 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Diversifying AI: Towards Creative Chess with AlphaZero
Aug 29, 2023



In recent years, Artificial Intelligence (AI) systems have surpassed human intelligence in a variety of computational tasks. However, AI systems, like humans, make mistakes, have blind spots, hallucinate, and struggle to generalize to new situations. This work explores whether AI can benefit from creative decision-making mechanisms when pushed to the limits of its computational rationality. In particular, we investigate whether a team of diverse AI systems can outperform a single AI in challenging tasks by generating more ideas as a group and then selecting the best ones. We study this question in the game of chess, the so-called drosophila of AI. We build on AlphaZero (AZ) and extend it to represent a league of agents via a latent-conditioned architecture, which we call AZ_db. We train AZ_db to generate a wider range of ideas using behavioral diversity techniques and select the most promising ones with sub-additive planning. Our experiments suggest that AZ_db plays chess in diverse ways, solves more puzzles as a group and outperforms a more homogeneous team. Notably, AZ_db solves twice as many challenging puzzles as AZ, including the challenging Penrose positions. When playing chess from different openings, we notice that players in AZ_db specialize in different openings, and that selecting a player for each opening using sub-additive planning results in a 50 Elo improvement over AZ. Our findings suggest that diversity bonuses emerge in teams of AI agents, just as they do in teams of humans and that diversity is a valuable asset in solving computationally hard problems.
Discovering Policies with DOMiNO: Diversity Optimization Maintaining Near Optimality
May 26, 2022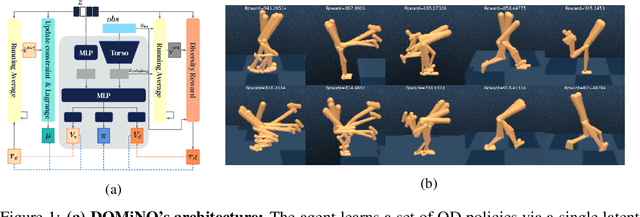
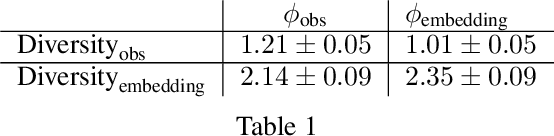
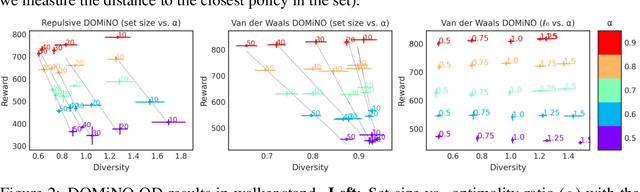
Finding different solutions to the same problem is a key aspect of intelligence associated with creativity and adaptation to novel situations. In reinforcement learning, a set of diverse policies can be useful for exploration, transfer, hierarchy, and robustness. We propose DOMiNO, a method for Diversity Optimization Maintaining Near Optimality. We formalize the problem as a Constrained Markov Decision Process where the objective is to find diverse policies, measured by the distance between the state occupancies of the policies in the set, while remaining near-optimal with respect to the extrinsic reward. We demonstrate that the method can discover diverse and meaningful behaviors in various domains, such as different locomotion patterns in the DeepMind Control Suite. We perform extensive analysis of our approach, compare it with other multi-objective baselines, demonstrate that we can control both the quality and the diversity of the set via interpretable hyperparameters, and show that the discovered set is robust to perturbations.
