 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Optimisation of Functions on Graphs
Jun 08, 2023The increasing availability of graph-structured data motivates the task of optimising over functions defined on the node set of graphs. Traditional graph search algorithms can be applied in this case, but they may be sample-inefficient and do not make use of information about the function values; on the other hand, Bayesian optimisation is a class of promising black-box solvers with superior sample efficiency, but it has been scarcely been applied to such novel setups. To fill this gap, we propose a novel Bayesian optimisation framework that optimises over functions defined on generic, large-scale and potentially unknown graphs. Through the learning of suitable kernels on graphs, our framework has the advantage of adapting to the behaviour of the target function. The local modelling approach further guarantees the efficiency of our method. Extensive experiments on both synthetic and real-world graphs demonstrate the effectiveness of the proposed optimisation framework.
Bayesian Quadrature for Neural Ensemble Search
Mar 17, 2023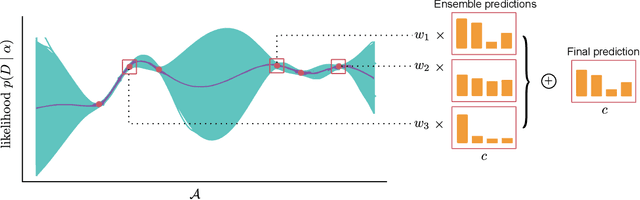

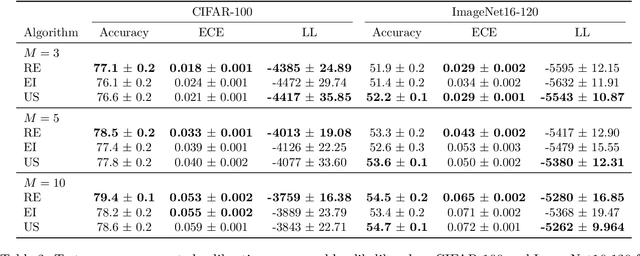
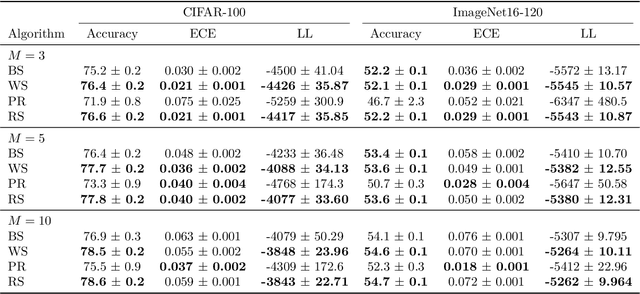
Ensembling can improve the performance of Neural Networks, but existing approaches struggle when the architecture likelihood surface has dispersed, narrow peaks. Furthermore, existing methods construct equally weighted ensembles, and this is likely to be vulnerable to the failure modes of the weaker architectures. By viewing ensembling as approximately marginalising over architectures we construct ensembles using the tools of Bayesian Quadrature -- tools which are well suited to the exploration of likelihood surfaces with dispersed, narrow peaks. Additionally, the resulting ensembles consist of architectures weighted commensurate with their performance. We show empirically -- in terms of test likelihood, accuracy, and expected calibration error -- that our method outperforms state-of-the-art baselines, and verify via ablation studies that its components do so independently.
Dynamic Ensemble of Low-fidelity Experts: Mitigating NAS "Cold-Start"
Feb 02, 2023Predictor-based Neural Architecture Search (NAS) employs an architecture performance predictor to improve the sample efficiency. However, predictor-based NAS suffers from the severe ``cold-start'' problem, since a large amount of architecture-performance data is required to get a working predictor. In this paper, we focus on exploiting information in cheaper-to-obtain performance estimations (i.e., low-fidelity information) to mitigate the large data requirements of predictor training. Despite the intuitiveness of this idea, we observe that using inappropriate low-fidelity information even damages the prediction ability and different search spaces have different preferences for low-fidelity information types. To solve the problem and better fuse beneficial information provided by different types of low-fidelity information, we propose a novel dynamic ensemble predictor framework that comprises two steps. In the first step, we train different sub-predictors on different types of available low-fidelity information to extract beneficial knowledge as low-fidelity experts. In the second step, we learn a gating network to dynamically output a set of weighting coefficients conditioned on each input neural architecture, which will be used to combine the predictions of different low-fidelity experts in a weighted sum. The overall predictor is optimized on a small set of actual architecture-performance data to fuse the knowledge from different low-fidelity experts to make the final prediction. We conduct extensive experiments across five search spaces with different architecture encoders under various experimental settings. Our method can easily be incorporated into existing predictor-based NAS frameworks to discover better architectures.
