 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeAR -- Health Acoustic Representations
Mar 04, 2024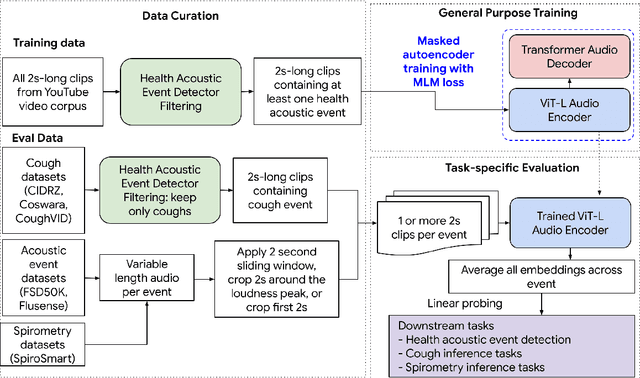

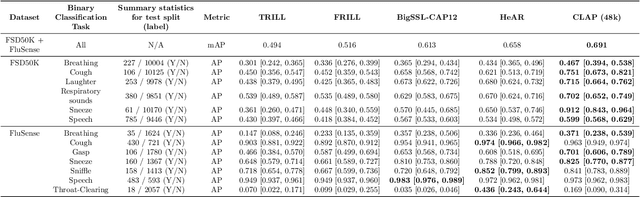
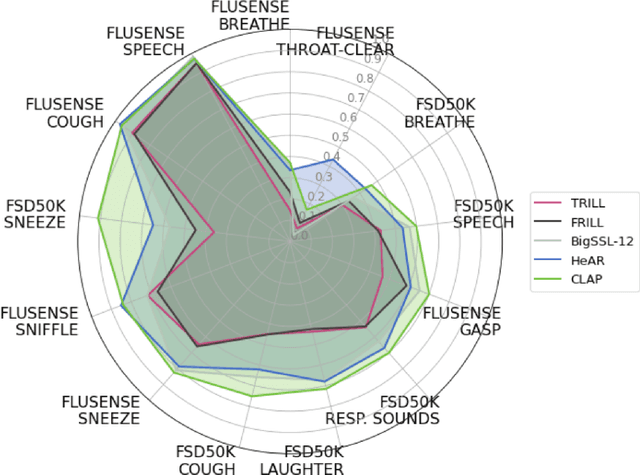
Health acoustic sounds such as coughs and breaths are known to contain useful health signals with significant potential for monitoring health and disease, yet are underexplored in the medical machine learning community. The existing deep learning systems for health acoustics are often narrowly trained and evaluated on a single task, which is limited by data and may hinder generalization to other tasks. To mitigate these gaps, we develop HeAR, a scalable self-supervised learning-based deep learning system using masked autoencoders trained on a large dataset of 313 million two-second long audio clips. Through linear probes, we establish HeAR as a state-of-the-art health audio embedding model on a benchmark of 33 health acoustic tasks across 6 datasets. By introducing this work, we hope to enable and accelerate further health acoustics research.
ELIXR: Towards a general purpose X-ray artificial intelligence system through alignment of large language models and radiology vision encoders
Aug 02, 2023Our approach, which we call Embeddings for Language/Image-aligned X-Rays, or ELIXR, leverages a language-aligned image encoder combined or grafted onto a fixed LLM, PaLM 2, to perform a broad range of tasks. We train this lightweight adapter architecture using images paired with corresponding free-text radiology reports from the MIMIC-CXR dataset. ELIXR achieved state-of-the-art performance on zero-shot chest X-ray (CXR) classification (mean AUC of 0.850 across 13 findings), data-efficient CXR classification (mean AUCs of 0.893 and 0.898 across five findings (atelectasis, cardiomegaly, consolidation, pleural effusion, and pulmonary edema) for 1% (~2,200 images) and 10% (~22,000 images) training data), and semantic search (0.76 normalized discounted cumulative gain (NDCG) across nineteen queries, including perfect retrieval on twelve of them). Compared to existing data-efficient methods including supervised contrastive learning (SupCon), ELIXR required two orders of magnitude less data to reach similar performance. ELIXR also showed promise on CXR vision-language tasks, demonstrating overall accuracies of 58.7% and 62.5% on visual question answering and report quality assurance tasks, respectively. These results suggest that ELIXR is a robust and versatile approach to CXR AI.
