 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning State-Tracking from Code Using Linear RNNs
Feb 16, 2026Over the last years, state-tracking tasks, particularly permutation composition, have become a testbed to understand the limits of sequence models architectures like Transformers and RNNs (linear and non-linear). However, these are often sequence-to-sequence tasks: learning to map actions (permutations) to states, which is incompatible with the next-token prediction setting commonly used to train language models. We address this gap by converting permutation composition into code via REPL traces that interleave state-reveals through prints and variable transformations. We show that linear RNNs capable of state-tracking excel also in this setting, while Transformers still fail. Motivated by this representation, we investigate why tracking states in code is generally difficult: actions are not always fully observable. We frame this as tracking the state of a probabilistic finite-state automaton with deterministic state reveals and show that linear RNNs can be worse than non-linear RNNs at tracking states in this setup.
Unlocking State-Tracking in Linear RNNs Through Negative Eigenvalues
Nov 19, 2024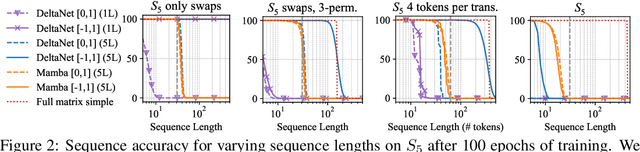
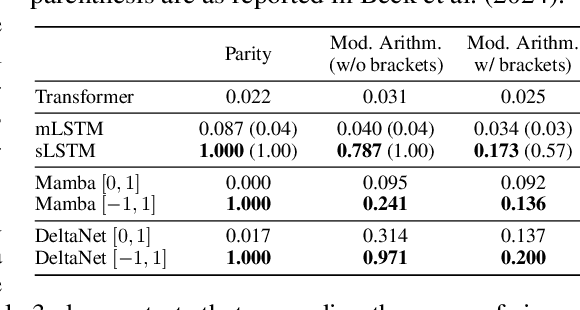
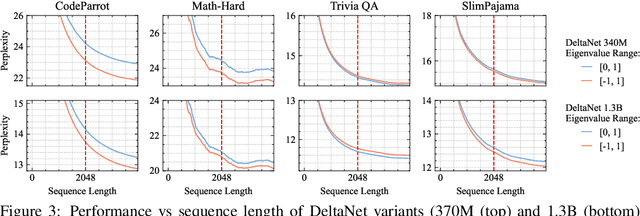
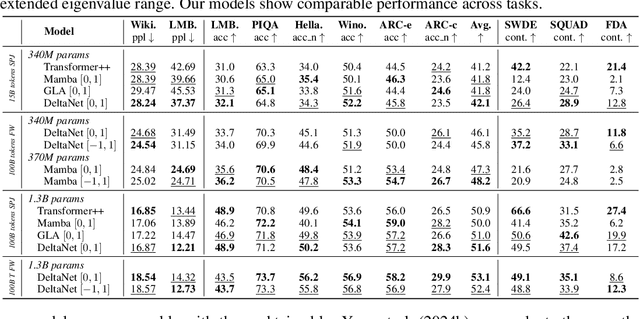
Linear Recurrent Neural Networks (LRNNs) such as Mamba, RWKV, GLA, mLSTM, and DeltaNet have emerged as efficient alternatives to Transformers in large language modeling, offering linear scaling with sequence length and improved training efficiency. However, LRNNs struggle to perform state-tracking which may impair performance in tasks such as code evaluation or tracking a chess game. Even parity, the simplest state-tracking task, which non-linear RNNs like LSTM handle effectively, cannot be solved by current LRNNs. Recently, Sarrof et al. (2024) demonstrated that the failure of LRNNs like Mamba to solve parity stems from restricting the value range of their diagonal state-transition matrices to $[0, 1]$ and that incorporating negative values can resolve this issue. We extend this result to non-diagonal LRNNs, which have recently shown promise in models such as DeltaNet. We prove that finite precision LRNNs with state-transition matrices having only positive eigenvalues cannot solve parity, while complex eigenvalues are needed to count modulo $3$. Notably, we also prove that LRNNs can learn any regular language when their state-transition matrices are products of identity minus vector outer product matrices, each with eigenvalues in the range $[-1, 1]$. Our empirical results confirm that extending the eigenvalue range of models like Mamba and DeltaNet to include negative values not only enables them to solve parity but consistently improves their performance on state-tracking tasks. Furthermore, pre-training LRNNs with an extended eigenvalue range for language modeling achieves comparable performance and stability while showing promise on code and math data. Our work enhances the expressivity of modern LRNNs, broadening their applicability without changing the cost of training or inference.
