 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuned In-Context Learners for Efficient Adaptation
Dec 22, 2025When adapting large language models (LLMs) to a specific downstream task, two primary approaches are commonly employed: (1) prompt engineering, often with in-context few-shot learning, leveraging the model's inherent generalization abilities, and (2) fine-tuning on task-specific data, directly optimizing the model's parameters. While prompt-based methods excel in few-shot scenarios, their effectiveness often plateaus as more data becomes available. Conversely, fine-tuning scales well with data but may underperform when training examples are scarce. We investigate a unified approach that bridges these two paradigms by incorporating in-context learning directly into the fine-tuning process. Specifically, we fine-tune the model on task-specific data augmented with in-context examples, mimicking the structure of k-shot prompts. This approach, while requiring per-task fine-tuning, combines the sample efficiency of in-context learning with the performance gains of fine-tuning, leading to a method that consistently matches and often significantly exceeds both these baselines. To perform hyperparameter selection in the low-data regime, we propose to use prequential evaluation, which eliminates the need for expensive cross-validation and leverages all available data for training while simultaneously providing a robust validation signal. We conduct an extensive empirical study to determine which adaptation paradigm - fine-tuning, in-context learning, or our proposed unified approach offers the best predictive performance on a concrete data downstream-tasks.
What Can Grokking Teach Us About Learning Under Nonstationarity?
Jul 26, 2025In continual learning problems, it is often necessary to overwrite components of a neural network's learned representation in response to changes in the data stream; however, neural networks often exhibit \primacy bias, whereby early training data hinders the network's ability to generalize on later tasks. While feature-learning dynamics of nonstationary learning problems are not well studied, the emergence of feature-learning dynamics is known to drive the phenomenon of grokking, wherein neural networks initially memorize their training data and only later exhibit perfect generalization. This work conjectures that the same feature-learning dynamics which facilitate generalization in grokking also underlie the ability to overwrite previous learned features as well, and methods which accelerate grokking by facilitating feature-learning dynamics are promising candidates for addressing primacy bias in non-stationary learning problems. We then propose a straightforward method to induce feature-learning dynamics as needed throughout training by increasing the effective learning rate, i.e. the ratio between parameter and update norms. We show that this approach both facilitates feature-learning and improves generalization in a variety of settings, including grokking, warm-starting neural network training, and reinforcement learning tasks.
Optimizers Qualitatively Alter Solutions And We Should Leverage This
Jul 16, 2025Due to the nonlinear nature of Deep Neural Networks (DNNs), one can not guarantee convergence to a unique global minimum of the loss when using optimizers relying only on local information, such as SGD. Indeed, this was a primary source of skepticism regarding the feasibility of DNNs in the early days of the field. The past decades of progress in deep learning have revealed this skepticism to be misplaced, and a large body of empirical evidence shows that sufficiently large DNNs following standard training protocols exhibit well-behaved optimization dynamics that converge to performant solutions. This success has biased the community to use convex optimization as a mental model for learning, leading to a focus on training efficiency, either in terms of required iteration, FLOPs or wall-clock time, when improving optimizers. We argue that, while this perspective has proven extremely fruitful, another perspective specific to DNNs has received considerably less attention: the optimizer not only influences the rate of convergence, but also the qualitative properties of the learned solutions. Restated, the optimizer can and will encode inductive biases and change the effective expressivity of a given class of models. Furthermore, we believe the optimizer can be an effective way of encoding desiderata in the learning process. We contend that the community should aim at understanding the biases of already existing methods, as well as aim to build new optimizers with the explicit intent of inducing certain properties of the solution, rather than solely judging them based on their convergence rates. We hope our arguments will inspire research to improve our understanding of how the learning process can impact the type of solution we converge to, and lead to a greater recognition of optimizers design as a critical lever that complements the roles of architecture and data in shaping model outcomes.
Plasticity as the Mirror of Empowerment
May 15, 2025Agents are minimally entities that are influenced by their past observations and act to influence future observations. This latter capacity is captured by empowerment, which has served as a vital framing concept across artificial intelligence and cognitive science. This former capacity, however, is equally foundational: In what ways, and to what extent, can an agent be influenced by what it observes? In this paper, we ground this concept in a universal agent-centric measure that we refer to as plasticity, and reveal a fundamental connection to empowerment. Following a set of desiderata on a suitable definition, we define plasticity using a new information-theoretic quantity we call the generalized directed information. We show that this new quantity strictly generalizes the directed information introduced by Massey (1990) while preserving all of its desirable properties. Our first finding is that plasticity is the mirror of empowerment: The agent's plasticity is identical to the empowerment of the environment, and vice versa. Our second finding establishes a tension between the plasticity and empowerment of an agent, suggesting that agent design needs to be mindful of both characteristics. We explore the implications of these findings, and suggest that plasticity, empowerment, and their relationship are essential to understanding agency.
Agency Is Frame-Dependent
Feb 06, 2025
Agency is a system's capacity to steer outcomes toward a goal, and is a central topic of study across biology, philosophy, cognitive science, and artificial intelligence. Determining if a system exhibits agency is a notoriously difficult question: Dennett (1989), for instance, highlights the puzzle of determining which principles can decide whether a rock, a thermostat, or a robot each possess agency. We here address this puzzle from the viewpoint of reinforcement learning by arguing that agency is fundamentally frame-dependent: Any measurement of a system's agency must be made relative to a reference frame. We support this claim by presenting a philosophical argument that each of the essential properties of agency proposed by Barandiaran et al. (2009) and Moreno (2018) are themselves frame-dependent. We conclude that any basic science of agency requires frame-dependence, and discuss the implications of this claim for reinforcement learning.
Non-Stationary Learning of Neural Networks with Automatic Soft Parameter Reset
Nov 06, 2024