Predicting Cardiovascular Disease Risk using Photoplethysmography and Deep Learning
May 09, 2023Cardiovascular diseases (CVDs) are responsible for a large proportion of premature deaths in low- and middle-income countries. Early CVD detection and intervention is critical in these populations, yet many existing CVD risk scores require a physical examination or lab measurements, which can be challenging in such health systems due to limited accessibility. Here we investigated the potential to use photoplethysmography (PPG), a sensing technology available on most smartphones that can potentially enable large-scale screening at low cost, for CVD risk prediction. We developed a deep learning PPG-based CVD risk score (DLS) to predict the probability of having major adverse cardiovascular events (MACE: non-fatal myocardial infarction, stroke, and cardiovascular death) within ten years, given only age, sex, smoking status and PPG as predictors. We compared the DLS with the office-based refit-WHO score, which adopts the shared predictors from WHO and Globorisk scores (age, sex, smoking status, height, weight and systolic blood pressure) but refitted on the UK Biobank (UKB) cohort. In UKB cohort, DLS's C-statistic (71.1%, 95% CI 69.9-72.4) was non-inferior to office-based refit-WHO score (70.9%, 95% CI 69.7-72.2; non-inferiority margin of 2.5%, p<0.01). The calibration of the DLS was satisfactory, with a 1.8% mean absolute calibration error. Adding DLS features to the office-based score increased the C-statistic by 1.0% (95% CI 0.6-1.4). DLS predicts ten-year MACE risk comparable with the office-based refit-WHO score. It provides a proof-of-concept and suggests the potential of a PPG-based approach strategies for community-based primary prevention in resource-limited regions.
Machine learning for dynamically predicting the onset of renal replacement therapy in chronic kidney disease patients using claims data
Sep 03, 2022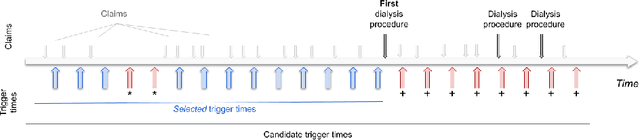
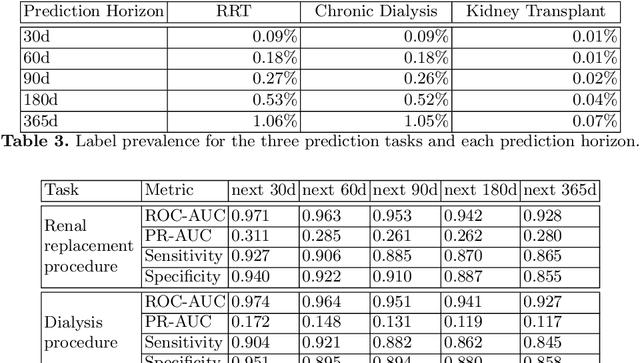
Chronic kidney disease (CKD) represents a slowly progressive disorder that can eventually require renal replacement therapy (RRT) including dialysis or renal transplantation. Early identification of patients who will require RRT (as much as 1 year in advance) improves patient outcomes, for example by allowing higher-quality vascular access for dialysis. Therefore, early recognition of the need for RRT by care teams is key to successfully managing the disease. Unfortunately, there is currently no commonly used predictive tool for RRT initiation. In this work, we present a machine learning model that dynamically identifies CKD patients at risk of requiring RRT up to one year in advance using only claims data. To evaluate the model, we studied approximately 3 million Medicare beneficiaries for which we made over 8 million predictions. We showed that the model can identify at risk patients with over 90% sensitivity and specificity. Although additional work is required before this approach is ready for clinical use, this study provides a basis for a screening tool to identify patients at risk within a time window that enables early proactive interventions intended to improve RRT outcomes.