Mamba4Cast: Efficient Zero-Shot Time Series Forecasting with State Space Models
Oct 12, 2024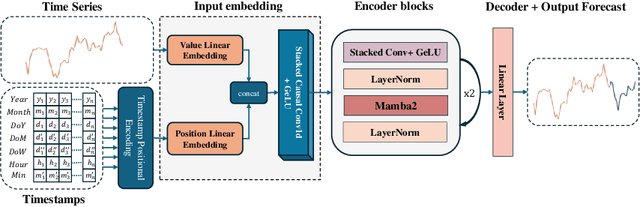
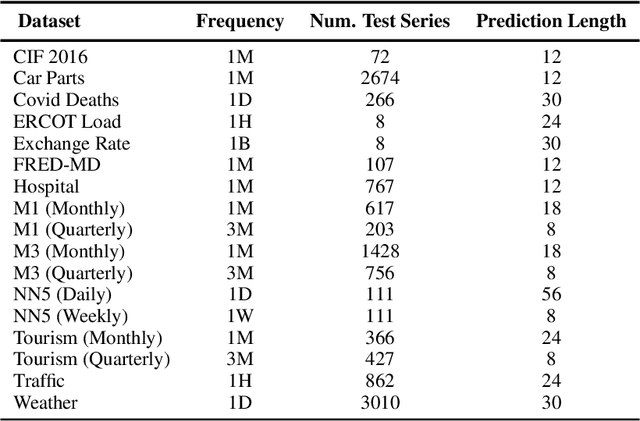
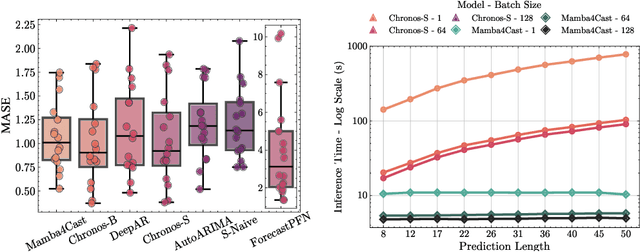
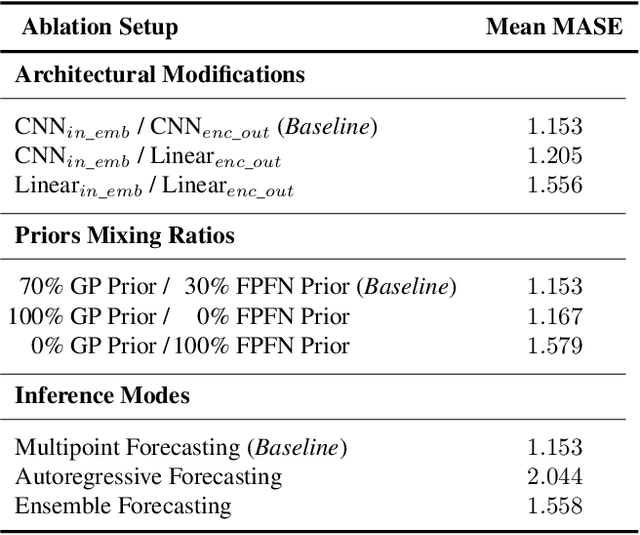
This paper introduces Mamba4Cast, a zero-shot foundation model for time series forecasting. Based on the Mamba architecture and inspired by Prior-data Fitted Networks (PFNs), Mamba4Cast generalizes robustly across diverse time series tasks without the need for dataset specific fine-tuning. Mamba4Cast's key innovation lies in its ability to achieve strong zero-shot performance on real-world datasets while having much lower inference times than time series foundation models based on the transformer architecture. Trained solely on synthetic data, the model generates forecasts for entire horizons in a single pass, outpacing traditional auto-regressive approaches. Our experiments show that Mamba4Cast performs competitively against other state-of-the-art foundation models in various data sets while scaling significantly better with the prediction length. The source code can be accessed at https://github.com/automl/Mamba4Cast.