Neural Architecture Search: Insights from 1000 Papers
Jan 25, 2023



In the past decade, advances in deep learning have resulted in breakthroughs in a variety of areas, including computer vision, natural language understanding, speech recognition, and reinforcement learning. Specialized, high-performing neural architectures are crucial to the success of deep learning in these areas. Neural architecture search (NAS), the process of automating the design of neural architectures for a given task, is an inevitable next step in automating machine learning and has already outpaced the best human-designed architectures on many tasks. In the past few years, research in NAS has been progressing rapidly, with over 1000 papers released since 2020 (Deng and Lindauer, 2021). In this survey, we provide an organized and comprehensive guide to neural architecture search. We give a taxonomy of search spaces, algorithms, and speedup techniques, and we discuss resources such as benchmarks, best practices, other surveys, and open-source libraries.
Towards Discovering Neural Architectures from Scratch
Nov 03, 2022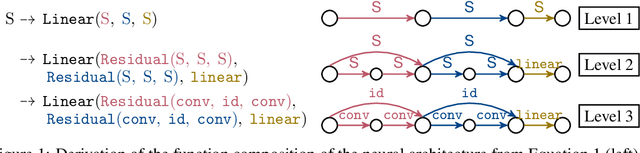
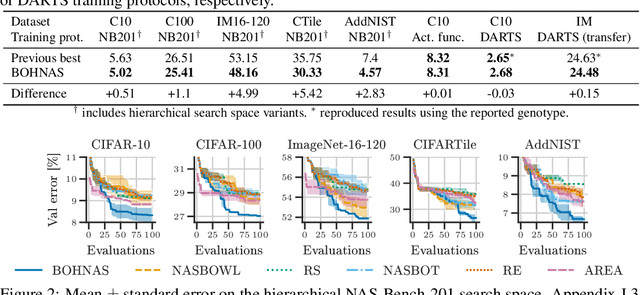
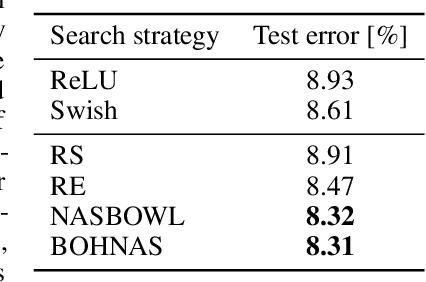
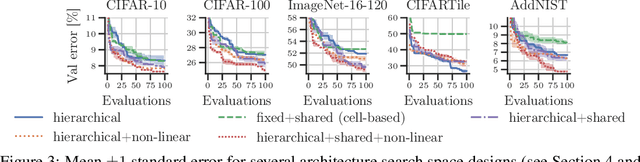
The discovery of neural architectures from scratch is the long-standing goal of Neural Architecture Search (NAS). Searching over a wide spectrum of neural architectures can facilitate the discovery of previously unconsidered but well-performing architectures. In this work, we take a large step towards discovering neural architectures from scratch by expressing architectures algebraically. This algebraic view leads to a more general method for designing search spaces, which allows us to compactly represent search spaces that are 100s of orders of magnitude larger than common spaces from the literature. Further, we propose a Bayesian Optimization strategy to efficiently search over such huge spaces, and demonstrate empirically that both our search space design and our search strategy can be superior to existing baselines. We open source our algebraic NAS approach and provide APIs for PyTorch and TensorFlow.
