 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple LLM Baselines are Competitive for Model Diffing
Feb 10, 2026Standard LLM evaluations only test capabilities or dispositions that evaluators designed them for, missing unexpected differences such as behavioral shifts between model revisions or emergent misaligned tendencies. Model diffing addresses this limitation by automatically surfacing systematic behavioral differences. Recent approaches include LLM-based methods that generate natural language descriptions and sparse autoencoder (SAE)-based methods that identify interpretable features. However, no systematic comparison of these approaches exists nor are there established evaluation criteria. We address this gap by proposing evaluation metrics for key desiderata (generalization, interestingness, and abstraction level) and use these to compare existing methods. Our results show that an improved LLM-based baseline performs comparably to the SAE-based method while typically surfacing more abstract behavioral differences.
When and How Does CLIP Enable Domain and Compositional Generalization?
Feb 13, 2025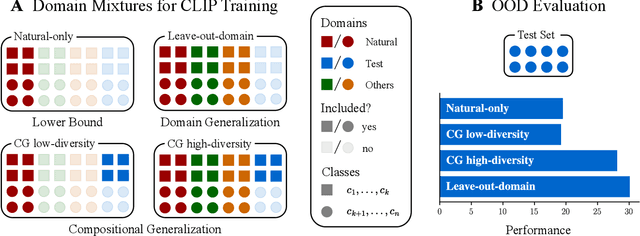

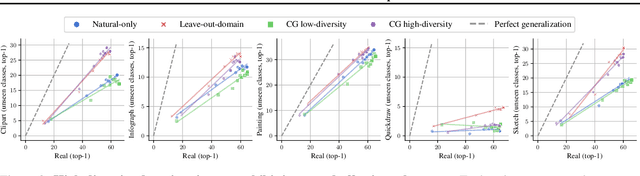

The remarkable generalization performance of contrastive vision-language models like CLIP is often attributed to the diversity of their training distributions. However, key questions remain unanswered: Can CLIP generalize to an entirely unseen domain when trained on a diverse mixture of domains (domain generalization)? Can it generalize to unseen classes within partially seen domains (compositional generalization)? What factors affect such generalization? To answer these questions, we trained CLIP models on systematically constructed training distributions with controlled domain diversity and object class exposure. Our experiments show that domain diversity is essential for both domain and compositional generalization, yet compositional generalization can be surprisingly weaker than domain generalization when the training distribution contains a suboptimal subset of the test domain. Through data-centric and mechanistic analyses, we find that successful generalization requires learning of shared representations already in intermediate layers and shared circuitry.
Concept Bottleneck Models Without Predefined Concepts
Jul 04, 2024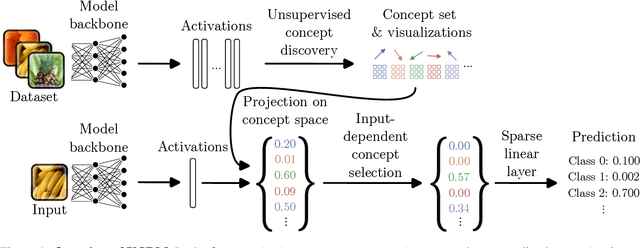

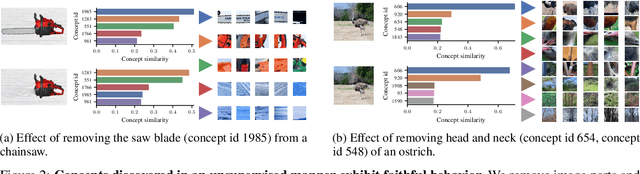

There has been considerable recent interest in interpretable concept-based models such as Concept Bottleneck Models (CBMs), which first predict human-interpretable concepts and then map them to output classes. To reduce reliance on human-annotated concepts, recent works have converted pretrained black-box models into interpretable CBMs post-hoc. However, these approaches predefine a set of concepts, assuming which concepts a black-box model encodes in its representations. In this work, we eliminate this assumption by leveraging unsupervised concept discovery to automatically extract concepts without human annotations or a predefined set of concepts. We further introduce an input-dependent concept selection mechanism that ensures only a small subset of concepts is used across all classes. We show that our approach improves downstream performance and narrows the performance gap to black-box models, while using significantly fewer concepts in the classification. Finally, we demonstrate how large vision-language models can intervene on the final model weights to correct model errors.
Two Effects, One Trigger: On the Modality Gap, Object Bias, and Information Imbalance in Contrastive Vision-Language Representation Learning
Apr 11, 2024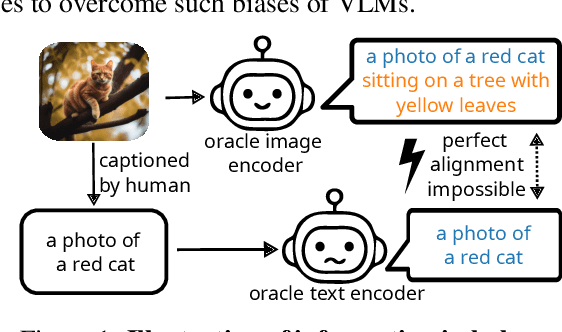