Discovering novel systemic biomarkers in photos of the external eye
Jul 19, 2022
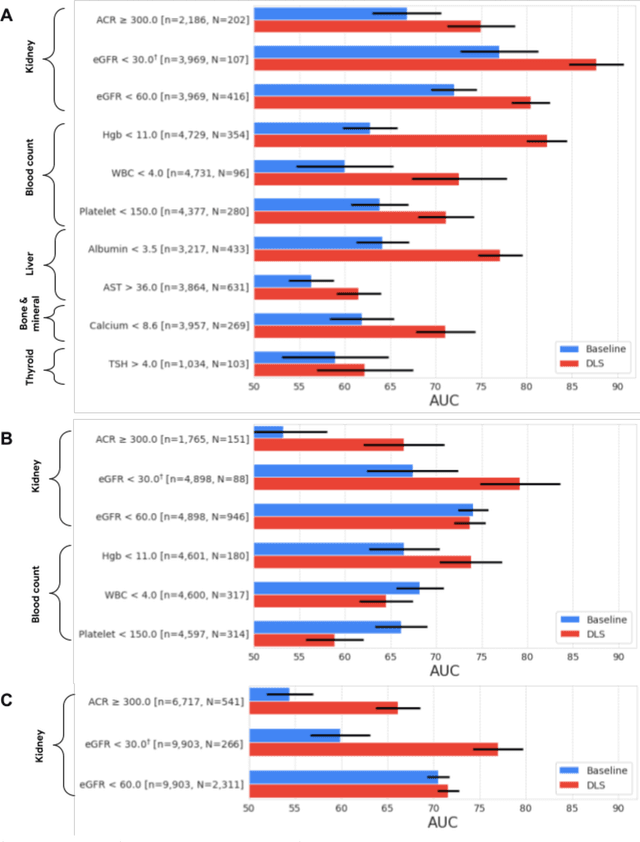
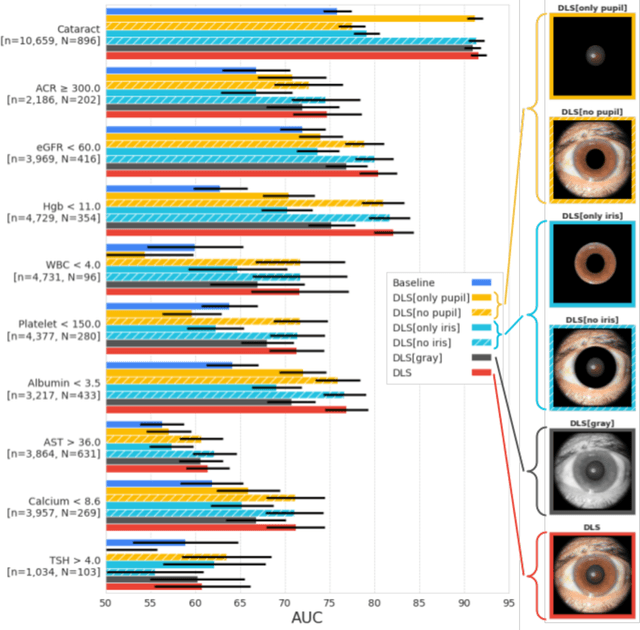
External eye photos were recently shown to reveal signs of diabetic retinal disease and elevated HbA1c. In this paper, we evaluate if external eye photos contain information about additional systemic medical conditions. We developed a deep learning system (DLS) that takes external eye photos as input and predicts multiple systemic parameters, such as those related to the liver (albumin, AST); kidney (eGFR estimated using the race-free 2021 CKD-EPI creatinine equation, the urine ACR); bone & mineral (calcium); thyroid (TSH); and blood count (Hgb, WBC, platelets). Development leveraged 151,237 images from 49,015 patients with diabetes undergoing diabetic eye screening in 11 sites across Los Angeles county, CA. Evaluation focused on 9 pre-specified systemic parameters and leveraged 3 validation sets (A, B, C) spanning 28,869 patients with and without diabetes undergoing eye screening in 3 independent sites in Los Angeles County, CA, and the greater Atlanta area, GA. We compared against baseline models incorporating available clinicodemographic variables (e.g. age, sex, race/ethnicity, years with diabetes). Relative to the baseline, the DLS achieved statistically significant superior performance at detecting AST>36, calcium<8.6, eGFR<60, Hgb<11, platelets<150, ACR>=300, and WBC<4 on validation set A (a patient population similar to the development sets), where the AUC of DLS exceeded that of the baseline by 5.2-19.4%. On validation sets B and C, with substantial patient population differences compared to the development sets, the DLS outperformed the baseline for ACR>=300 and Hgb<11 by 7.3-13.2%. Our findings provide further evidence that external eye photos contain important biomarkers of systemic health spanning multiple organ systems. Further work is needed to investigate whether and how these biomarkers can be translated into clinical impact.
