 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest of both worlds: local and global explanations with human-understandable concepts
Jun 16, 2021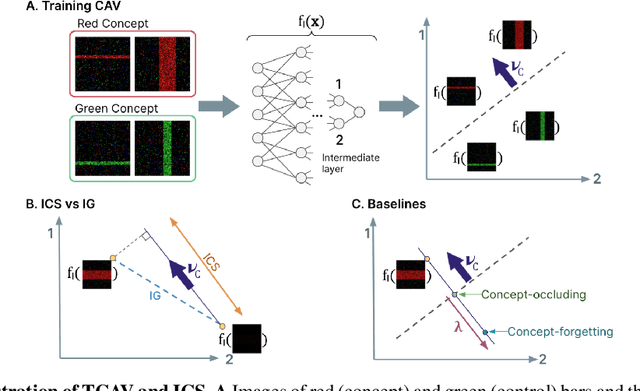
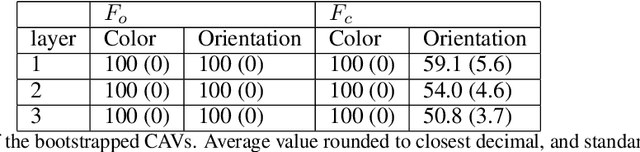
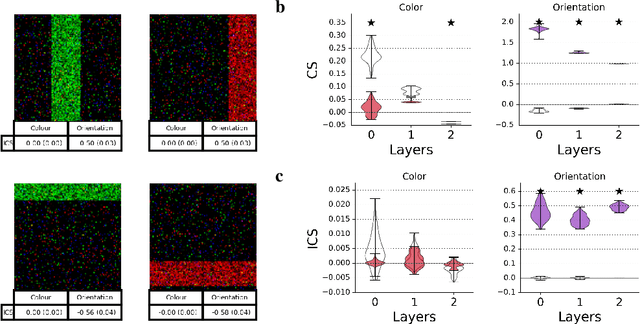
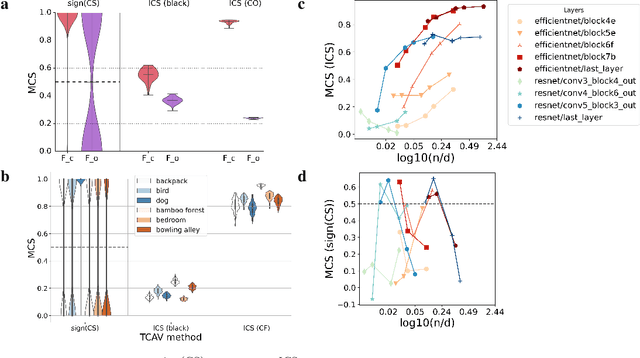
Interpretability techniques aim to provide the rationale behind a model's decision, typically by explaining either an individual prediction (local explanation, e.g. `why is this patient diagnosed with this condition') or a class of predictions (global explanation, e.g. `why are patients diagnosed with this condition in general'). While there are many methods focused on either one, few frameworks can provide both local and global explanations in a consistent manner. In this work, we combine two powerful existing techniques, one local (Integrated Gradients, IG) and one global (Testing with Concept Activation Vectors), to provide local, and global concept-based explanations. We first validate our idea using two synthetic datasets with a known ground truth, and further demonstrate with a benchmark natural image dataset. We test our method with various concepts, target classes, model architectures and IG baselines. We show that our method improves global explanations over TCAV when compared to ground truth, and provides useful insights. We hope our work provides a step towards building bridges between many existing local and global methods to get the best of both worlds.