 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHANGUS: Deep Reinforcement Learning Meets Heuristic Optimization for Speedy Frontier-Based Exploration of Autonomous Vehicles in Unknown Spaces
Jul 26, 2024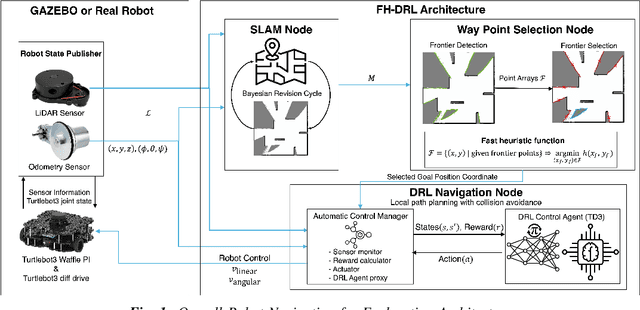
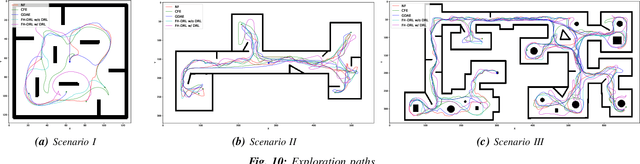
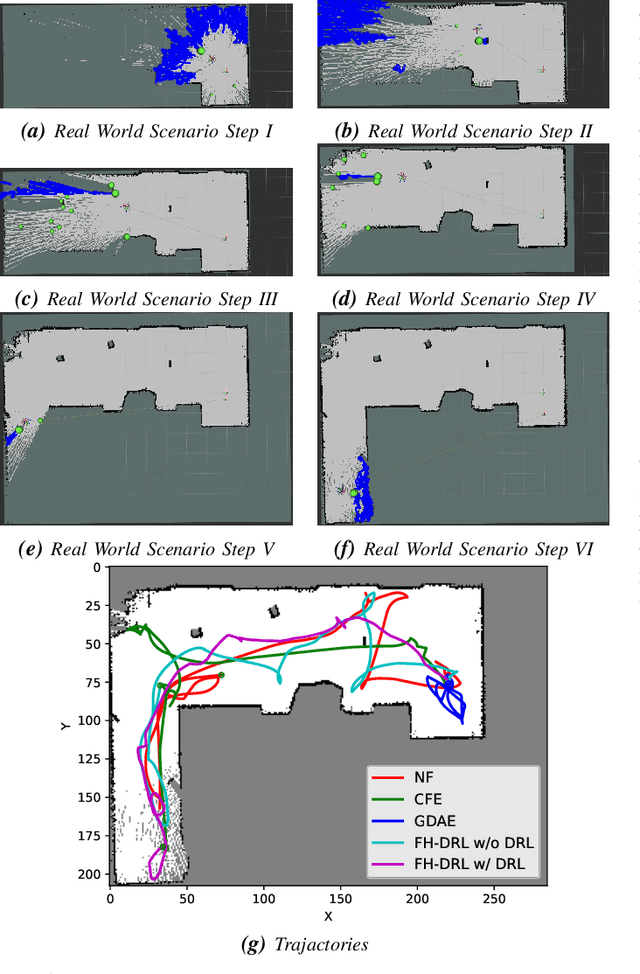
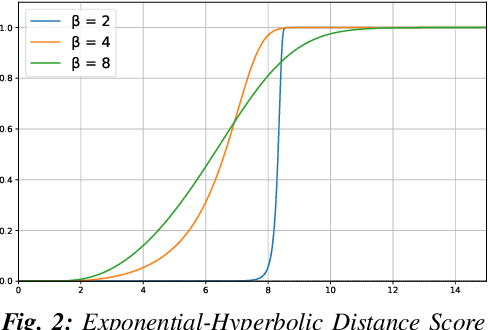
This paper introduces SHANGUS, an advanced framework combining Deep Reinforcement Learning (DRL) with heuristic optimization to improve frontier-based exploration efficiency in unknown environments, particularly for intelligent vehicles in autonomous air services, search and rescue operations, and space exploration robotics. SHANGUS harnesses DRL's adaptability and heuristic prioritization, markedly enhancing exploration efficiency, reducing completion time, and minimizing travel distance. The strategy involves a frontier selection node to identify unexplored areas and a DRL navigation node using the Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm for robust path planning and dynamic obstacle avoidance. Extensive experiments in ROS2 and Gazebo simulation environments show SHANGUS surpasses representative traditional methods like the Nearest Frontier (NF), Novel Frontier-Based Exploration Algorithm (CFE), and Goal-Driven Autonomous Exploration (GDAE) algorithms, especially in complex scenarios, excelling in completion time, travel distance, and exploration rate. This scalable solution is suitable for real-time autonomous navigation in fields such as industrial automation, autonomous driving, household robotics, and space exploration. Future research will integrate additional sensory inputs and refine heuristic functions to further boost SHANGUS's efficiency and robustness.
Slow and Steady Wins the Race: Maintaining Plasticity with Hare and Tortoise Networks
Jun 01, 2024This study investigates the loss of generalization ability in neural networks, revisiting warm-starting experiments from Ash & Adams. Our empirical analysis reveals that common methods designed to enhance plasticity by maintaining trainability provide limited benefits to generalization. While reinitializing the network can be effective, it also risks losing valuable prior knowledge. To this end, we introduce the Hare & Tortoise, inspired by the brain's complementary learning system. Hare & Tortoise consists of two components: the Hare network, which rapidly adapts to new information analogously to the hippocampus, and the Tortoise network, which gradually integrates knowledge akin to the neocortex. By periodically reinitializing the Hare network to the Tortoise's weights, our method preserves plasticity while retaining general knowledge. Hare & Tortoise can effectively maintain the network's ability to generalize, which improves advanced reinforcement learning algorithms on the Atari-100k benchmark. The code is available at https://github.com/dojeon-ai/hare-tortoise.