Boosting the interpretability of clinical risk scores with intervention predictions
Jul 06, 2022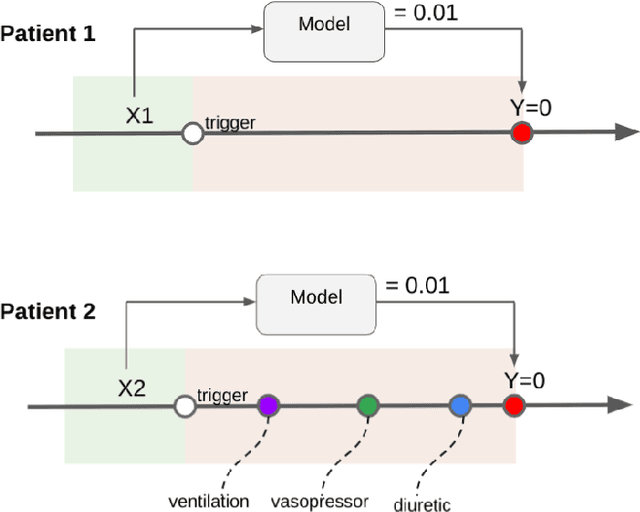
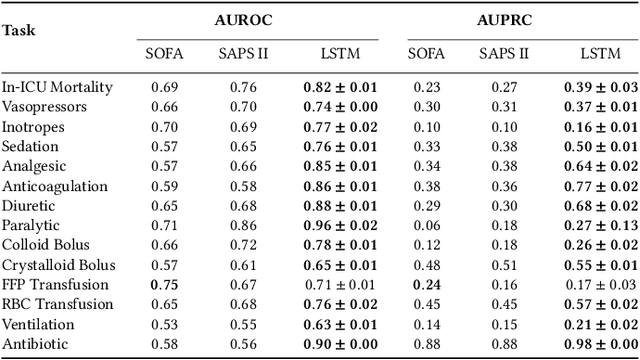
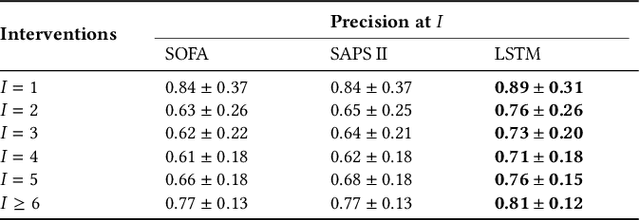
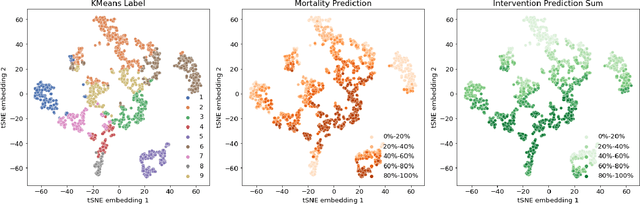
Machine learning systems show significant promise for forecasting patient adverse events via risk scores. However, these risk scores implicitly encode assumptions about future interventions that the patient is likely to receive, based on the intervention policy present in the training data. Without this important context, predictions from such systems are less interpretable for clinicians. We propose a joint model of intervention policy and adverse event risk as a means to explicitly communicate the model's assumptions about future interventions. We develop such an intervention policy model on MIMIC-III, a real world de-identified ICU dataset, and discuss some use cases that highlight the utility of this approach. We show how combining typical risk scores, such as the likelihood of mortality, with future intervention probability scores leads to more interpretable clinical predictions.