Bayesian Generational Population-Based Training
Jul 19, 2022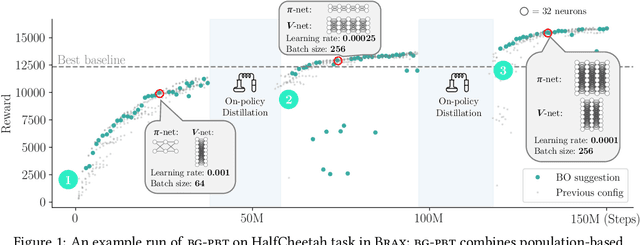

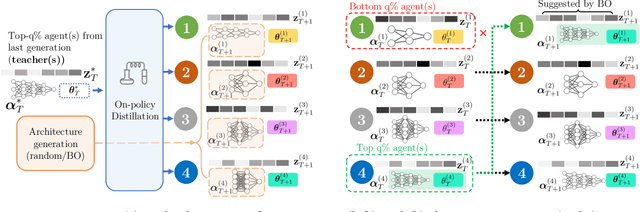
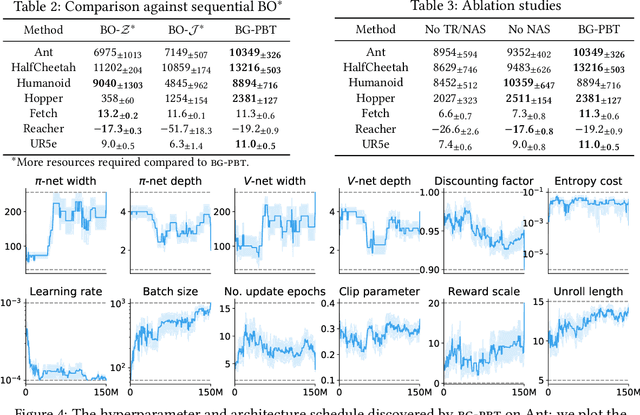
Reinforcement learning (RL) offers the potential for training generally capable agents that can interact autonomously in the real world. However, one key limitation is the brittleness of RL algorithms to core hyperparameters and network architecture choice. Furthermore, non-stationarities such as evolving training data and increased agent complexity mean that different hyperparameters and architectures may be optimal at different points of training. This motivates AutoRL, a class of methods seeking to automate these design choices. One prominent class of AutoRL methods is Population-Based Training (PBT), which have led to impressive performance in several large scale settings. In this paper, we introduce two new innovations in PBT-style methods. First, we employ trust-region based Bayesian Optimization, enabling full coverage of the high-dimensional mixed hyperparameter search space. Second, we show that using a generational approach, we can also learn both architectures and hyperparameters jointly on-the-fly in a single training run. Leveraging the new highly parallelizable Brax physics engine, we show that these innovations lead to large performance gains, significantly outperforming the tuned baseline while learning entire configurations on the fly. Code is available at https://github.com/xingchenwan/bgpbt.