GAMformer: In-Context Learning for Generalized Additive Models
Oct 06, 2024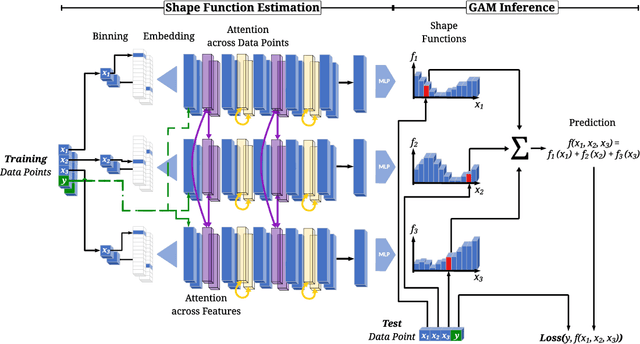
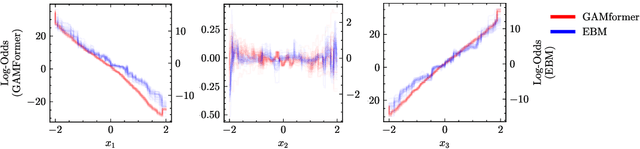

Generalized Additive Models (GAMs) are widely recognized for their ability to create fully interpretable machine learning models for tabular data. Traditionally, training GAMs involves iterative learning algorithms, such as splines, boosted trees, or neural networks, which refine the additive components through repeated error reduction. In this paper, we introduce GAMformer, the first method to leverage in-context learning to estimate shape functions of a GAM in a single forward pass, representing a significant departure from the conventional iterative approaches to GAM fitting. Building on previous research applying in-context learning to tabular data, we exclusively use complex, synthetic data to train GAMformer, yet find it extrapolates well to real-world data. Our experiments show that GAMformer performs on par with other leading GAMs across various classification benchmarks while generating highly interpretable shape functions.
Is Mamba Capable of In-Context Learning?
Feb 05, 2024



This work provides empirical evidence that Mamba, a newly proposed selective structured state space model, has similar in-context learning (ICL) capabilities as transformers. We evaluated Mamba on tasks involving simple function approximation as well as more complex natural language processing problems. Our results demonstrate that across both categories of tasks, Mamba matches the performance of transformer models for ICL. Further analysis reveals that like transformers, Mamba appears to solve ICL problems by incrementally optimizing its internal representations. Overall, our work suggests that Mamba can be an efficient alternative to transformers for ICL tasks involving longer input sequences.
Curve Your Enthusiasm: Concurvity Regularization in Differentiable Generalized Additive Models
May 19, 2023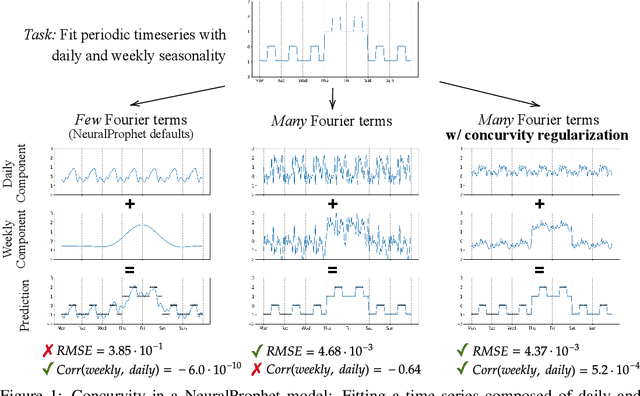

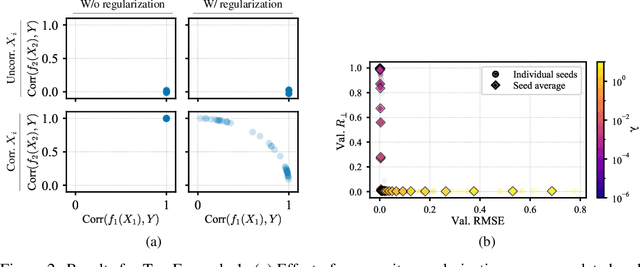
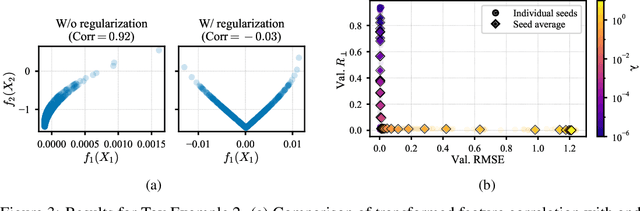
Generalized Additive Models (GAMs) have recently experienced a resurgence in popularity due to their interpretability, which arises from expressing the target value as a sum of non-linear transformations of the features. Despite the current enthusiasm for GAMs, their susceptibility to concurvity - i.e., (possibly non-linear) dependencies between the features - has hitherto been largely overlooked. Here, we demonstrate how concurvity can severly impair the interpretability of GAMs and propose a remedy: a conceptually simple, yet effective regularizer which penalizes pairwise correlations of the non-linearly transformed feature variables. This procedure is applicable to any differentiable additive model, such as Neural Additive Models or NeuralProphet, and enhances interpretability by eliminating ambiguities due to self-canceling feature contributions. We validate the effectiveness of our regularizer in experiments on synthetic as well as real-world datasets for time-series and tabular data. Our experiments show that concurvity in GAMs can be reduced without significantly compromising prediction quality, improving interpretability and reducing variance in the feature importances.
