 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViMGuard: A Novel Multi-Modal System for Video Misinformation Guarding
Oct 22, 2024


The rise of social media and short-form video (SFV) has facilitated a breeding ground for misinformation. With the emergence of large language models, significant research has gone into curbing this misinformation problem with automatic false claim detection for text. Unfortunately, the automatic detection of misinformation in SFV is a more complex problem that remains largely unstudied. While text samples are monomodal (only containing words), SFVs comprise three different modalities: words, visuals, and non-linguistic audio. In this work, we introduce Video Masked Autoencoders for Misinformation Guarding (ViMGuard), the first deep-learning architecture capable of fact-checking an SFV through analysis of all three of its constituent modalities. ViMGuard leverages a dual-component system. First, Video and Audio Masked Autoencoders analyze the visual and non-linguistic audio elements of a video to discern its intention; specifically whether it intends to make an informative claim. If it is deemed that the SFV has informative intent, it is passed through our second component: a Retrieval Augmented Generation system that validates the factual accuracy of spoken words. In evaluation, ViMGuard outperformed three cutting-edge fact-checkers, thus setting a new standard for SFV fact-checking and marking a significant stride toward trustworthy news on social platforms. To promote further testing and iteration, VimGuard was deployed into a Chrome extension and all code was open-sourced on GitHub.
Merlin: A Vision Language Foundation Model for 3D Computed Tomography
Jun 10, 2024



Over 85 million computed tomography (CT) scans are performed annually in the US, of which approximately one quarter focus on the abdomen. Given the current radiologist shortage, there is a large impetus to use artificial intelligence to alleviate the burden of interpreting these complex imaging studies. Prior state-of-the-art approaches for automated medical image interpretation leverage vision language models (VLMs). However, current medical VLMs are generally limited to 2D images and short reports, and do not leverage electronic health record (EHR) data for supervision. We introduce Merlin - a 3D VLM that we train using paired CT scans (6+ million images from 15,331 CTs), EHR diagnosis codes (1.8+ million codes), and radiology reports (6+ million tokens). We evaluate Merlin on 6 task types and 752 individual tasks. The non-adapted (off-the-shelf) tasks include zero-shot findings classification (31 findings), phenotype classification (692 phenotypes), and zero-shot cross-modal retrieval (image to findings and image to impressions), while model adapted tasks include 5-year disease prediction (6 diseases), radiology report generation, and 3D semantic segmentation (20 organs). We perform internal validation on a test set of 5,137 CTs, and external validation on 7,000 clinical CTs and on two public CT datasets (VerSe, TotalSegmentator). Beyond these clinically-relevant evaluations, we assess the efficacy of various network architectures and training strategies to depict that Merlin has favorable performance to existing task-specific baselines. We derive data scaling laws to empirically assess training data needs for requisite downstream task performance. Furthermore, unlike conventional VLMs that require hundreds of GPUs for training, we perform all training on a single GPU.
HeAR -- Health Acoustic Representations
Mar 04, 2024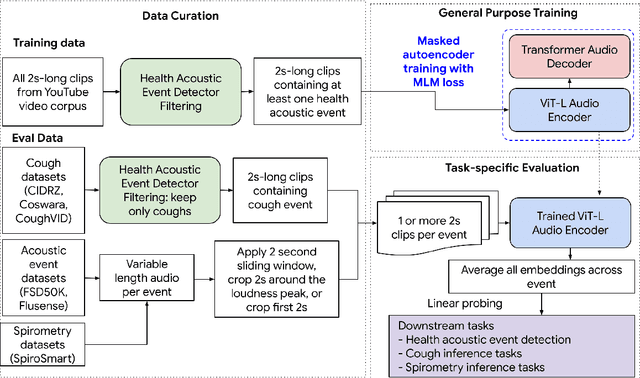

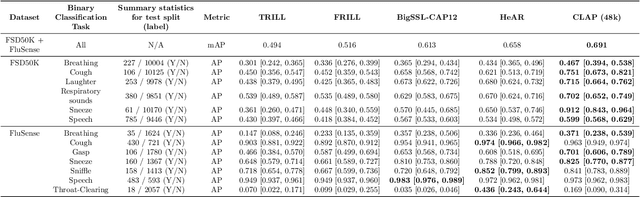
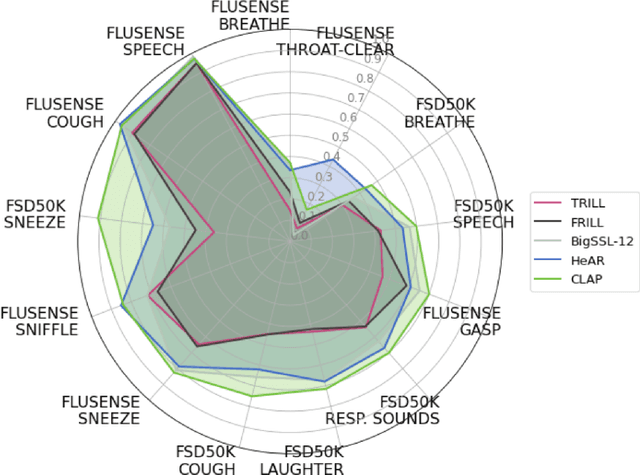
Health acoustic sounds such as coughs and breaths are known to contain useful health signals with significant potential for monitoring health and disease, yet are underexplored in the medical machine learning community. The existing deep learning systems for health acoustics are often narrowly trained and evaluated on a single task, which is limited by data and may hinder generalization to other tasks. To mitigate these gaps, we develop HeAR, a scalable self-supervised learning-based deep learning system using masked autoencoders trained on a large dataset of 313 million two-second long audio clips. Through linear probes, we establish HeAR as a state-of-the-art health audio embedding model on a benchmark of 33 health acoustic tasks across 6 datasets. By introducing this work, we hope to enable and accelerate further health acoustics research.