The Option Keyboard: Combining Skills in Reinforcement Learning
Jun 24, 2021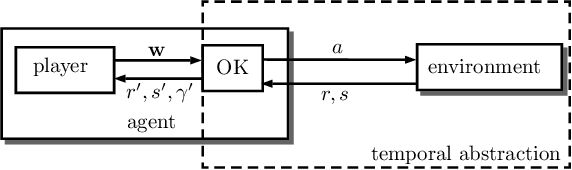
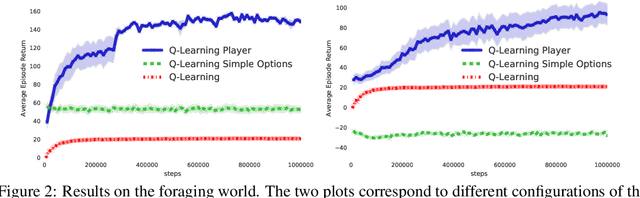
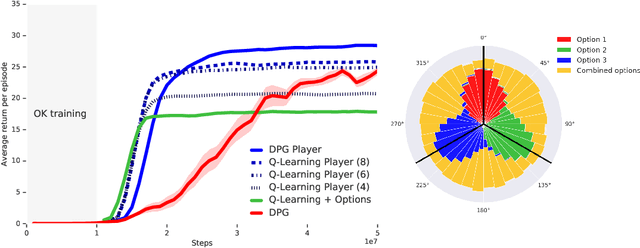
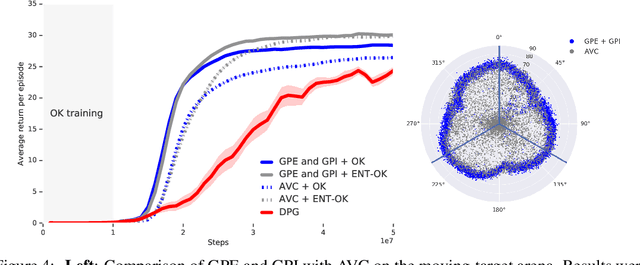
The ability to combine known skills to create new ones may be crucial in the solution of complex reinforcement learning problems that unfold over extended periods. We argue that a robust way of combining skills is to define and manipulate them in the space of pseudo-rewards (or "cumulants"). Based on this premise, we propose a framework for combining skills using the formalism of options. We show that every deterministic option can be unambiguously represented as a cumulant defined in an extended domain. Building on this insight and on previous results on transfer learning, we show how to approximate options whose cumulants are linear combinations of the cumulants of known options. This means that, once we have learned options associated with a set of cumulants, we can instantaneously synthesise options induced by any linear combination of them, without any learning involved. We describe how this framework provides a hierarchical interface to the environment whose abstract actions correspond to combinations of basic skills. We demonstrate the practical benefits of our approach in a resource management problem and a navigation task involving a quadrupedal simulated robot.
Best of both worlds: local and global explanations with human-understandable concepts
Jun 16, 2021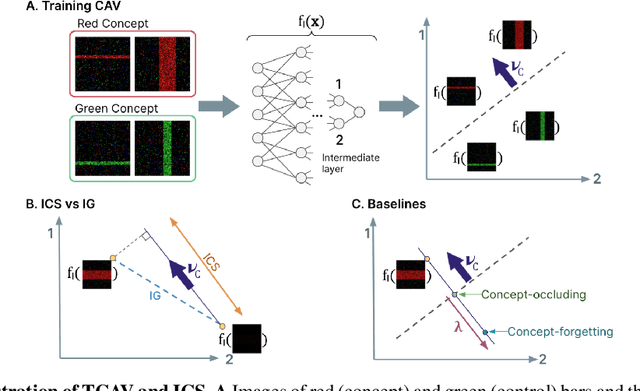
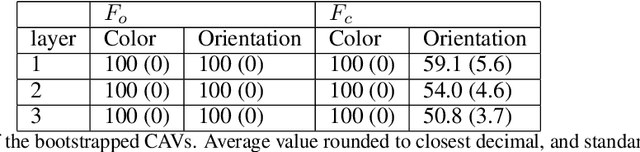
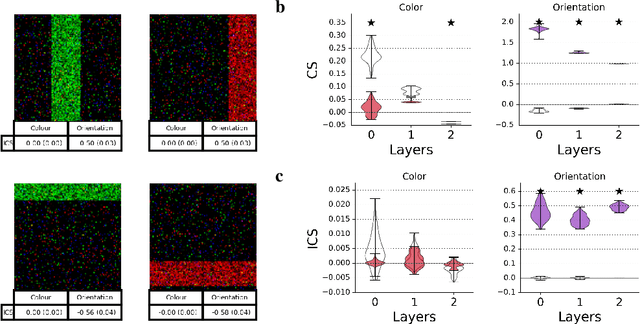
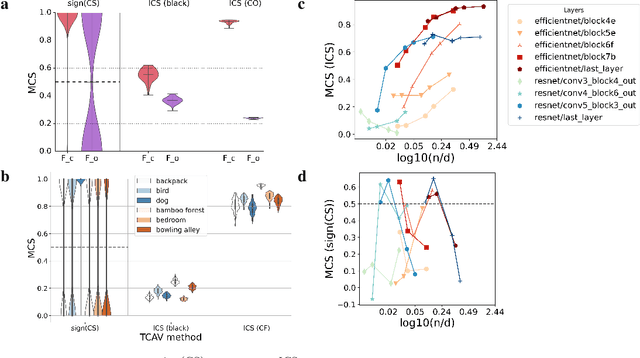
Interpretability techniques aim to provide the rationale behind a model's decision, typically by explaining either an individual prediction (local explanation, e.g. `why is this patient diagnosed with this condition') or a class of predictions (global explanation, e.g. `why are patients diagnosed with this condition in general'). While there are many methods focused on either one, few frameworks can provide both local and global explanations in a consistent manner. In this work, we combine two powerful existing techniques, one local (Integrated Gradients, IG) and one global (Testing with Concept Activation Vectors), to provide local, and global concept-based explanations. We first validate our idea using two synthetic datasets with a known ground truth, and further demonstrate with a benchmark natural image dataset. We test our method with various concepts, target classes, model architectures and IG baselines. We show that our method improves global explanations over TCAV when compared to ground truth, and provides useful insights. We hope our work provides a step towards building bridges between many existing local and global methods to get the best of both worlds.