On Redundancy and Diversity in Cell-based Neural Architecture Search
Mar 16, 2022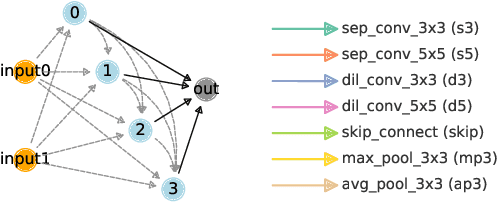
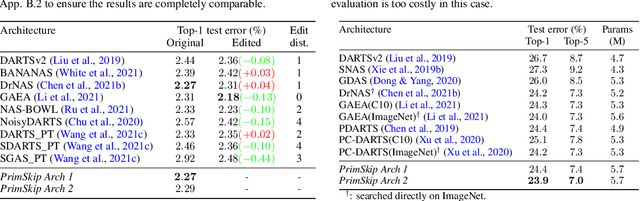
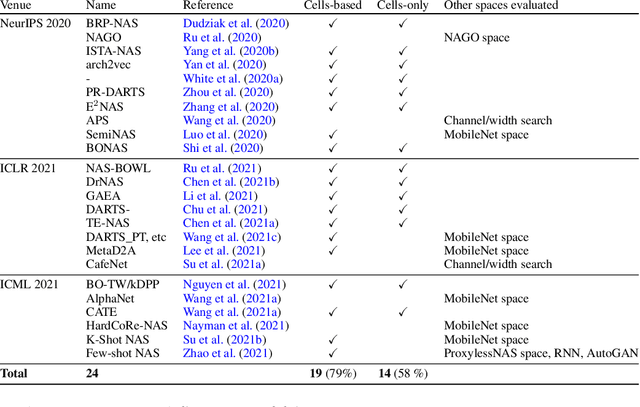

Searching for the architecture cells is a dominant paradigm in NAS. However, little attention has been devoted to the analysis of the cell-based search spaces even though it is highly important for the continual development of NAS. In this work, we conduct an empirical post-hoc analysis of architectures from the popular cell-based search spaces and find that the existing search spaces contain a high degree of redundancy: the architecture performance is minimally sensitive to changes at large parts of the cells, and universally adopted designs, like the explicit search for a reduction cell, significantly increase the complexities but have very limited impact on the performance. Across architectures found by a diverse set of search strategies, we consistently find that the parts of the cells that do matter for architecture performance often follow similar and simple patterns. By explicitly constraining cells to include these patterns, randomly sampled architectures can match or even outperform the state of the art. These findings cast doubts into our ability to discover truly novel architectures in the existing cell-based search spaces, and inspire our suggestions for improvement to guide future NAS research. Code is available at https://github.com/xingchenwan/cell-based-NAS-analysis.
Learning to Identify Top Elo Ratings: A Dueling Bandits Approach
Jan 20, 2022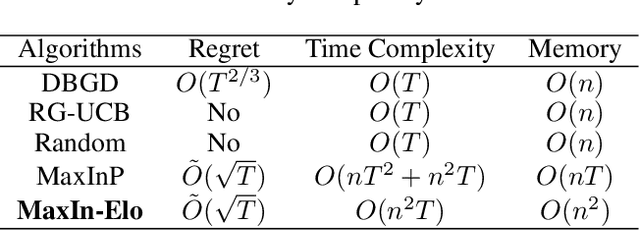
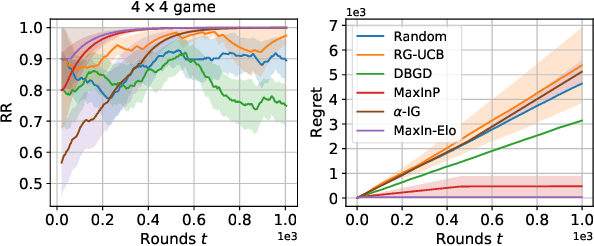
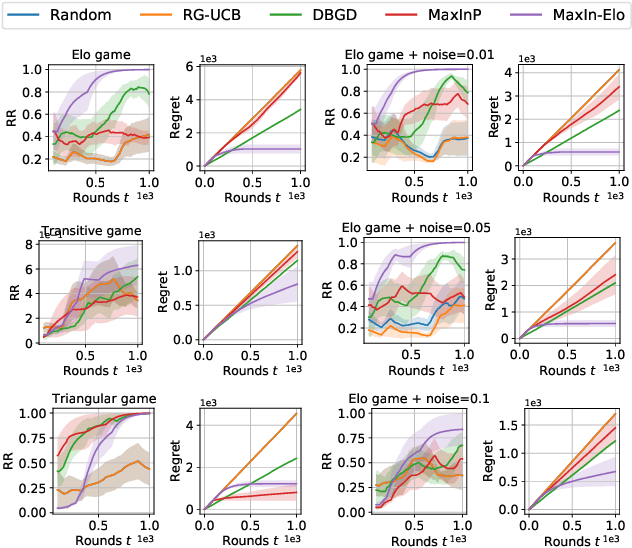
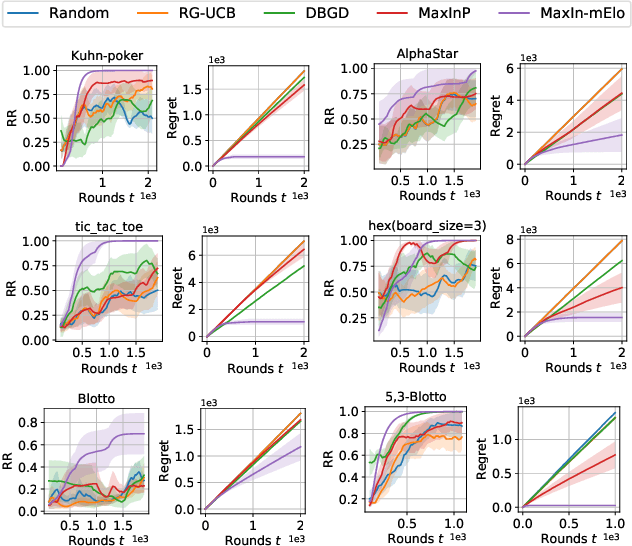