Disability prediction in multiple sclerosis using performance outcome measures and demographic data
Apr 08, 2022


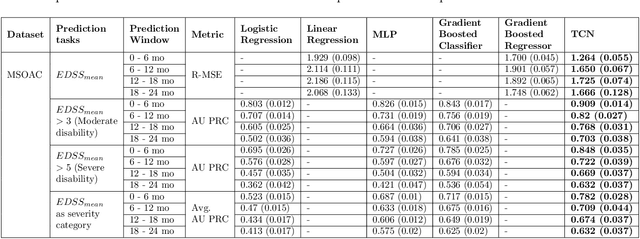
Literature on machine learning for multiple sclerosis has primarily focused on the use of neuroimaging data such as magnetic resonance imaging and clinical laboratory tests for disease identification. However, studies have shown that these modalities are not consistent with disease activity such as symptoms or disease progression. Furthermore, the cost of collecting data from these modalities is high, leading to scarce evaluations. In this work, we used multi-dimensional, affordable, physical and smartphone-based performance outcome measures (POM) in conjunction with demographic data to predict multiple sclerosis disease progression. We performed a rigorous benchmarking exercise on two datasets and present results across 13 clinically actionable prediction endpoints and 6 machine learning models. To the best of our knowledge, our results are the first to show that it is possible to predict disease progression using POMs and demographic data in the context of both clinical trials and smartphone-base studies by using two datasets. Moreover, we investigate our models to understand the impact of different POMs and demographics on model performance through feature ablation studies. We also show that model performance is similar across different demographic subgroups (based on age and sex). To enable this work, we developed an end-to-end reusable pre-processing and machine learning framework which allows quicker experimentation over disparate MS datasets.
Enabling faster and more reliable sonographic assessment of gestational age through machine learning
Mar 22, 2022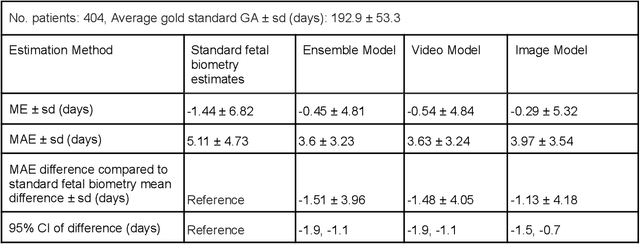
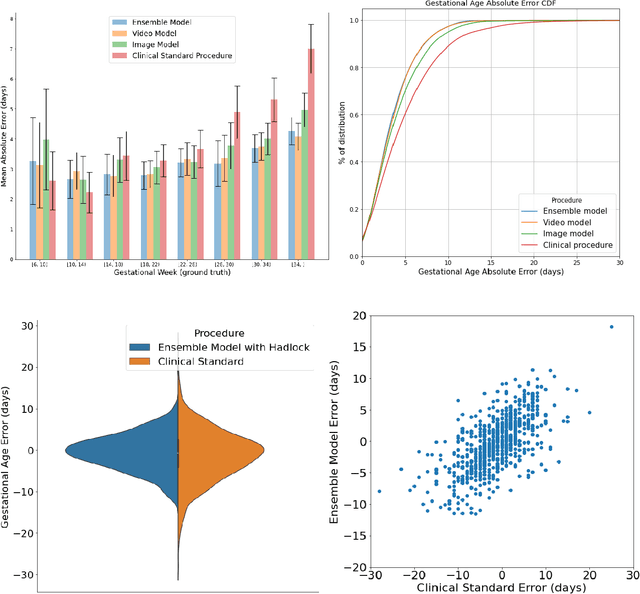