Interpretable Reinforcement Learning via Neural Additive Models for Inventory Management
Mar 22, 2023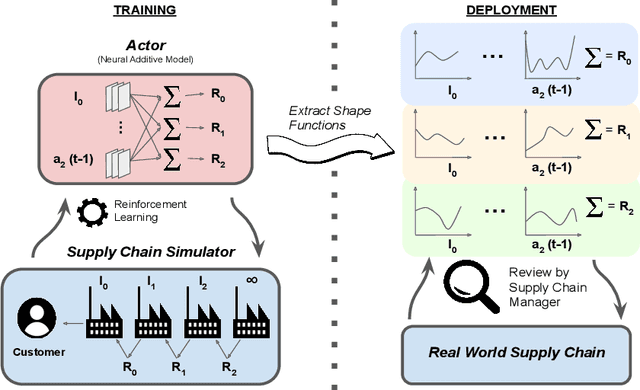
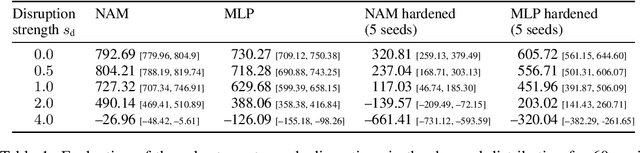
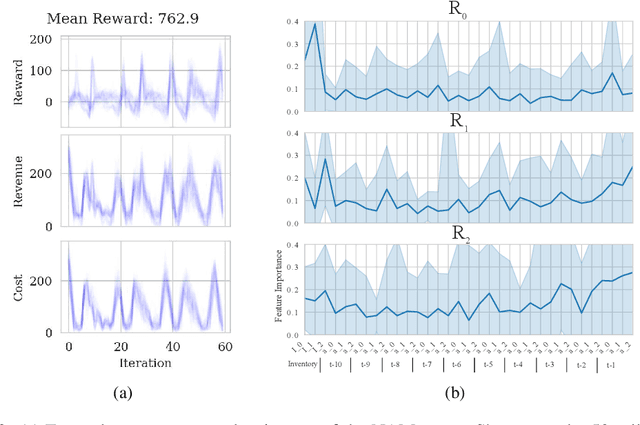
The COVID-19 pandemic has highlighted the importance of supply chains and the role of digital management to react to dynamic changes in the environment. In this work, we focus on developing dynamic inventory ordering policies for a multi-echelon, i.e. multi-stage, supply chain. Traditional inventory optimization methods aim to determine a static reordering policy. Thus, these policies are not able to adjust to dynamic changes such as those observed during the COVID-19 crisis. On the other hand, conventional strategies offer the advantage of being interpretable, which is a crucial feature for supply chain managers in order to communicate decisions to their stakeholders. To address this limitation, we propose an interpretable reinforcement learning approach that aims to be as interpretable as the traditional static policies while being as flexible and environment-agnostic as other deep learning-based reinforcement learning solutions. We propose to use Neural Additive Models as an interpretable dynamic policy of a reinforcement learning agent, showing that this approach is competitive with a standard full connected policy. Finally, we use the interpretability property to gain insights into a complex ordering strategy for a simple, linear three-echelon inventory supply chain.