The Elo rating system is widely adopted to evaluate the skills of (chess) game and sports players. Recently it has been also integrated into machine learning algorithms in evaluating the performance of computerised AI agents. However, an accurate estimation of the Elo rating (for the top players) often requires many rounds of competitions, which can be expensive to carry out. In this paper, to improve the sample efficiency of the Elo evaluation (for top players), we propose an efficient online match scheduling algorithm. Specifically, we identify and match the top players through a dueling bandits framework and tailor the bandit algorithm to the gradient-based update of Elo. We show that it reduces the per-step memory and time complexity to constant, compared to the traditional likelihood maximization approaches requiring $O(t)$ time. Our algorithm has a regret guarantee of $\tilde{O}(\sqrt{T})$, sublinear in the number of competition rounds and has been extended to the multidimensional Elo ratings for handling intransitive games. We empirically demonstrate that our method achieves superior convergence speed and time efficiency on a variety of gaming tasks.
DARTS without a Validation Set: Optimizing the Marginal Likelihood
Dec 24, 2021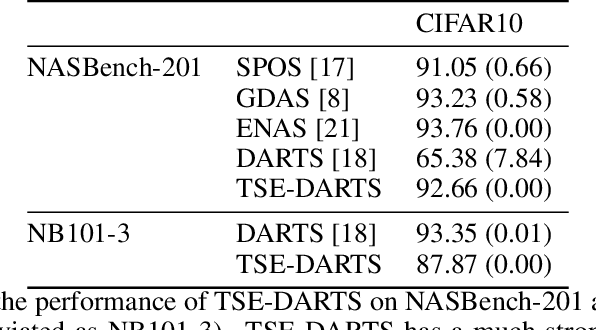
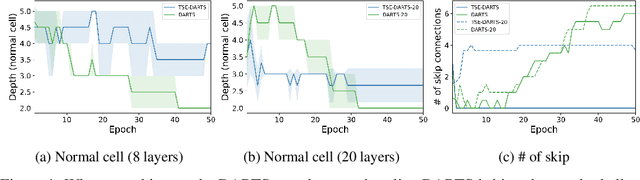
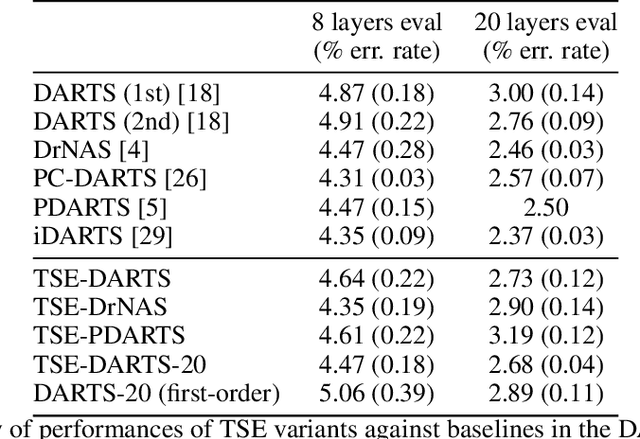
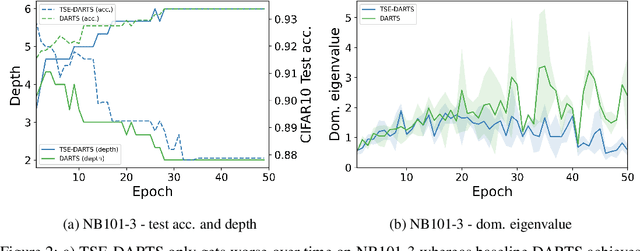
The success of neural architecture search (NAS) has historically been limited by excessive compute requirements. While modern weight-sharing NAS methods such as DARTS are able to finish the search in single-digit GPU days, extracting the final best architecture from the shared weights is notoriously unreliable. Training-Speed-Estimate (TSE), a recently developed generalization estimator with a Bayesian marginal likelihood interpretation, has previously been used in place of the validation loss for gradient-based optimization in DARTS. This prevents the DARTS skip connection collapse, which significantly improves performance on NASBench-201 and the original