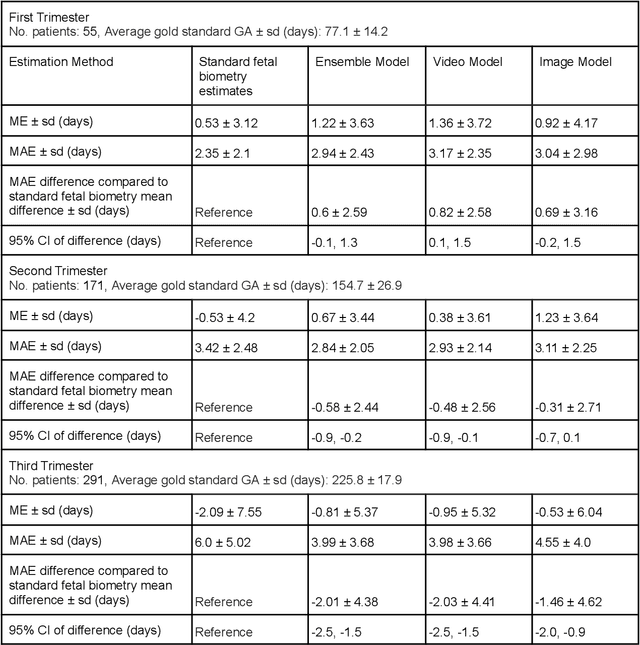
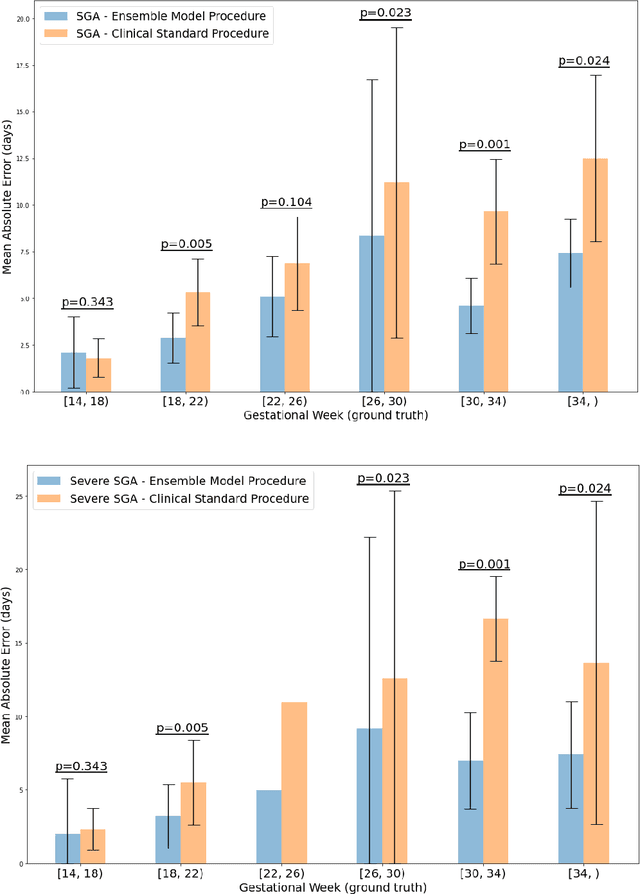
Fetal ultrasounds are an essential part of prenatal care and can be used to estimate gestational age (GA). Accurate GA assessment is important for providing appropriate prenatal care throughout pregnancy and identifying complications such as fetal growth disorders. Since derivation of GA from manual fetal biometry measurements (head, abdomen, femur) are operator-dependent and time-consuming, there have been a number of research efforts focused on using artificial intelligence (AI) models to estimate GA using standard biometry images, but there is still room to improve the accuracy and reliability of these AI systems for widescale adoption. To improve GA estimates, without significant change to provider workflows, we leverage AI to interpret standard plane ultrasound images as well as 'fly-to' ultrasound videos, which are 5-10s videos automatically recorded as part of the standard of care before the still image is captured. We developed and validated three AI models: an image model using standard plane images, a video model using fly-to videos, and an ensemble model (combining both image and video). All three were statistically superior to standard fetal biometry-based GA estimates derived by expert sonographers, the ensemble model has the lowest mean absolute error (MAE) compared to the clinical standard fetal biometry (mean difference: -1.51 $\pm$ 3.96 days, 95% CI [-1.9, -1.1]) on a test set that consisted of 404 participants. We showed that our models outperform standard biometry by a more substantial margin on fetuses that were small for GA. Our AI models have the potential to empower trained operators to estimate GA with higher accuracy while reducing the amount of time required and user variability in measurement acquisition.