Contrastive vision-language models like CLIP have gained popularity for their versatile applicable learned representations in various downstream tasks. Despite their successes in some tasks, like zero-shot image recognition, they also perform surprisingly poor on other tasks, like attribute detection. Previous work has attributed these challenges to the modality gap, a separation of image and text in the shared representation space, and a bias towards objects over other factors, such as attributes. In this work we investigate both phenomena. We find that only a few embedding dimensions drive the modality gap. Further, we propose a measure for object bias and find that object bias does not lead to worse performance on other concepts, such as attributes. But what leads to the emergence of the modality gap and object bias? To answer this question we carefully designed an experimental setting which allows us to control the amount of shared information between the modalities. This revealed that the driving factor behind both, the modality gap and the object bias, is the information imbalance between images and captions.
Is Mamba Capable of In-Context Learning?
Feb 05, 2024



This work provides empirical evidence that Mamba, a newly proposed selective structured state space model, has similar in-context learning (ICL) capabilities as transformers. We evaluated Mamba on tasks involving simple function approximation as well as more complex natural language processing problems. Our results demonstrate that across both categories of tasks, Mamba matches the performance of transformer models for ICL. Further analysis reveals that like transformers, Mamba appears to solve ICL problems by incrementally optimizing its internal representations. Overall, our work suggests that Mamba can be an efficient alternative to transformers for ICL tasks involving longer input sequences.
Eureka-Moments in Transformers: Multi-Step Tasks Reveal Softmax Induced Optimization Problems
Oct 19, 2023



In this work, we study rapid, step-wise improvements of the loss in transformers when being confronted with multi-step decision tasks. We found that transformers struggle to learn the intermediate tasks, whereas CNNs have no such issue on the tasks we studied. When transformers learn the intermediate task, they do this rapidly and unexpectedly after both training and validation loss saturated for hundreds of epochs. We call these rapid improvements Eureka-moments, since the transformer appears to suddenly learn a previously incomprehensible task. Similar leaps in performance have become known as Grokking. In contrast to Grokking, for Eureka-moments, both the validation and the training loss saturate before rapidly improving. We trace the problem back to the Softmax function in the self-attention block of transformers and show ways to alleviate the problem. These fixes improve training speed. The improved models reach 95% of the baseline model in just 20% of training steps while having a much higher likelihood to learn the intermediate task, lead to higher final accuracy and are more robust to hyper-parameters.
Latent Diffusion Counterfactual Explanations
Oct 10, 2023



Counterfactual explanations have emerged as a promising method for elucidating the behavior of opaque black-box models. Recently, several works leveraged pixel-space diffusion models for counterfactual generation. To handle noisy, adversarial gradients during counterfactual generation -- causing unrealistic artifacts or mere adversarial perturbations -- they required either auxiliary adversarially robust models or computationally intensive guidance schemes. However, such requirements limit their applicability, e.g., in scenarios with restricted access to the model's training data. To address these limitations, we introduce Latent Diffusion Counterfactual Explanations (LDCE). LDCE harnesses the capabilities of recent class- or text-conditional foundation latent diffusion models to expedite counterfactual generation and focus on the important, semantic parts of the data. Furthermore, we propose a novel consensus guidance mechanism to filter out noisy, adversarial gradients that are misaligned with the diffusion model's implicit classifier. We demonstrate the versatility of LDCE across a wide spectrum of models trained on diverse datasets with different learning paradigms. Finally, we showcase how LDCE can provide insights into model errors, enhancing our understanding of black-box model behavior.
Climate-sensitive Urban Planning through Optimization of Tree Placements
Oct 09, 2023