Discovering a set of policies for the worst case reward
Feb 08, 2021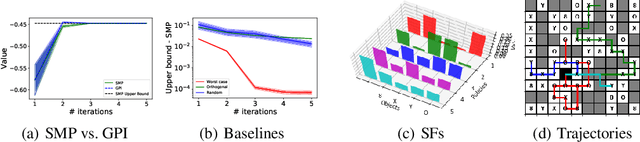
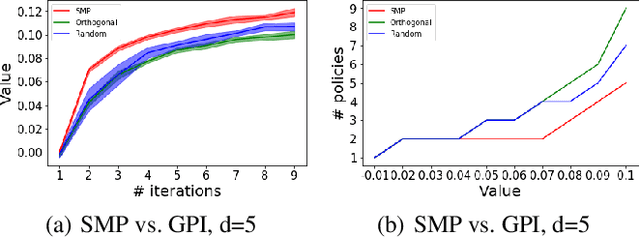
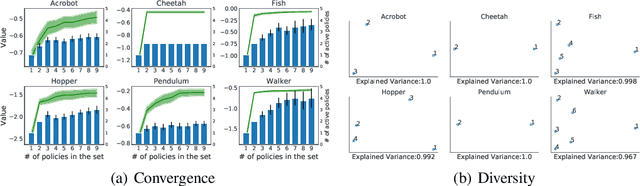

We study the problem of how to construct a set of policies that can be composed together to solve a collection of reinforcement learning tasks. Each task is a different reward function defined as a linear combination of known features. We consider a specific class of policy compositions which we call set improving policies (SIPs): given a set of policies and a set of tasks, a SIP is any composition of the former whose performance is at least as good as that of its constituents across all the tasks. We focus on the most conservative instantiation of SIPs, set-max policies (SMPs), so our analysis extends to any SIP. This includes known policy-composition operators like generalized policy improvement. Our main contribution is a policy iteration algorithm that builds a set of policies in order to maximize the worst-case performance of the resulting SMP on the set of tasks. The algorithm works by successively adding new policies to the set. We show that the worst-case performance of the resulting SMP strictly improves at each iteration, and the algorithm only stops when there does not exist a policy that leads to improved performance. We empirically evaluate our algorithm on a grid world and also on a set of domains from the DeepMind control suite. We confirm our theoretical results regarding the monotonically improving performance of our algorithm. Interestingly, we also show empirically that the sets of policies computed by the algorithm are diverse, leading to different trajectories in the grid world and very distinct locomotion skills in the control suite.
