 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderspecification Presents Challenges for Credibility in Modern Machine Learning
Nov 06, 2020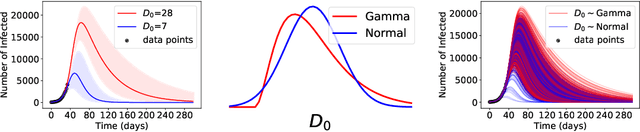


ML models often exhibit unexpectedly poor behavior when they are deployed in real-world domains. We identify underspecification as a key reason for these failures. An ML pipeline is underspecified when it can return many predictors with equivalently strong held-out performance in the training domain. Underspecification is common in modern ML pipelines, such as those based on deep learning. Predictors returned by underspecified pipelines are often treated as equivalent based on their training domain performance, but we show here that such predictors can behave very differently in deployment domains. This ambiguity can lead to instability and poor model behavior in practice, and is a distinct failure mode from previously identified issues arising from structural mismatch between training and deployment domains. We show that this problem appears in a wide variety of practical ML pipelines, using examples from computer vision, medical imaging, natural language processing, clinical risk prediction based on electronic health records, and medical genomics. Our results show the need to explicitly account for underspecification in modeling pipelines that are intended for real-world deployment in any domain.