Climate change is increasing the intensity and frequency of many extreme weather events, including heatwaves, which results in increased thermal discomfort and mortality rates. While global mitigation action is undoubtedly necessary, so is climate adaptation, e.g., through climate-sensitive urban planning. Among the most promising strategies is harnessing the benefits of urban trees in shading and cooling pedestrian-level environments. Our work investigates the challenge of optimal placement of such trees. Physical simulations can estimate the radiative and thermal impact of trees on human thermal comfort but induce high computational costs. This rules out optimization of tree placements over large areas and considering effects over longer time scales. Hence, we employ neural networks to simulate the point-wise mean radiant temperatures--a driving factor of outdoor human thermal comfort--across various time scales, spanning from daily variations to extended time scales of heatwave events and even decades. To optimize tree placements, we harness the innate local effect of trees within the iterated local search framework with tailored adaptations. We show the efficacy of our approach across a wide spectrum of study areas and time scales. We believe that our approach is a step towards empowering decision-makers, urban designers and planners to proactively and effectively assess the potential of urban trees to mitigate heat stress.
Towards Discovering Neural Architectures from Scratch
Nov 03, 2022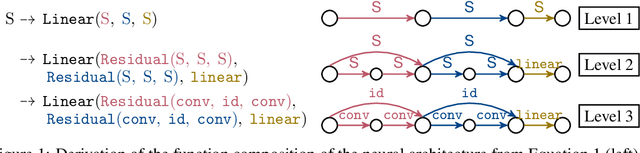
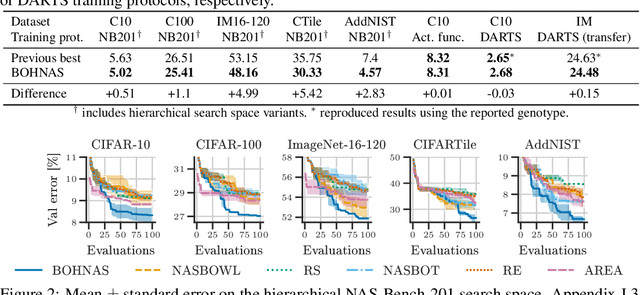
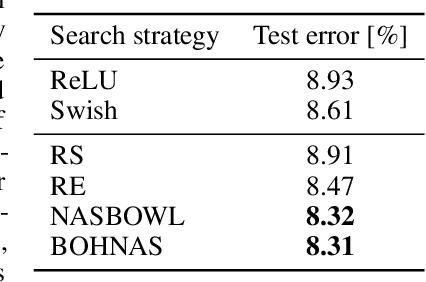
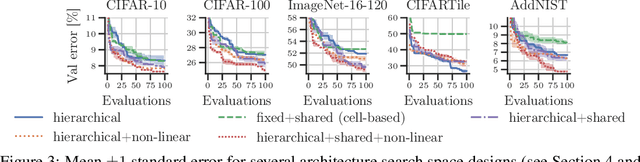
The discovery of neural architectures from scratch is the long-standing goal of Neural Architecture Search (NAS). Searching over a wide spectrum of neural architectures can facilitate the discovery of previously unconsidered but well-performing architectures. In this work, we take a large step towards discovering neural architectures from scratch by expressing architectures algebraically. This algebraic view leads to a more general method for designing search spaces, which allows us to compactly represent search spaces that are 100s of orders of magnitude larger than common spaces from the literature. Further, we propose a Bayesian Optimization strategy to efficiently search over such huge spaces, and demonstrate empirically that both our search space design and our search strategy can be superior to existing baselines. We open source our algebraic NAS approach and provide APIs for PyTorch and TensorFlow.
Bag of Baselines for Multi-objective Joint Neural Architecture Search and Hyperparameter Optimization
May 03, 2021
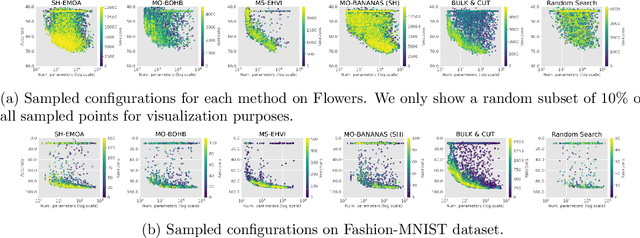
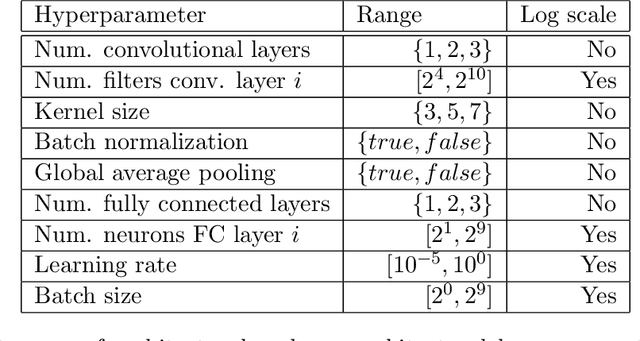
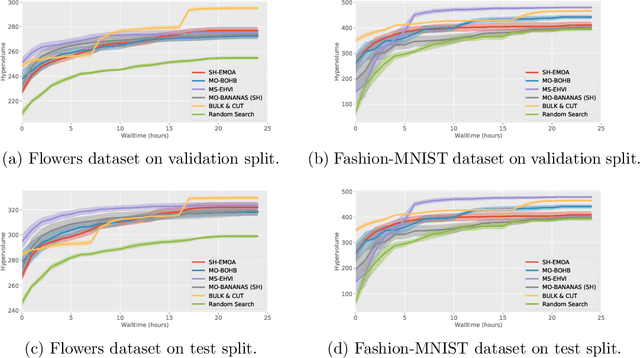
Neural architecture search (NAS) and hyperparameter optimization (HPO) make deep learning accessible to non-experts by automatically finding the architecture of the deep neural network to use and tuning the hyperparameters of the used training pipeline. While both NAS and HPO have been studied extensively in recent years, NAS methods typically assume fixed hyperparameters and vice versa - there exists little work on joint NAS + HPO. Furthermore, NAS has recently often been framed as a multi-objective optimization problem, in order to take, e.g., resource requirements into account. In this paper, we propose a set of methods that extend current approaches to jointly optimize neural architectures and hyperparameters with respect to multiple objectives. We hope that these methods will serve as simple baselines for future research on multi-objective joint NAS + HPO. To facilitate this, all our code is available at https://github.com/automl/multi-obj-baselines.