 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Uncertain Judgments to Calibrated Rankings: Conformal Elo Estimation for LLM Evaluation
Jun 11, 2026Evaluating new large language models typically requires costly human annotation campaigns at scale. LLM-as-a-judge offers a cheaper alternative, but judge scores carry systematic errors - such as position bias, self-preference, or intransitivity - that can strongly miscalibrate the resulting rankings. We quantify the resulting judge-human disagreement at two complementary levels. At the local level, we estimate per-battle uncertainty from the judge's own score differences by propagating calibrated win probabilities rather than hard labels into the Bradley-Terry procedure. This alone provides a drastic improvement to Elo estimation accuracy, bringing LLM-derived ratings within 17.9 Elo MAE of human-derived ones when averaged over 55 held-out models on LMArena. At the global level, we apply split conformal prediction to the residual gap between LLM-derived and human-derived Elo ratings across held-out models, producing prediction intervals with distribution-free marginal coverage guarantees that account for irreducible LLM-human disagreement. Together, these two layers yield a low-cost evaluation tool that provides developers with calibrated Elo estimates and honest uncertainty bounds, without access to large-scale human annotations.To facilitate reproducibility, we release our code at https://github.com/kargibora/SoftElo .
An Open-Source Training Dataset for Foundation Models for Black-box Optimization
May 22, 2026Most black-box optimization methods require extensive hyperparameter tuning, often limiting their ability to generalize across different optimization domains. Foundation models for black-box optimization that learn optimization principles from a large collection of optimization trajectories offer a promising alternative, with the potential to outperform manually designed methods across diverse problem classes. However, prior work has either relied on non-public datasets or on purely synthetic data, limiting reproducibility and generalization to real-world problems. As a result, progress in this area has been constrained by the lack of large-scale, real-world, publicly available pre-training data. We introduce BBO-Pile, the first open-source dataset comprising over 500K optimization trajectories evaluated across 3095 different black-boxes for different optimizers, which represents by far the largest public dataset for this task. Using this dataset, we train a family of foundation models at multiple scales, ranging from 2M to 80M parameters and from 200M to 2B training tokens, and study their scaling behavior with respect to compute. Our results demonstrate that large-scale pre-training is a viable and effective approach to imitate black-box optimization methods, paving the way for future research in this direction.
TabPFN-3: Technical Report
May 13, 2026Tabular data underpins most high-value prediction problems in science and industry, and TabPFN has driven the foundation model revolution for this modality. Designed with feedback from our users, TabPFN-3 builds on this foundation to scale state-of-the-art performance to datasets with 1M training rows and substantially reduce training and inference time. Pretrained exclusively on synthetic data from our prior, TabPFN-3 dramatically pushes the frontier of tabular prediction and brings substantial gains on time series, relational, and tabular-text data. On the standard tabular benchmark TabArena, a forward pass of TabPFN-3 outperforms all other models, including tuned and ensembled baselines, by a significant margin, and pareto-dominates the speed/performance frontier. On more diverse datasets, TabPFN-3 ranks first on datasets with many classes, and beats 8-hour-tuned gradient-boosted-tree baselines on datasets up to 1M training rows and 200 features. TabPFN-3 introduces test-time compute scaling to tabular foundation models. Our API offering TabPFN-3-Plus (Thinking) exploits this to beat all non-TabPFN models by over 200 Elo on TabArena, rising to 420 Elo on the largest data subset, and outperforms AutoGluon 1.5 extreme while being 10x faster, without using LLMs, real data, internet search or any other model besides TabPFN. TabPFN-3 extends the capabilities of our models, enabling SOTA prediction on relational data (new SOTA foundation model on RelBenchV1) and tabular-text data (SOTA on TabSTAR via TabPFN-3-Plus); and improves existing integrations: a specialized checkpoint, TabPFN-TS-3, ranks 2nd on the time-series benchmark fev-bench, and SHAP-value computation is up to 120x faster. TabPFN-3 achieves this performance while being up to 20x faster than TabPFN-2.5. In addition, a reduced KV cache and row-chunking scale to 1M rows on one H100 with fast inference speed.
