 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWasserstein Policy Optimization
May 01, 2025



We introduce Wasserstein Policy Optimization (WPO), an actor-critic algorithm for reinforcement learning in continuous action spaces. WPO can be derived as an approximation to Wasserstein gradient flow over the space of all policies projected into a finite-dimensional parameter space (e.g., the weights of a neural network), leading to a simple and completely general closed-form update. The resulting algorithm combines many properties of deterministic and classic policy gradient methods. Like deterministic policy gradients, it exploits knowledge of the gradient of the action-value function with respect to the action. Like classic policy gradients, it can be applied to stochastic policies with arbitrary distributions over actions -- without using the reparameterization trick. We show results on the DeepMind Control Suite and a magnetic confinement fusion task which compare favorably with state-of-the-art continuous control methods.
A Unifying Framework for Action-Conditional Self-Predictive Reinforcement Learning
Jun 04, 2024



Learning a good representation is a crucial challenge for Reinforcement Learning (RL) agents. Self-predictive learning provides means to jointly learn a latent representation and dynamics model by bootstrapping from future latent representations (BYOL). Recent work has developed theoretical insights into these algorithms by studying a continuous-time ODE model for self-predictive representation learning under the simplifying assumption that the algorithm depends on a fixed policy (BYOL-$\Pi$); this assumption is at odds with practical instantiations of such algorithms, which explicitly condition their predictions on future actions. In this work, we take a step towards bridging the gap between theory and practice by analyzing an action-conditional self-predictive objective (BYOL-AC) using the ODE framework, characterizing its convergence properties and highlighting important distinctions between the limiting solutions of the BYOL-$\Pi$ and BYOL-AC dynamics. We show how the two representations are related by a variance equation. This connection leads to a novel variance-like action-conditional objective (BYOL-VAR) and its corresponding ODE. We unify the study of all three objectives through two complementary lenses; a model-based perspective, where each objective is shown to be equivalent to a low-rank approximation of certain dynamics, and a model-free perspective, which establishes relationships between the objectives and their respective value, Q-value, and advantage function. Our empirical investigations, encompassing both linear function approximation and Deep RL environments, demonstrates that BYOL-AC is better overall in a variety of different settings.
A State Representation for Diminishing Rewards
Sep 07, 2023A common setting in multitask reinforcement learning (RL) demands that an agent rapidly adapt to various stationary reward functions randomly sampled from a fixed distribution. In such situations, the successor representation (SR) is a popular framework which supports rapid policy evaluation by decoupling a policy's expected discounted, cumulative state occupancies from a specific reward function. However, in the natural world, sequential tasks are rarely independent, and instead reflect shifting priorities based on the availability and subjective perception of rewarding stimuli. Reflecting this disjunction, in this paper we study the phenomenon of diminishing marginal utility and introduce a novel state representation, the $\lambda$ representation ($\lambda$R) which, surprisingly, is required for policy evaluation in this setting and which generalizes the SR as well as several other state representations from the literature. We establish the $\lambda$R's formal properties and examine its normative advantages in the context of machine learning, as well as its usefulness for studying natural behaviors, particularly foraging.
Generalised Policy Improvement with Geometric Policy Composition
Jun 17, 2022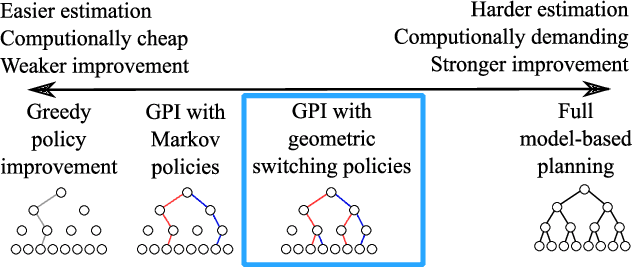

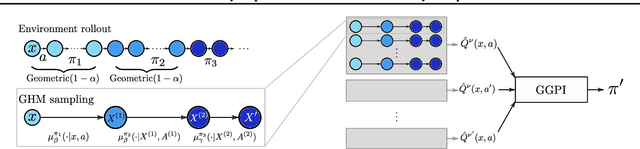
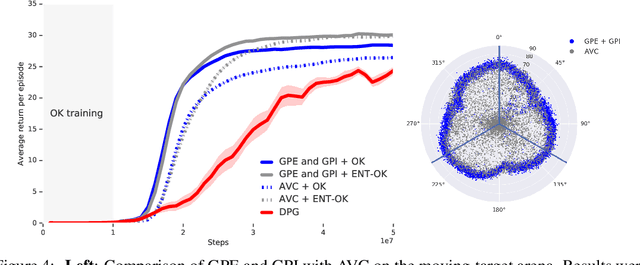
We introduce a method for policy improvement that interpolates between the greedy approach of value-based reinforcement learning (RL) and the full planning approach typical of model-based RL. The new method builds on the concept of a geometric horizon model (GHM, also known as a gamma-model), which models the discounted state-visitation distribution of a given policy. We show that we can evaluate any non-Markov policy that switches between a set of base Markov policies with fixed probability by a careful composition of the base policy GHMs, without any additional learning. We can then apply generalised policy improvement (GPI) to collections of such non-Markov policies to obtain a new Markov policy that will in general outperform its precursors. We provide a thorough theoretical analysis of this approach, develop applications to transfer and standard RL, and empirically demonstrate its effectiveness over standard GPI on a challenging deep RL continuous control task. We also provide an analysis of GHM training methods, proving a novel convergence result regarding previously proposed methods and showing how to train these models stably in deep RL settings.