Optimizing Audio Augmentations for Contrastive Learning of Health-Related Acoustic Signals
Sep 11, 2023

Health-related acoustic signals, such as cough and breathing sounds, are relevant for medical diagnosis and continuous health monitoring. Most existing machine learning approaches for health acoustics are trained and evaluated on specific tasks, limiting their generalizability across various healthcare applications. In this paper, we leverage a self-supervised learning framework, SimCLR with a Slowfast NFNet backbone, for contrastive learning of health acoustics. A crucial aspect of optimizing Slowfast NFNet for this application lies in identifying effective audio augmentations. We conduct an in-depth analysis of various audio augmentation strategies and demonstrate that an appropriate augmentation strategy enhances the performance of the Slowfast NFNet audio encoder across a diverse set of health acoustic tasks. Our findings reveal that when augmentations are combined, they can produce synergistic effects that exceed the benefits seen when each is applied individually.
Predicting Poverty Level from Satellite Imagery using Deep Neural Networks
Nov 30, 2021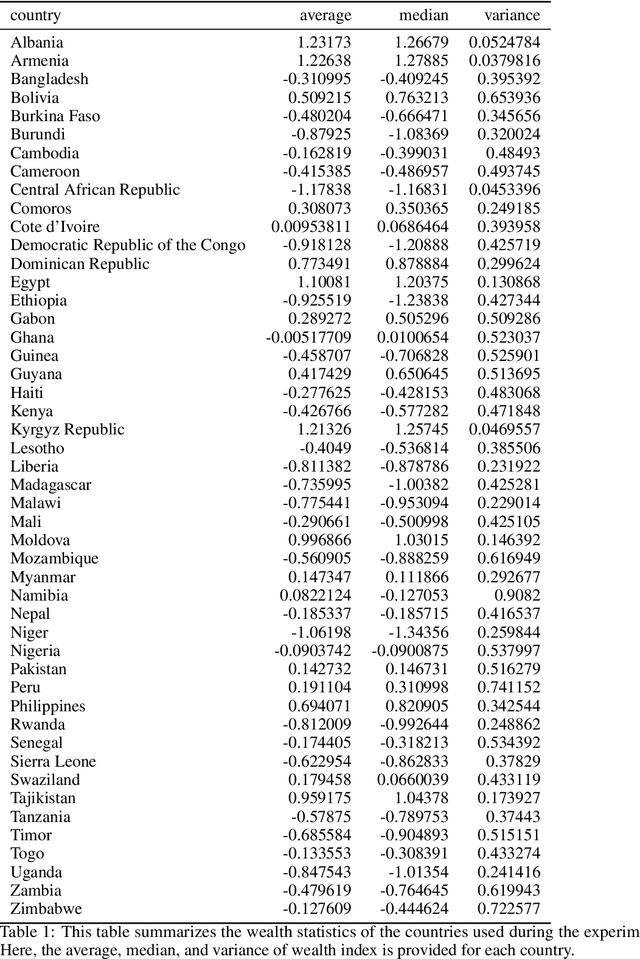


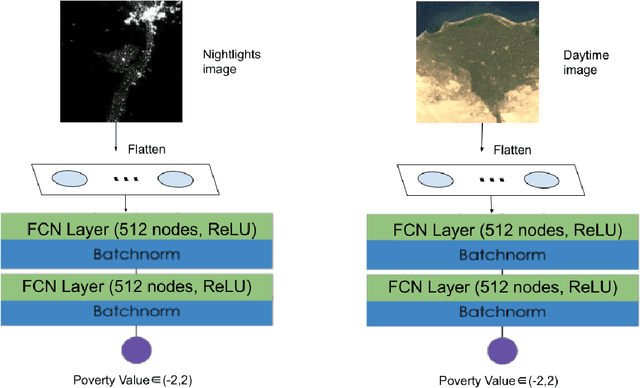
Determining the poverty levels of various regions throughout the world is crucial in identifying interventions for poverty reduction initiatives and directing resources fairly. However, reliable data on global economic livelihoods is hard to come by, especially for areas in the developing world, hampering efforts to both deploy services and