Impermanent: A Live Benchmark for Temporal Generalization in Time Series Forecasting
Mar 10, 2026Recent advances in time-series forecasting increasingly rely on pre-trained foundation-style models. While these models often claim broad generalization, existing evaluation protocols provide limited evidence. Indeed, most current benchmarks use static train-test splits that can easily lead to contamination as foundation models can inadvertently train on test data or perform model selection using test scores, which can inflate performance. We introduce Impermanent, a live benchmark that evaluates forecasting models under open-world temporal change by scoring forecasts sequentially over time on continuously updated data streams, enabling the study of temporal robustness, distributional shift, and performance stability rather than one-off accuracy on a frozen test set. Impermanent is instantiated on GitHub open-source activity, providing a naturally live and highly non-stationary dataset shaped by releases, shifting contributor behavior, platform/tooling changes, and external events. We focus on the top 400 repositories by star count and construct time series from issues opened, pull requests opened, push events, and new stargazers, evaluated over a rolling window with daily updates, alongside standardized protocols and leaderboards for reproducible, ongoing comparison. By shifting evaluation from static accuracy to sustained performance, Impermanent takes a concrete step toward assessing when and whether foundation-level generalization in time-series forecasting can be meaningfully claimed. Code and a live dashboard are available at https://github.com/TimeCopilot/impermanent and https://impermanent.timecopilot.dev.
Multi-Objective Hierarchical Optimization with Large Language Models
Jan 20, 2026Despite their widespread adoption in various domains, especially due to their powerful reasoning capabilities, Large Language Models (LLMs) are not the off-the-shelf choice to drive multi-objective optimization yet. Conventional strategies rank high in benchmarks due to their intrinsic capabilities to handle numerical inputs and careful modelling choices that balance exploration and Pareto-front exploitation, as well as handle multiple (conflicting) objectives. In this paper, we close this gap by leveraging LLMs as surrogate models and candidate samplers inside a structured hierarchical search strategy. By adaptively partitioning the input space into disjoint hyperrectangular regions and ranking them with a composite score function, we restrict the generative process of the LLM to specific, high-potential sub-spaces, hence making the problem easier to solve as the LLM doesn't have to reason about the global structure of the problem, but only locally instead. We show that under standard regularity assumptions, our algorithm generates candidate solutions that converge to the true Pareto set in Hausdorff distance. Empirically, it consistently outperforms the global LLM-based multi-objective optimizer and is on par with standard evolutionary and Bayesian optimization algorithm on synthetic and real-world benchmarks.
Open-sci-ref-0.01: open and reproducible reference baselines for language model and dataset comparison
Sep 10, 2025We introduce open-sci-ref, a family of dense transformer models trained as research baselines across multiple model (0.13B to 1.7B parameters) and token scales (up to 1T) on 8 recent open reference datasets. Evaluating the models on various standardized benchmarks, our training runs set establishes reference points that enable researchers to assess the sanity and quality of alternative training approaches across scales and datasets. Intermediate checkpoints allow comparison and studying of the training dynamics. The established reference baselines allow training procedures to be compared through their scaling trends, aligning them on a common compute axis. Comparison of open reference datasets reveals that training on NemoTron-CC HQ consistently outperforms other reference datasets, followed by DCLM-baseline and FineWeb-Edu. In addition to intermediate training checkpoints, the release includes logs, code, and downstream evaluations to simplify reproduction, standardize comparison, and facilitate future research.