DARTS search space. We extend those results by applying various DARTS diagnostics and show several unusual behaviors arising from not using a validation set. Furthermore, our experiments yield concrete examples of the depth gap and topology selection in DARTS having a strongly negative impact on the search performance despite generally receiving limited attention in the literature compared to the operations selection.
Approximate Neural Architecture Search via Operation Distribution Learning
Nov 08, 2021
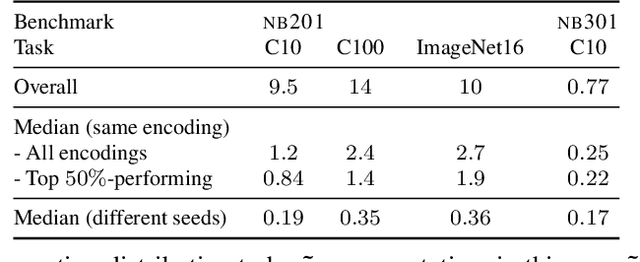
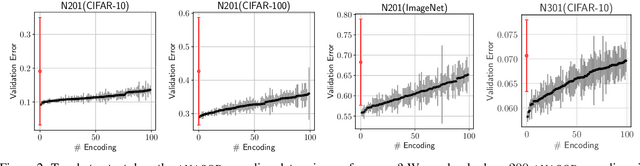
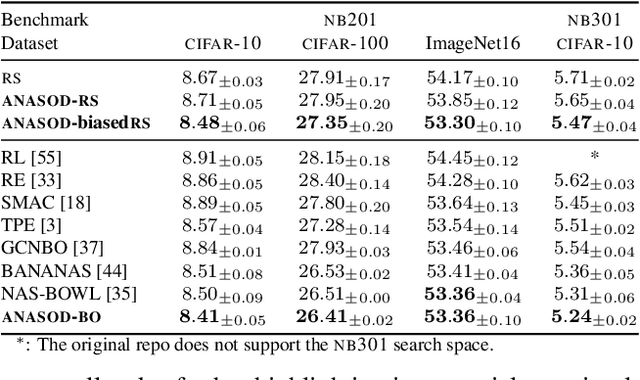
The standard paradigm in Neural Architecture Search (NAS) is to search for a fully deterministic architecture with specific operations and connections. In this work, we instead propose to search for the optimal operation distribution, thus providing a stochastic and approximate solution, which can be used to sample architectures of arbitrary length. We propose and show, that given an architectural cell, its performance largely depends on the ratio of used operations, rather than any specific connection pattern in typical search spaces; that is, small changes in the ordering of the operations are often irrelevant. This intuition is orthogonal to any specific search strategy and can be applied to a diverse set of NAS algorithms. Through extensive validation on 4 data-sets and 4 NAS techniques (Bayesian optimisation, differentiable search, local search and random search), we show that the operation distribution (1) holds enough discriminating power to reliably identify a solution and (2) is significantly easier to optimise than traditional encodings, leading to large speed-ups at little to no cost in performance. Indeed, this simple intuition significantly reduces the cost of current approaches and potentially enable NAS to be used in a broader range of applications.