monitor/evaluate progress. This is largely due to the fact that this data is obtained from traditional door-to-door surveys, which are time consuming and expensive. Overhead satellite imagery contain characteristics that make it possible to estimate the region's poverty level. In this work, I develop deep learning computer vision methods that can predict a region's poverty level from an overhead satellite image. I experiment with both daytime and nighttime imagery. Furthermore, because data limitations are often the barrier to entry in poverty prediction from satellite imagery, I explore the impact that data quantity and data augmentation have on the representational power and overall accuracy of the networks. Lastly, to evaluate the robustness of the networks, I evaluate them on data from continents that were absent in the development set.
Deep learning for detecting pulmonary tuberculosis via chest radiography: an international study across 10 countries
May 16, 2021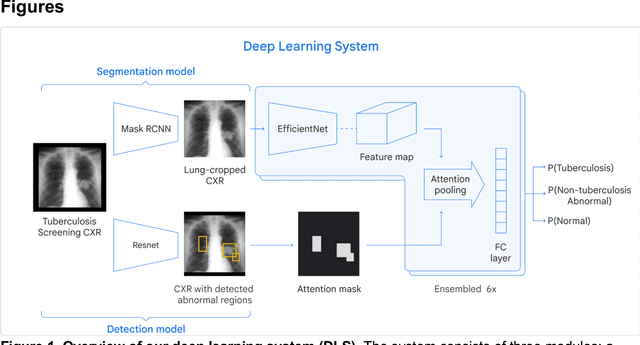
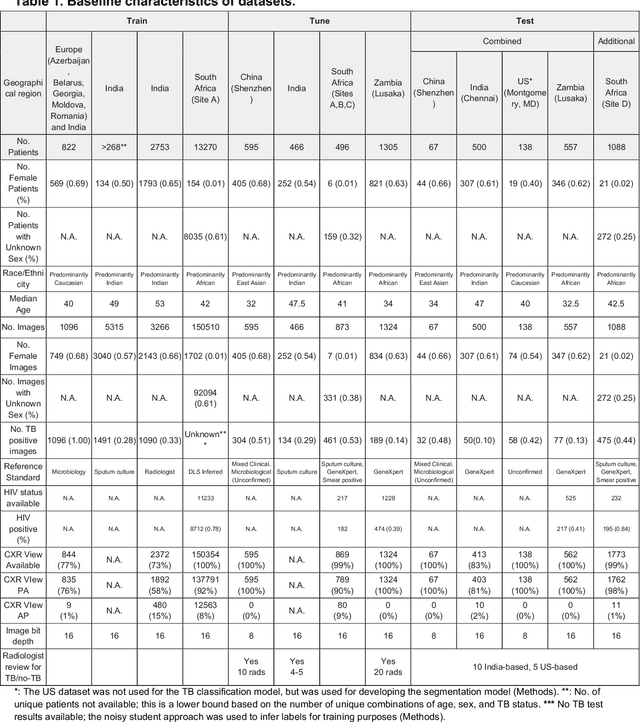
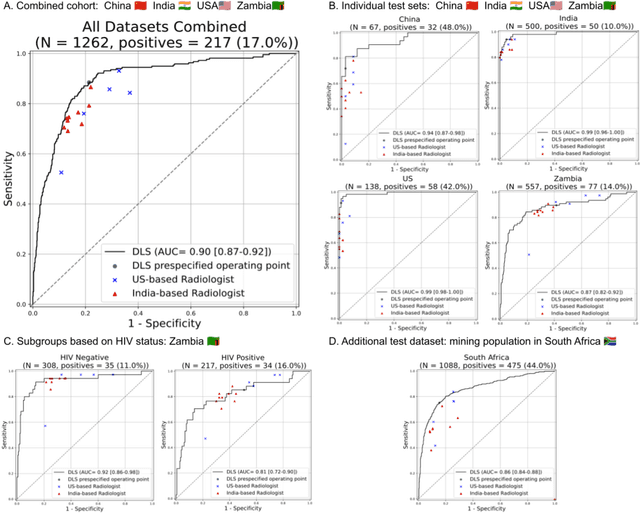
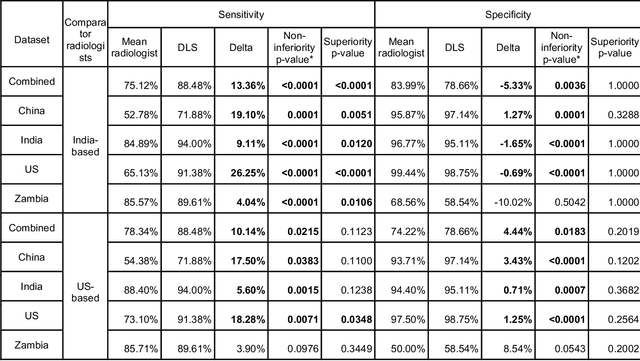
Tuberculosis (TB) is a top-10 cause of death worldwide. Though the WHO recommends chest radiographs (CXRs) for TB screening, the limited availability of CXR interpretation is a barrier. We trained a deep learning system (DLS) to detect active pulmonary TB using CXRs from 9 countries across Africa, Asia, and Europe, and utilized large-scale CXR pretraining, attention pooling, and noisy student semi-supervised learning. Evaluation was on (1) a combined test set spanning