Selective Credit Assignment
Feb 20, 2022
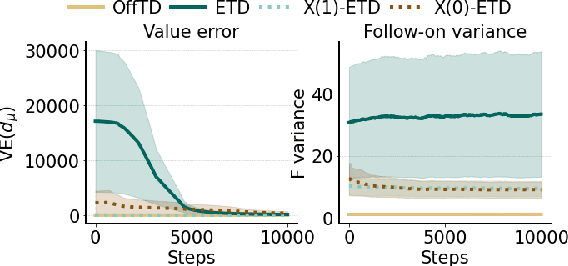
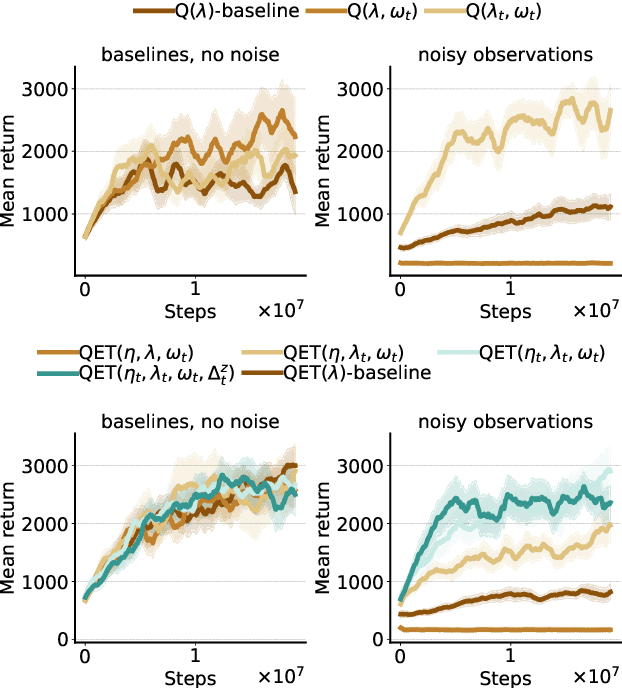
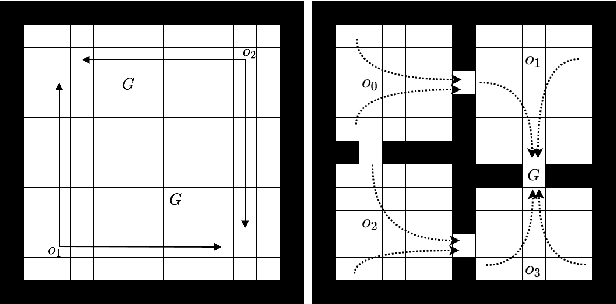
Efficient credit assignment is essential for reinforcement learning algorithms in both prediction and control settings. We describe a unified view on temporal-difference algorithms for selective credit assignment. These selective algorithms apply weightings to quantify the contribution of learning updates. We present insights into applying weightings to value-based learning and planning algorithms, and describe their role in mediating the backward credit distribution in prediction and control. Within this space, we identify some existing online learning algorithms that can assign credit selectively as special cases, as well as add new algorithms that assign credit backward in time counterfactually, allowing credit to be assigned off-trajectory and off-policy.