Neural networks are traditionally trained under the assumption that data come from a stationary distribution. However, settings which violate this assumption are becoming more popular; examples include supervised learning under distributional shifts, reinforcement learning, continual learning and non-stationary contextual bandits. In this work we introduce a novel learning approach that automatically models and adapts to non-stationarity, via an Ornstein-Uhlenbeck process with an adaptive drift parameter. The adaptive drift tends to draw the parameters towards the initialisation distribution, so the approach can be understood as a form of soft parameter reset. We show empirically that our approach performs well in non-stationary supervised and off-policy reinforcement learning settings.
Frequency and Generalisation of Periodic Activation Functions in Reinforcement Learning
Jul 09, 2024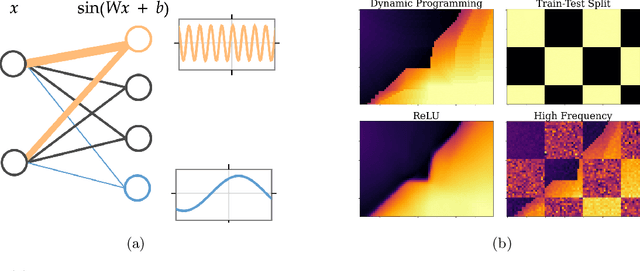


Periodic activation functions, often referred to as learned Fourier features have been widely demonstrated to improve sample efficiency and stability in a variety of deep RL algorithms. Potentially incompatible hypotheses have been made about the source of these improvements. One is that periodic activations learn low frequency representations and as a result avoid overfitting to bootstrapped targets. Another is that periodic activations learn high frequency representations that are more expressive, allowing networks to quickly fit complex value functions. We analyse these claims empirically, finding that periodic representations consistently converge to high frequencies regardless of their initialisation frequency. We also find that while periodic activation functions improve sample efficiency, they exhibit worse generalization on states with added observation noise -- especially when compared to otherwise equivalent networks with ReLU activation functions. Finally, we show that weight decay regularization is able to partially offset the overfitting of periodic activation functions, delivering value functions that learn quickly while also generalizing.
Normalization and effective learning rates in reinforcement learning
Jul 01, 2024



Normalization layers have recently experienced a renaissance in the deep reinforcement learning and continual learning literature, with several works highlighting diverse benefits such as improving loss landscape conditioning and combatting overestimation bias. However, normalization brings with it a subtle but important side effect: an equivalence between growth in the norm of the network parameters and decay in the effective learning rate. This becomes problematic in continual learning settings, where the resulting effective learning rate schedule may decay to near zero too quickly relative to the timescale of the learning problem. We propose to make the learning rate schedule explicit with a simple re-parameterization which we call Normalize-and-Project (NaP), which couples the insertion of normalization layers with weight projection, ensuring that the effective learning rate remains constant throughout training. This technique reveals itself as a powerful analytical tool to better understand learning rate schedules in deep reinforcement learning, and as a means of improving robustness to nonstationarity in synthetic plasticity loss benchmarks along with both the single-task and sequential variants of the Arcade Learning Environment. We also show that our approach can be easily applied to popular architectures such as ResNets and transformers while recovering and in some cases even slightly improving the performance of the base model in common stationary benchmarks.
Weight Clipping for Deep Continual and Reinforcement Learning
Jul 01, 2024



Many failures in deep continual and reinforcement learning are associated with increasing magnitudes of the weights, making them hard to change and potentially causing overfitting. While many methods address these learning failures, they often change the optimizer or the architecture, a complexity that hinders widespread adoption in various systems. In this paper, we focus on learning failures that are associated with increasing weight norm and we propose a simple technique that can be easily added on top of existing learning systems: clipping neural network weights to limit them to a specific range. We study the effectiveness of weight clipping in a series of supervised and reinforcement learning experiments. Our empirical results highlight the benefits of weight clipping for generalization, addressing loss of plasticity and policy collapse, and facilitating learning with a large replay ratio.
A Unifying Framework for Action-Conditional Self-Predictive Reinforcement Learning
Jun 04, 2024



Learning a good representation is a crucial challenge for Reinforcement Learning (RL) agents. Self-predictive learning provides means to jointly learn a latent representation and dynamics model by bootstrapping from future latent representations (BYOL). Recent work has developed theoretical insights into these algorithms by studying a continuous-time ODE model for self-predictive representation learning under the simplifying assumption that the algorithm depends on a fixed policy (BYOL-$\Pi$); this assumption is at odds with practical instantiations of such algorithms, which explicitly condition their predictions on future actions. In this work, we take a step towards bridging the gap between theory and practice by analyzing an action-conditional self-predictive objective (BYOL-AC) using the ODE framework, characterizing its convergence properties and highlighting important distinctions between the limiting solutions of the BYOL-$\Pi$ and BYOL-AC dynamics. We show how the two representations are related by a variance equation. This connection leads to a novel variance-like action-conditional objective (BYOL-VAR) and its corresponding ODE. We unify the study of all three objectives through two complementary lenses; a model-based perspective, where each objective is shown to be equivalent to a low-rank approximation of certain dynamics, and a model-free perspective, which establishes relationships between the objectives and their respective value, Q-value, and advantage function. Our empirical investigations, encompassing both linear function approximation and Deep RL environments, demonstrates that BYOL-AC is better overall in a variety of different settings.