Improving LLM-based Global Optimization with Search Space Partitioning
May 27, 2025



Large Language Models (LLMs) have recently emerged as effective surrogate models and candidate generators within global optimization frameworks for expensive blackbox functions. Despite promising results, LLM-based methods often struggle in high-dimensional search spaces or when lacking domain-specific priors, leading to sparse or uninformative suggestions. To overcome these limitations, we propose HOLLM, a novel global optimization algorithm that enhances LLM-driven sampling by partitioning the search space into promising subregions. Each subregion acts as a ``meta-arm'' selected via a bandit-inspired scoring mechanism that effectively balances exploration and exploitation. Within each selected subregion, an LLM then proposes high-quality candidate points, without any explicit domain knowledge. Empirical evaluation on standard optimization benchmarks shows that HOLLM consistently matches or surpasses leading Bayesian optimization and trust-region methods, while substantially outperforming global LLM-based sampling strategies.
EquiTabPFN: A Target-Permutation Equivariant Prior Fitted Networks
Feb 10, 2025Recent foundational models for tabular data, such as TabPFN, have demonstrated remarkable effectiveness in adapting to new tasks through in-context learning. However, these models overlook a crucial equivariance property: the arbitrary ordering of target dimensions should not influence model predictions. In this study, we identify this oversight as a source of incompressible error, termed the equivariance gap, which introduces instability in predictions. To mitigate these issues, we propose a novel model designed to preserve equivariance across output dimensions. Our experimental results indicate that our proposed model not only addresses these pitfalls effectively but also achieves competitive benchmark performance.
The Tabular Foundation Model TabPFN Outperforms Specialized Time Series Forecasting Models Based on Simple Features
Jan 06, 2025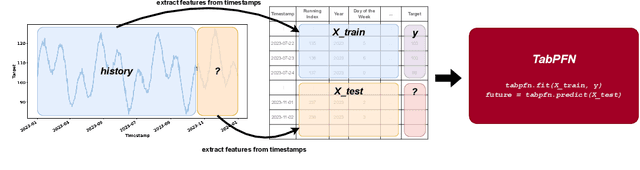

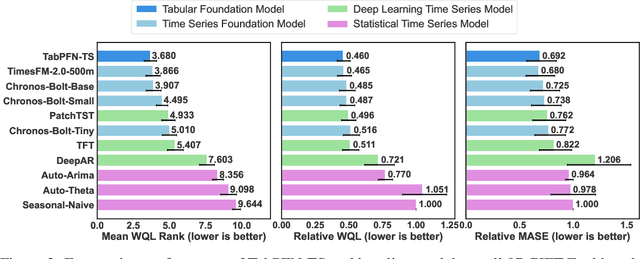
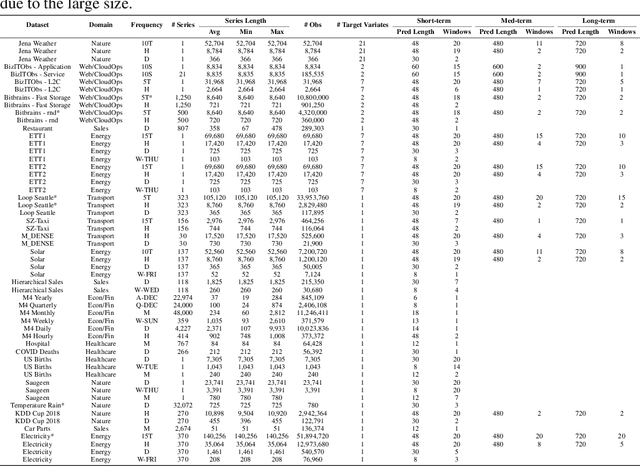
Foundation models have become popular in forecasting due to their ability to make accurate predictions, even with minimal fine-tuning on specific datasets. In this paper, we demonstrate how the newly released regression variant of TabPFN, a general tabular foundation model, can be applied to time series forecasting. We propose a straightforward approach, TabPFN-TS, which pairs TabPFN with simple feature engineering to achieve strong forecasting performance. Despite its simplicity and with only 11M parameters, TabPFN-TS outperforms Chronos-Mini, a model of similar size, and matches or even slightly outperforms Chronos-Large, which has 65-fold more parameters. A key strength of our method lies in its reliance solely on artificial data during pre-training, avoiding the need for large training datasets and eliminating the risk of benchmark contamination.