AI system for fetal ultrasound in low-resource settings
Mar 18, 2022
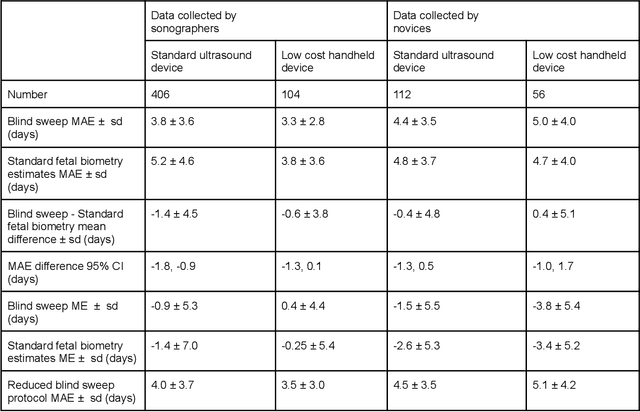

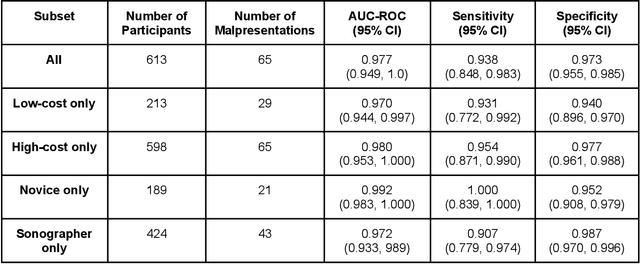
Despite considerable progress in maternal healthcare, maternal and perinatal deaths remain high in low-to-middle income countries. Fetal ultrasound is an important component of antenatal care, but shortage of adequately trained healthcare workers has limited its adoption. We developed and validated an artificial intelligence (AI) system that uses novice-acquired "blind sweep" ultrasound videos to estimate gestational age (GA) and fetal malpresentation. We further addressed obstacles that may be encountered in low-resourced settings. Using a simplified sweep protocol with real-time AI feedback on sweep quality, we have demonstrated the generalization of model performance to minimally trained novice ultrasound operators using low cost ultrasound devices with on-device AI integration. The GA model was non-inferior to standard fetal biometry estimates with as few as two sweeps, and the fetal malpresentation model had high AUC-ROCs across operators and devices. Our AI models have the potential to assist in upleveling the capabilities of lightly trained ultrasound operators in low resource settings.
Maintaining fairness across distribution shift: do we have viable solutions for real-world applications?
Feb 02, 2022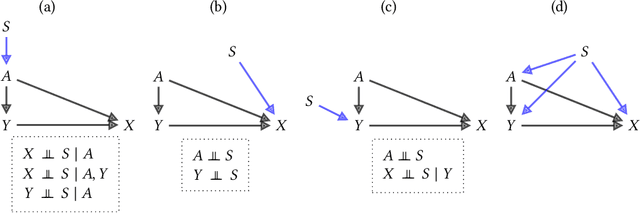
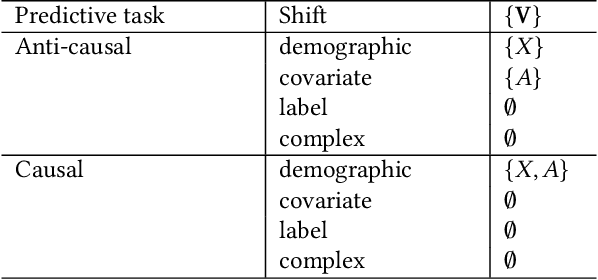
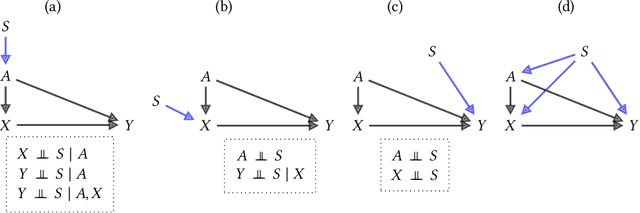
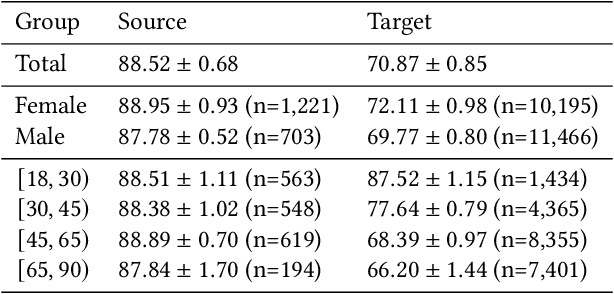
Fairness and robustness are often considered as orthogonal dimensions when evaluating machine learning models. However, recent work has revealed interactions between fairness and robustness, showing that fairness properties are not necessarily maintained under distribution shift. In healthcare settings, this can result in e.g. a model that performs fairly according to a selected metric in "hospital A" showing unfairness when deployed in "hospital B". While a nascent field has emerged to develop provable fair and robust models, it typically relies on strong assumptions about the shift, limiting its impact for real-world applications. In this work, we explore the settings in which recently proposed mitigation strategies are applicable by referring to a causal framing. Using examples of predictive models in dermatology and electronic health records, we show that real-world applications are complex and often invalidate the assumptions of such methods. Our work hence highlights technical, practical, and engineering gaps that prevent the development of robustly fair machine learning models for real-world applications. Finally, we discuss potential remedies at each step of the machine learning pipeline.