 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning how to Interact with a Complex Interface using Hierarchical Reinforcement Learning
Apr 21, 2022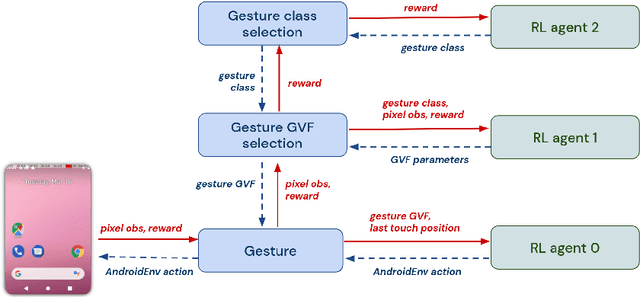
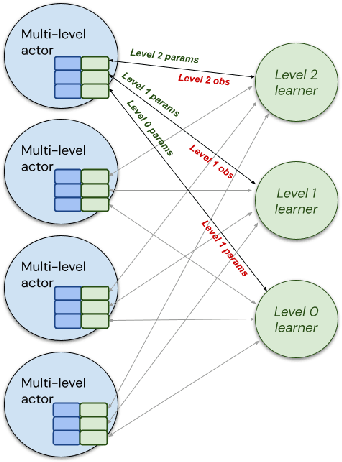
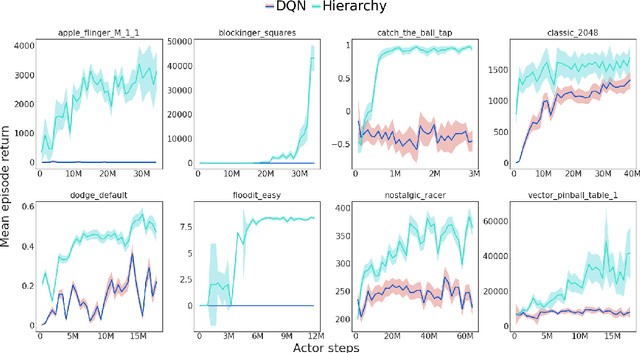
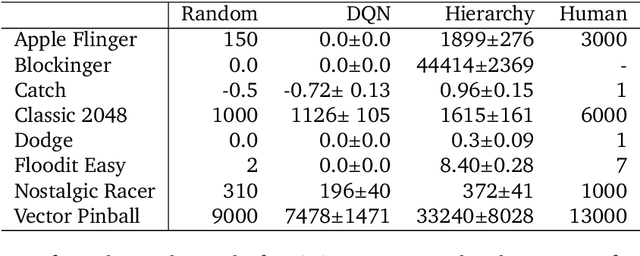
Hierarchical Reinforcement Learning (HRL) allows interactive agents to decompose complex problems into a hierarchy of sub-tasks. Higher-level tasks can invoke the solutions of lower-level tasks as if they were primitive actions. In this work, we study the utility of hierarchical decompositions for learning an appropriate way to interact with a complex interface. Specifically, we train HRL agents that can interface with applications in a simulated Android device. We introduce a Hierarchical Distributed Deep Reinforcement Learning architecture that learns (1) subtasks corresponding to simple finger gestures, and (2) how to combine these gestures to solve several Android tasks. Our approach relies on goal conditioning and can be used more generally to convert any base RL agent into an HRL agent. We use the AndroidEnv environment to evaluate our approach. For the experiments, the HRL agent uses a distributed version of the popular DQN algorithm to train different components of the hierarchy. While the native action space is completely intractable for simple DQN agents, our architecture can be used to establish an effective way to interact with different tasks, significantly improving the performance of the same DQN agent over different levels of abstraction.