Bayesian Optimization-based Combinatorial Assignment
Aug 31, 2022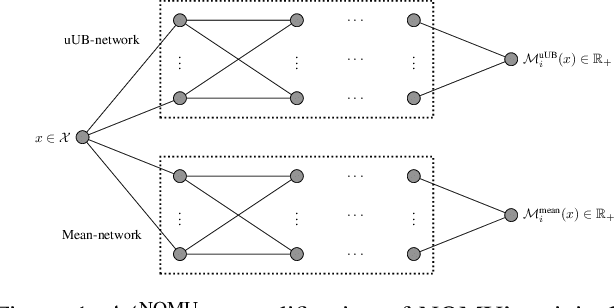

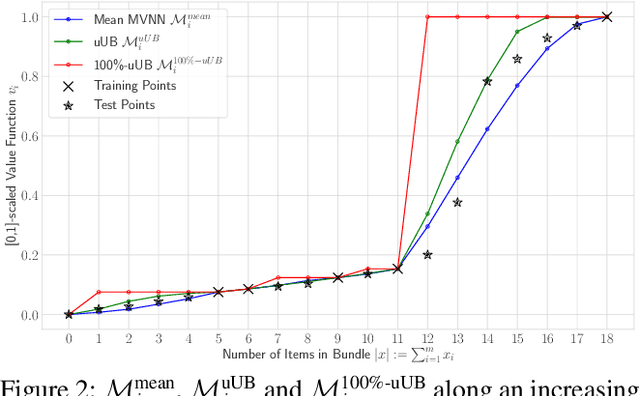

We study the combinatorial assignment domain, which includes combinatorial auctions and course allocation. The main challenge in this domain is that the bundle space grows exponentially in the number of items. To address this, several papers have recently proposed machine learning-based preference elicitation algorithms that aim to elicit only the most important information from agents. However, the main shortcoming of this prior work is that it does not model a mechanism's uncertainty over values for not yet elicited bundles. In this paper, we address this shortcoming by presenting a Bayesian Optimization-based Combinatorial Assignment (BOCA) mechanism. Our key technical contribution is to integrate a method for capturing model uncertainty into an iterative combinatorial auction mechanism. Concretely, we design a new method for estimating an upper uncertainty bound that can be used as an acquisition function to determine the next query to the agents. This enables the mechanism to properly explore (and not just exploit) the bundle space during its preference elicitation phase. We run computational experiments in several spectrum auction domains to evaluate BOCA's performance. Our results show that BOCA achieves higher allocative efficiency than state-of-the-art approaches.
NAS-Bench-301 and the Case for Surrogate Benchmarks for Neural Architecture Search
Aug 22, 2020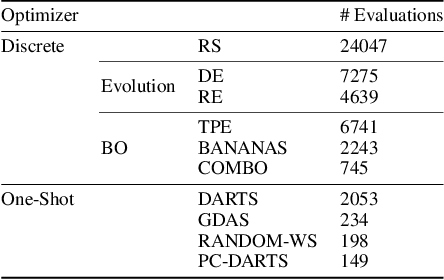
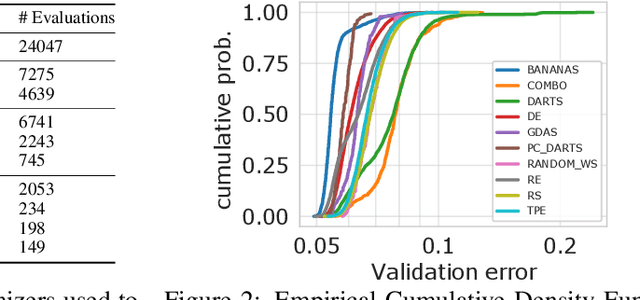
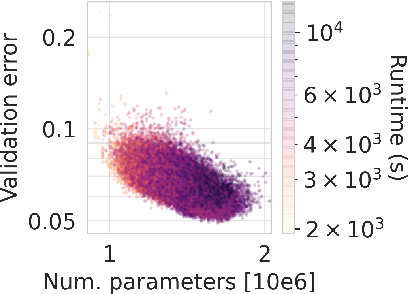
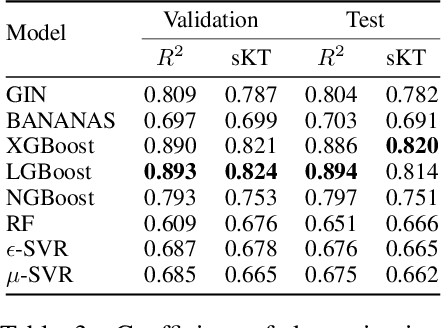
Neural Architecture Search (NAS) is a logical next step in the automatic learning of representations, but the development of NAS methods is slowed by high computational demands. As a remedy, several tabular NAS benchmarks were proposed to simulate runs of NAS methods in seconds. However, all existing NAS benchmarks are limited to extremely small architectural spaces since they rely on exhaustive evaluations of the space. This leads to