Model-Value Inconsistency as a Signal for Epistemic Uncertainty
Dec 08, 2021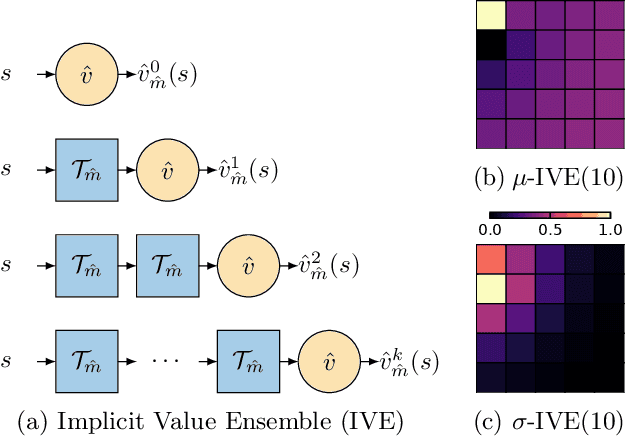

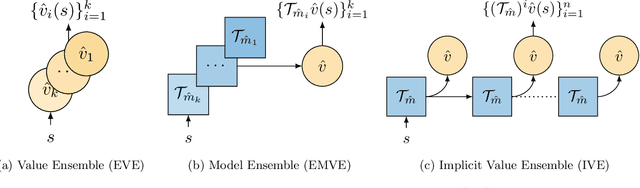
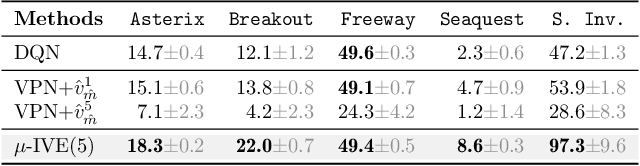
Using a model of the environment and a value function, an agent can construct many estimates of a state's value, by unrolling the model for different lengths and bootstrapping with its value function. Our key insight is that one can treat this set of value estimates as a type of ensemble, which we call an \emph{implicit value ensemble} (IVE). Consequently, the discrepancy between these estimates can be used as a proxy for the agent's epistemic uncertainty; we term this signal \emph{model-value inconsistency} or \emph{self-inconsistency} for short. Unlike prior work which estimates uncertainty by training an ensemble of many models and/or value functions, this approach requires only the single model and value function which are already being learned in most model-based reinforcement learning algorithms. We provide empirical evidence in both tabular and function approximation settings from pixels that self-inconsistency is useful (i) as a signal for exploration, (ii) for acting safely under distribution shifts, and (iii) for robustifying value-based planning with a model.
When should agents explore?
Aug 26, 2021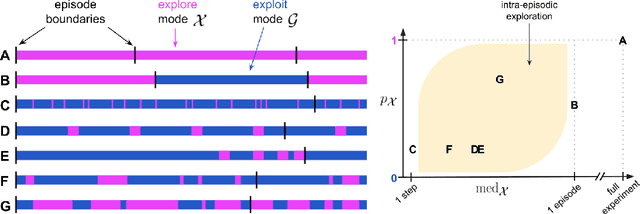
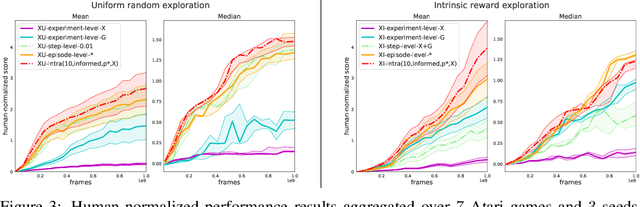
Exploration remains a central challenge for reinforcement learning (RL). Virtually all existing methods share the feature of a monolithic behaviour policy that changes only gradually (at best). In contrast, the exploratory behaviours of animals and humans exhibit a rich diversity, namely including forms of switching between modes. This paper presents an initial study of mode-switching, non-monolithic exploration for RL. We investigate different modes to switch between, at what timescales it makes sense to switch, and what signals make for good switching triggers. We also propose practical algorithmic components that make the switching mechanism adaptive and robust, which enables flexibility without an accompanying hyper-parameter-tuning burden. Finally, we report a promising and detailed analysis on Atari, using two-mode exploration and switching at sub-episodic time-scales.