The Option Keyboard: Combining Skills in Reinforcement Learning
Jun 24, 2021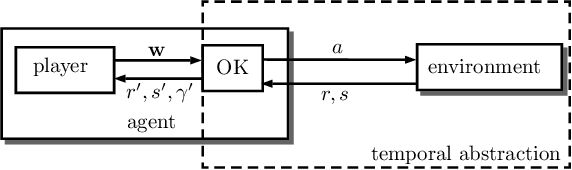
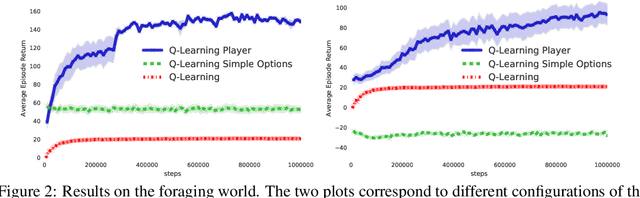
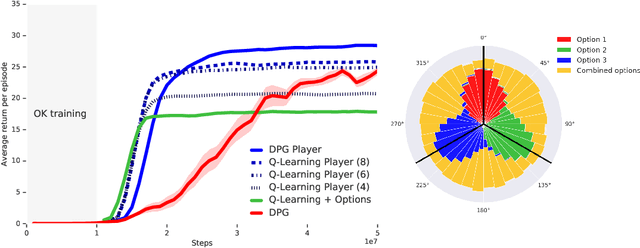
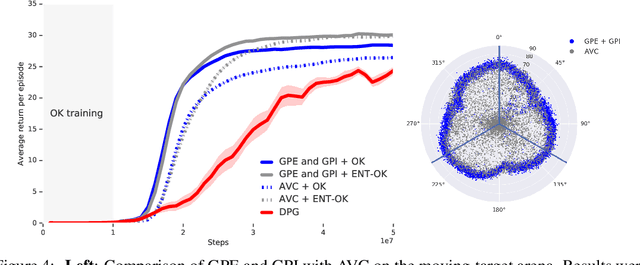
The ability to combine known skills to create new ones may be crucial in the solution of complex reinforcement learning problems that unfold over extended periods. We argue that a robust way of combining skills is to define and manipulate them in the space of pseudo-rewards (or "cumulants"). Based on this premise, we propose a framework for combining skills using the formalism of options. We show that every deterministic option can be unambiguously represented as a cumulant defined in an extended domain. Building on this insight and on previous results on transfer learning, we show how to approximate options whose cumulants are linear combinations of the cumulants of known options. This means that, once we have learned options associated with a set of cumulants, we can instantaneously synthesise options induced by any linear combination of them, without any learning involved. We describe how this framework provides a hierarchical interface to the environment whose abstract actions correspond to combinations of basic skills. We demonstrate the practical benefits of our approach in a resource management problem and a navigation task involving a quadrupedal simulated robot.
AndroidEnv: A Reinforcement Learning Platform for Android
May 27, 2021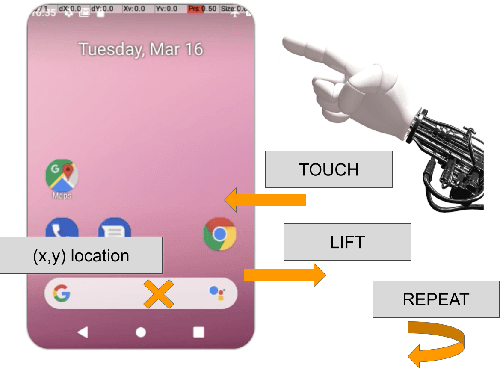
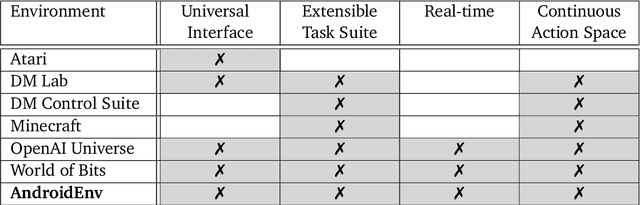
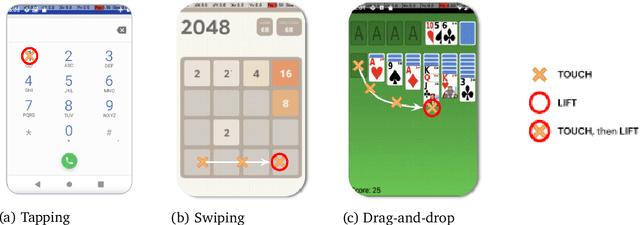
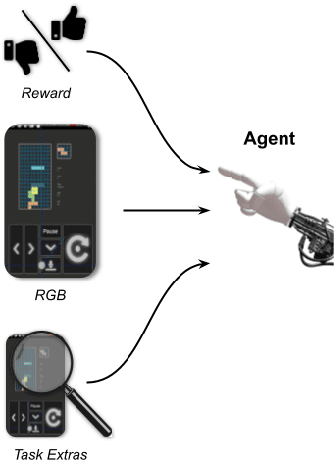
