 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDARTS without a Validation Set: Optimizing the Marginal Likelihood
Paper and Code
Dec 24, 2021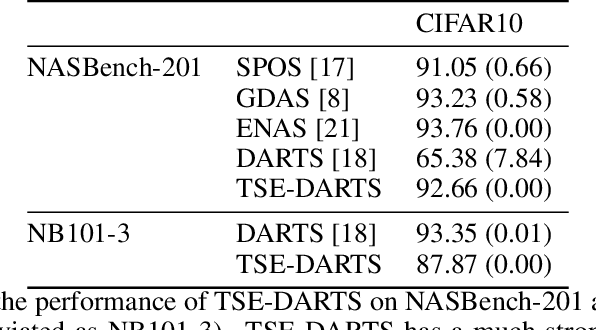
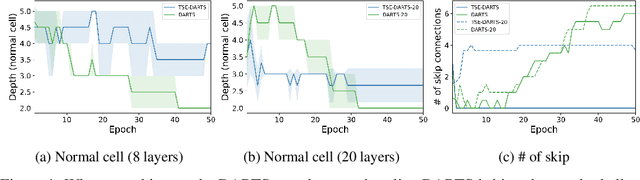
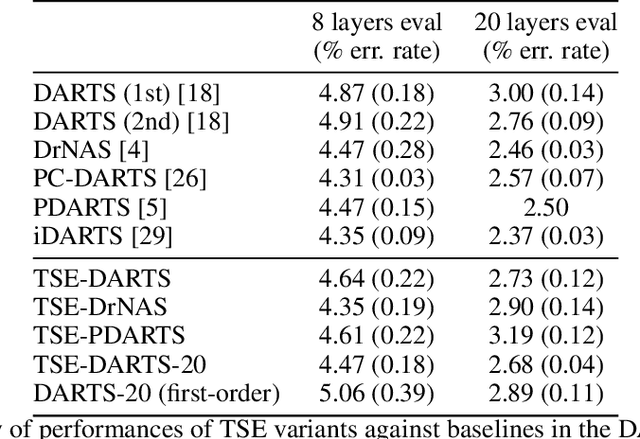
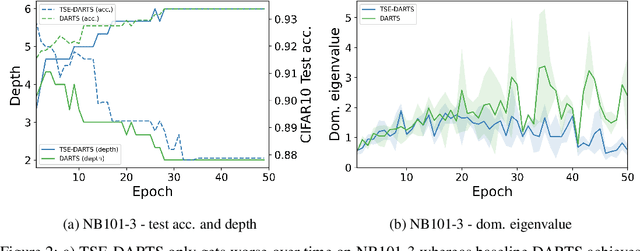
The success of neural architecture search (NAS) has historically been limited by excessive compute requirements. While modern weight-sharing NAS methods such as DARTS are able to finish the search in single-digit GPU days, extracting the final best architecture from the shared weights is notoriously unreliable. Training-Speed-Estimate (TSE), a recently developed generalization estimator with a Bayesian marginal likelihood interpretation, has previously been used in place of the validation loss for gradient-based optimization in DARTS. This prevents the DARTS skip connection collapse, which significantly improves performance on NASBench-201 and the original DARTS search space. We extend those results by applying various DARTS diagnostics and show several unusual behaviors arising from not using a validation set. Furthermore, our experiments yield concrete examples of the depth gap and topology selection in DARTS having a strongly negative impact on the search performance despite generally receiving limited attention in the literature compared to the operations selection.