Concept-based model explanations for Electronic Health Records
Dec 03, 2020
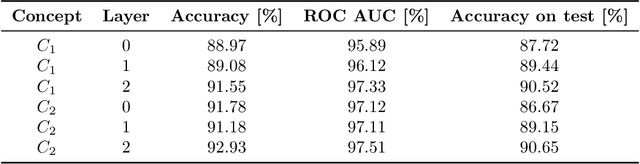
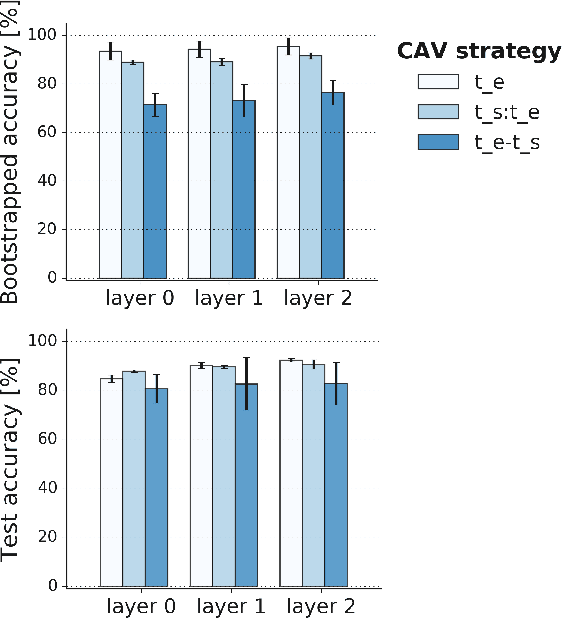
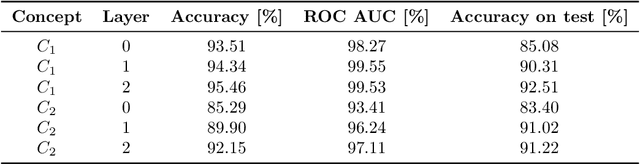
Recurrent Neural Networks (RNNs) are often used for sequential modeling of adverse outcomes in electronic health records (EHRs) due to their ability to encode past clinical states. These deep, recurrent architectures have displayed increased performance compared to other modeling approaches in a number of tasks, fueling the interest in deploying deep models in clinical settings. One of the key elements in ensuring safe model deployment and building user trust is model explainability. Testing with Concept Activation Vectors (TCAV) has recently been introduced as a way of providing human-understandable explanations by comparing high-level concepts to the network's gradients. While the technique has shown promising results in real-world imaging applications, it has not been applied to structured temporal inputs. To enable an application of TCAV to sequential predictions in the EHR, we propose an extension of the method to time series data. We evaluate the proposed approach on an open EHR benchmark from the intensive care unit, as well as synthetic data where we are able to better isolate individual effects.
Underspecification Presents Challenges for Credibility in Modern Machine Learning
Nov 06, 2020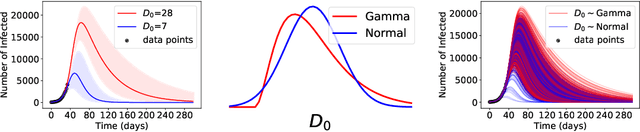

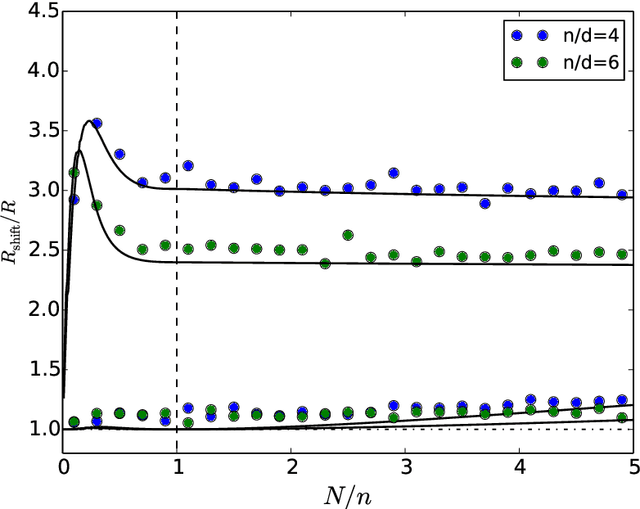

ML models often exhibit unexpectedly poor behavior when they are deployed in real-world domains. We identify underspecification as a key reason for these failures. An ML pipeline is underspecified when it can return many predictors with equivalently strong held-out performance in the training domain. Underspecification is common in modern ML pipelines, such as those based on deep learning. Predictors returned by underspecified pipelines are often treated as equivalent based on their training domain performance, but we show here that such predictors can behave very differently in deployment domains. This ambiguity can lead to instability and poor model behavior in practice, and is a distinct failure mode from previously identified issues arising from structural mismatch between training and deployment domains. We show that this problem appears in a wide variety of practical ML pipelines, using examples from computer vision, medical imaging, natural language processing, clinical risk prediction based on electronic health records, and medical genomics. Our results show the need to explicitly account for underspecification in modeling pipelines that are intended for real-world deployment in any domain.