We introduce AndroidEnv, an open-source platform for Reinforcement Learning (RL) research built on top of the Android ecosystem. AndroidEnv allows RL agents to interact with a wide variety of apps and services commonly used by humans through a universal touchscreen interface. Since agents train on a realistic simulation of an Android device, they have the potential to be deployed on real devices. In this report, we give an overview of the environment, highlighting the significant features it provides for research, and we present an empirical evaluation of some popular reinforcement learning agents on a set of tasks built on this platform.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016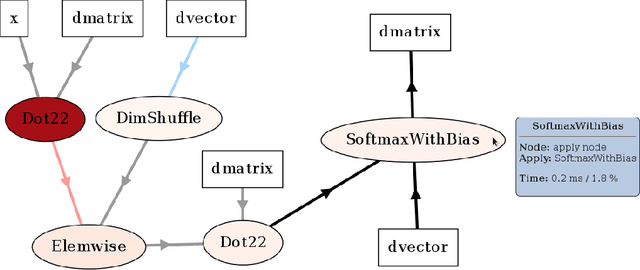
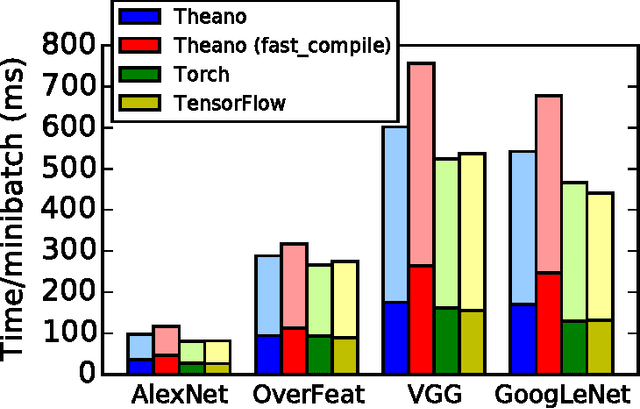
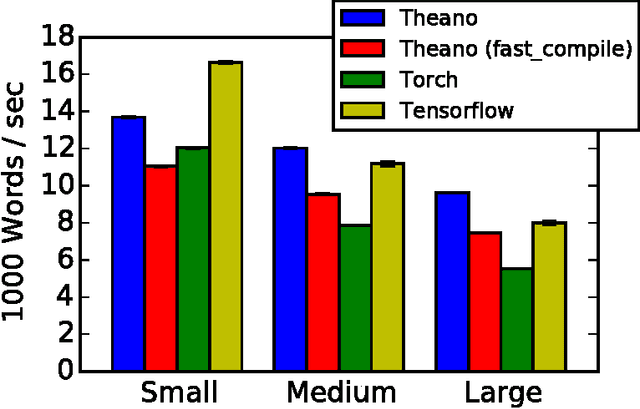
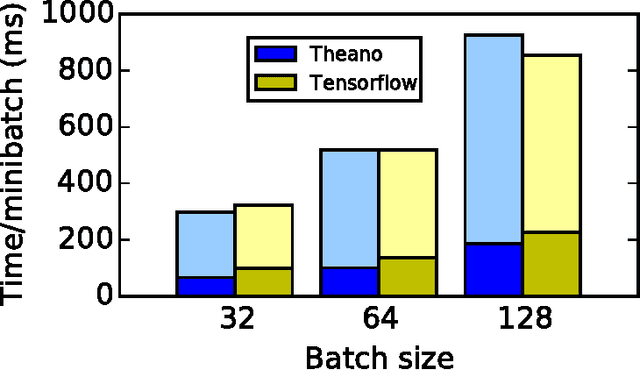
Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.
Large-Scale Music Annotation and Retrieval: Learning to Rank in Joint Semantic Spaces
May 26, 2011
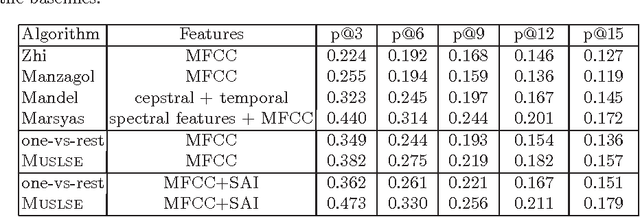
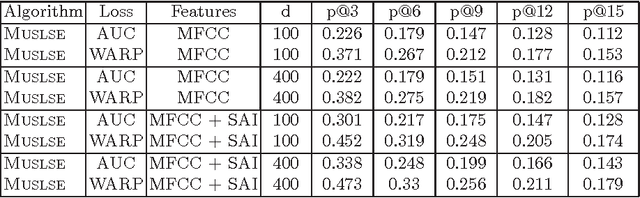

Music prediction tasks range from predicting tags given a song or clip of audio, predicting the name of the artist, or predicting related songs given a song, clip, artist name or tag. That is, we are interested in every semantic relationship between the different musical concepts in our database. In realistically sized databases, the number of songs is measured in the hundreds of thousands or more, and the number of artists in the tens of thousands or more, providing a considerable challenge to standard machine learning techniques. In this work, we propose a method that scales to such datasets which attempts to capture the semantic similarities between the database items by modeling audio, artist names, and tags in a single low-dimensional semantic space. This choice of space is learnt by optimizing the set of prediction tasks of interest jointly using multi-task learning. Our method both outperforms baseline methods and, in comparison to them, is faster and consumes less memory. We then demonstrate how our method learns an interpretable model, where the semantic space captures well the similarities of interest.