Mamba4Cast: Efficient Zero-Shot Time Series Forecasting with State Space Models
Oct 12, 2024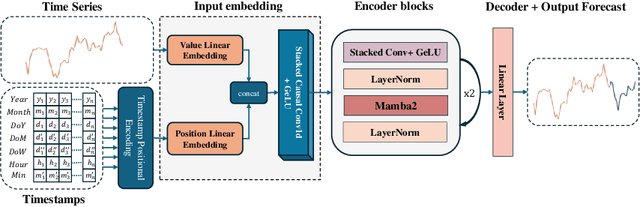
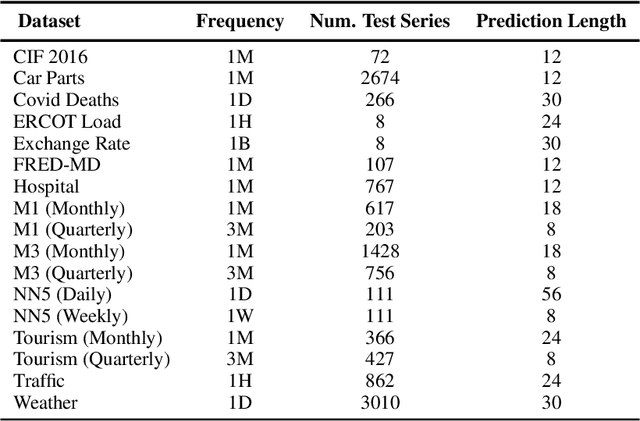
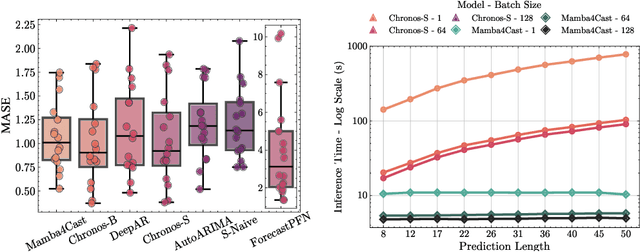
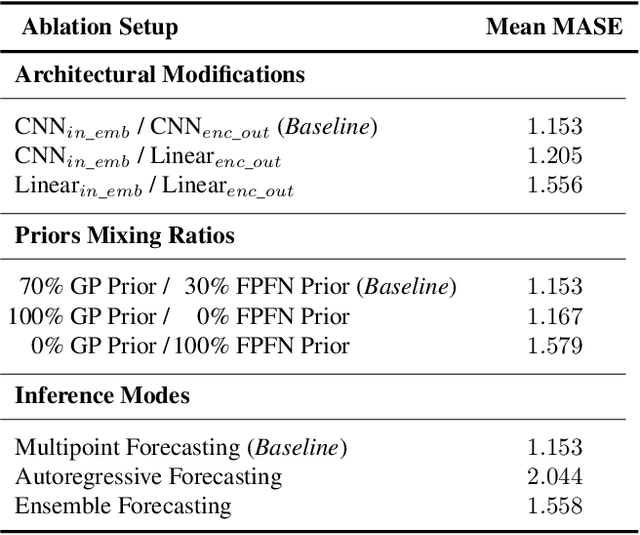
This paper introduces Mamba4Cast, a zero-shot foundation model for time series forecasting. Based on the Mamba architecture and inspired by Prior-data Fitted Networks (PFNs), Mamba4Cast generalizes robustly across diverse time series tasks without the need for dataset specific fine-tuning. Mamba4Cast's key innovation lies in its ability to achieve strong zero-shot performance on real-world datasets while having much lower inference times than time series foundation models based on the transformer architecture. Trained solely on synthetic data, the model generates forecasts for entire horizons in a single pass, outpacing traditional auto-regressive approaches. Our experiments show that Mamba4Cast performs competitively against other state-of-the-art foundation models in various data sets while scaling significantly better with the prediction length. The source code can be accessed at https://github.com/automl/Mamba4Cast.