The Option Keyboard: Combining Skills in Reinforcement Learning
Jun 24, 2021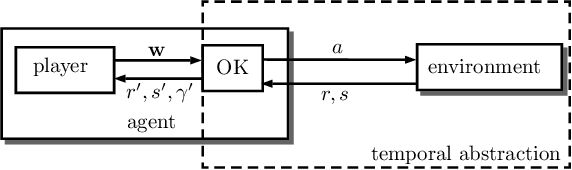
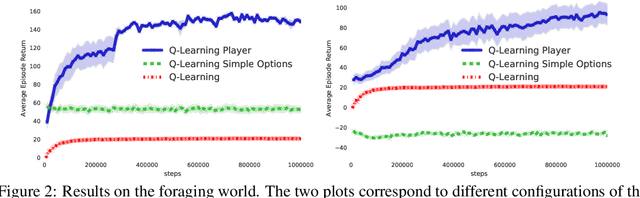
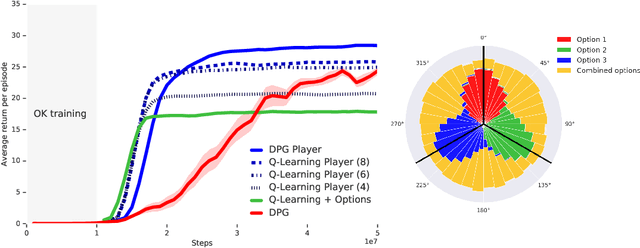
The ability to combine known skills to create new ones may be crucial in the solution of complex reinforcement learning problems that unfold over extended periods. We argue that a robust way of combining skills is to define and manipulate them in the space of pseudo-rewards (or "cumulants"). Based on this premise, we propose a framework for combining skills using the formalism of options. We show that every deterministic option can be unambiguously represented as a cumulant defined in an extended domain. Building on this insight and on previous results on transfer learning, we show how to approximate options whose cumulants are linear combinations of the cumulants of known options. This means that, once we have learned options associated with a set of cumulants, we can instantaneously synthesise options induced by any linear combination of them, without any learning involved. We describe how this framework provides a hierarchical interface to the environment whose abstract actions correspond to combinations of basic skills. We demonstrate the practical benefits of our approach in a resource management problem and a navigation task involving a quadrupedal simulated robot.
Return-based Scaling: Yet Another Normalisation Trick for Deep RL
May 11, 2021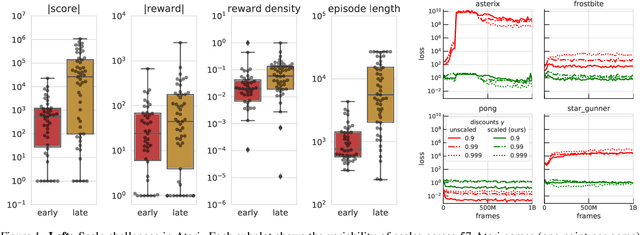
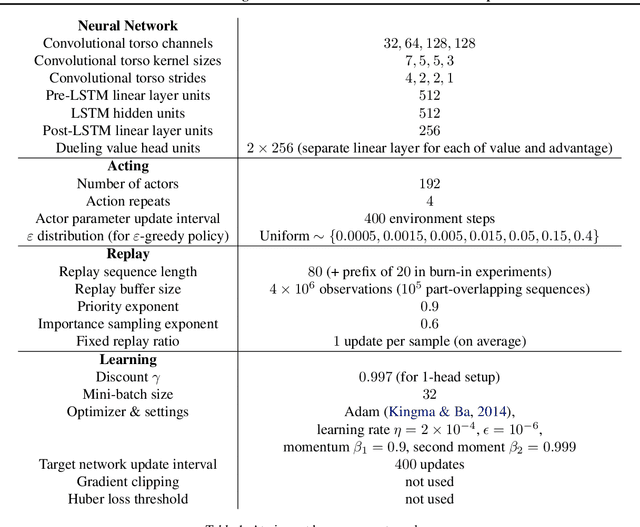
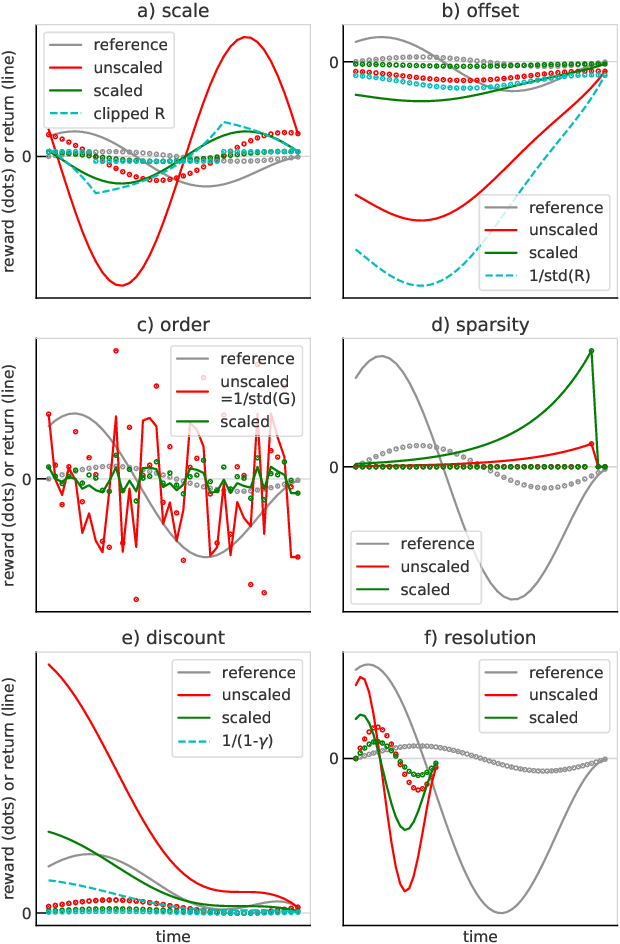
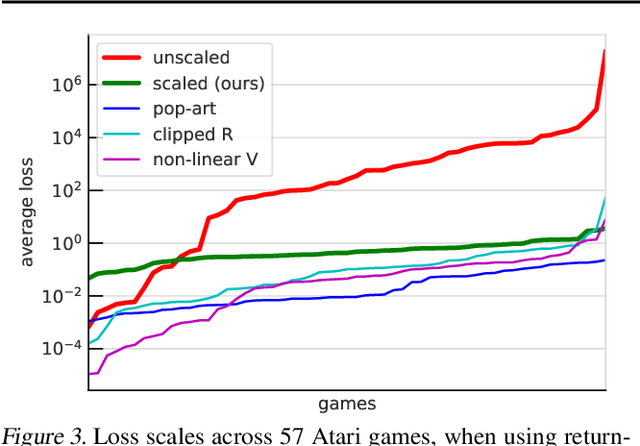