unrealistic results, such as a strong performance of local search and random search, that do not transfer to larger search spaces. To overcome this fundamental limitation, we propose NAS-Bench-301, the first model-based surrogate NAS benchmark, using a search space containing $10^{18}$ architectures, orders of magnitude larger than any previous NAS benchmark. We first motivate the benefits of using such a surrogate benchmark compared to a tabular one by smoothing out the noise stemming from the stochasticity of single SGD runs in a tabular benchmark. Then, we analyze our new dataset consisting of architecture evaluations and comprehensively evaluate various regression models as surrogates to demonstrate their capability to model the architecture space, also using deep ensembles to model uncertainty. Finally, we benchmark a wide range of NAS algorithms using NAS-Bench-301 allowing us to obtain comparable results to the true benchmark at a fraction of the cost.
NAS-Bench-1Shot1: Benchmarking and Dissecting One-shot Neural Architecture Search
Jan 28, 2020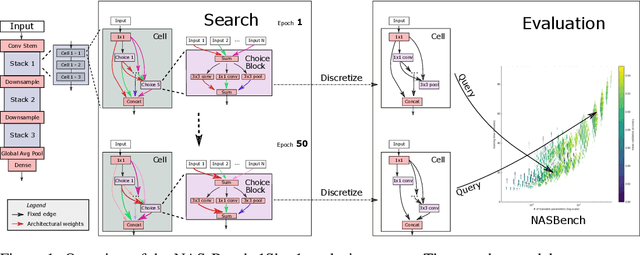
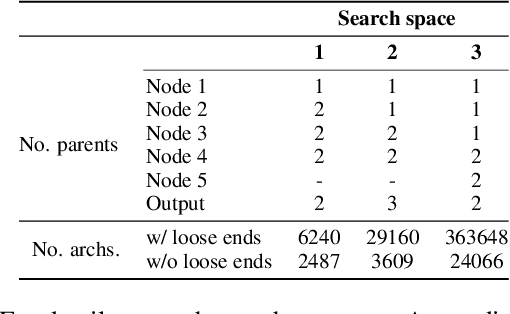
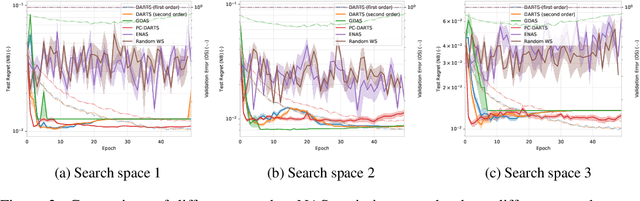
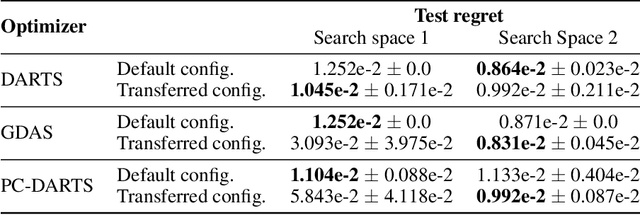
One-shot neural architecture search (NAS) has played a crucial role in making NAS methods computationally feasible in practice. Nevertheless, there is still a lack of understanding on how these weight-sharing algorithms exactly work due to the many factors controlling the dynamics of the process. In order to allow a scientific study of these components, we introduce a general framework for one-shot NAS that can be instantiated to many recently-introduced variants and introduce a general benchmarking framework that draws on the recent large-scale tabular benchmark NAS-Bench-101 for cheap anytime evaluations of one-shot NAS methods. To showcase the framework, we compare several state-of-the-art one-shot NAS methods, examine how sensitive they are to their hyperparameters and how they can be improved by tuning their hyperparameters, and compare their performance to that of blackbox optimizers for NAS-Bench-101.