt it to generate parallel schedules for multi-processor machines.
Bayesian Optimization With Censored Response Data
Oct 07, 2013



Bayesian optimization (BO) aims to minimize a given blackbox function using a model that is updated whenever new evidence about the function becomes available. Here, we address the problem of BO under partially right-censored response data, where in some evaluations we only obtain a lower bound on the function value. The ability to handle such response data allows us to adaptively censor costly function evaluations in minimization problems where the cost of a function evaluation corresponds to the function value. One important application giving rise to such censored data is the runtime-minimizing variant of the algorithm configuration problem: finding settings of a given parametric algorithm that minimize the runtime required for solving problem instances from a given distribution. We demonstrate that terminating slow algorithm runs prematurely and handling the resulting right-censored observations can substantially improve the state of the art in model-based algorithm configuration.