Scaling issues are mundane yet irritating for practitioners of reinforcement learning. Error scales vary across domains, tasks, and stages of learning; sometimes by many orders of magnitude. This can be detrimental to learning speed and stability, create interference between learning tasks, and necessitate substantial tuning. We revisit this topic for agents based on temporal-difference learning, sketch out some desiderata and investigate scenarios where simple fixes fall short. The mechanism we propose requires neither tuning, clipping, nor adaptation. We validate its effectiveness and robustness on the suite of Atari games. Our scaling method turns out to be particularly helpful at mitigating interference, when training a shared neural network on multiple targets that differ in reward scale or discounting.
Expected Eligibility Traces
Jul 03, 2020
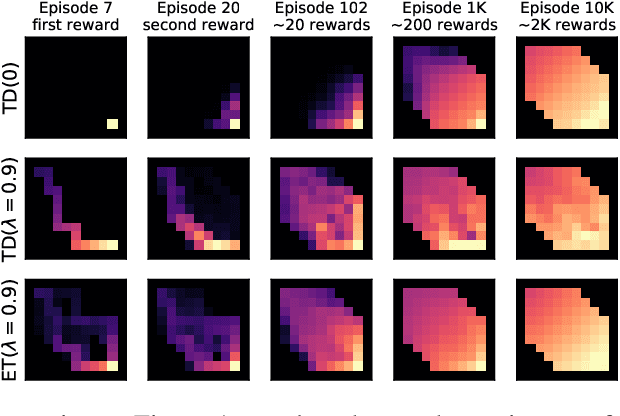
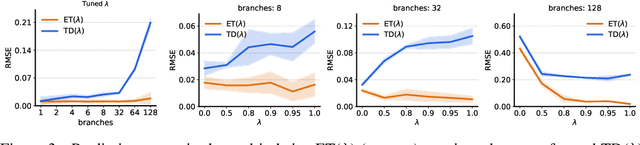
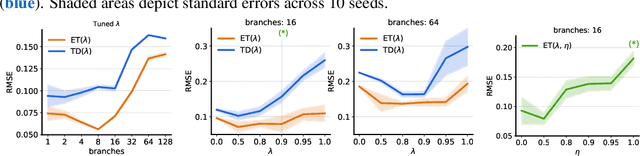
The question of how to determine which states and actions are responsible for a certain outcome is known as the credit assignment problem and remains a central research question in reinforcement learning and artificial intelligence. Eligibility traces enable efficient credit assignment to the recent sequence of states and actions experienced by the agent, but not to counterfactual sequences that could also have led to the current state. In this work, we introduce expected eligibility traces. Expected traces allow, with a single update, to update states and actions that could have preceded the current state, even if they did not do so on this occasion. We discuss when expected traces provide benefits over classic (instantaneous) traces in temporal-difference learning, and show that sometimes substantial improvements can be attained. We provide a way to smoothly interpolate between instantaneous and expected traces by a mechanism similar to bootstrapping, which ensures that the resulting algorithm is a strict generalisation of TD($\lambda$). Finally, we discuss possible extensions and connections to related ideas, such as successor features.