China, India, US, and Zambia, and (2) an independent mining population in South Africa. Given WHO targets of 90% sensitivity and 70% specificity, the DLS's operating point was prespecified to favor sensitivity over specificity. On the combined test set, the DLS's ROC curve was above all 9 India-based radiologists, with an AUC of 0.90 (95%CI 0.87-0.92). The DLS's sensitivity (88%) was higher than the India-based radiologists (75% mean sensitivity), p<0.001 for superiority; and its specificity (79%) was non-inferior to the radiologists (84% mean specificity), p=0.004. Similar trends were observed within HIV positive and sputum smear positive sub-groups, and in the South Africa test set. We found that 5 US-based radiologists (where TB isn't endemic) were more sensitive and less specific than the India-based radiologists (where TB is endemic). The DLS also remained non-inferior to the US-based radiologists. In simulations, using the DLS as a prioritization tool for confirmatory testing reduced the cost per positive case detected by 40-80% compared to using confirmatory testing alone. To conclude, our DLS generalized to 5 countries, and merits prospective evaluation to assist cost-effective screening efforts in radiologist-limited settings. Operating point flexibility may permit customization of the DLS to account for site-specific factors such as TB prevalence, demographics, clinical resources, and customary practice patterns.
Deep Learning for Distinguishing Normal versus Abnormal Chest Radiographs and Generalization to Unseen Diseases
Oct 22, 2020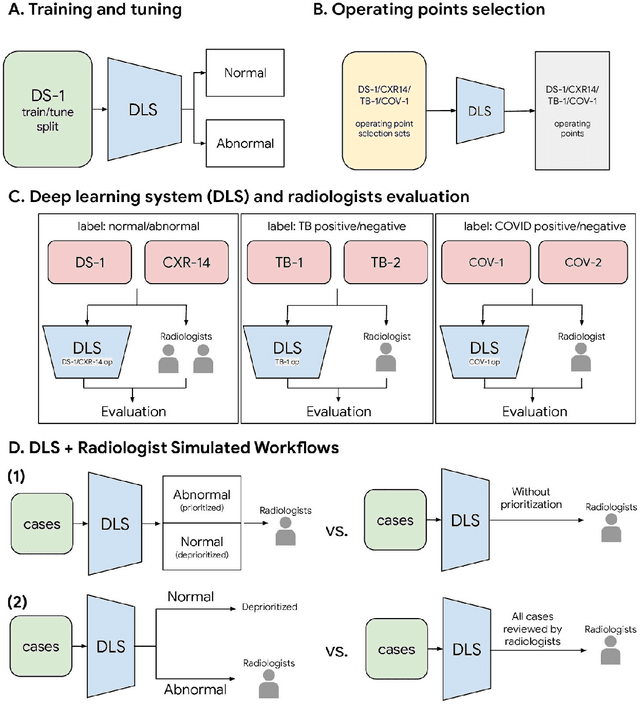
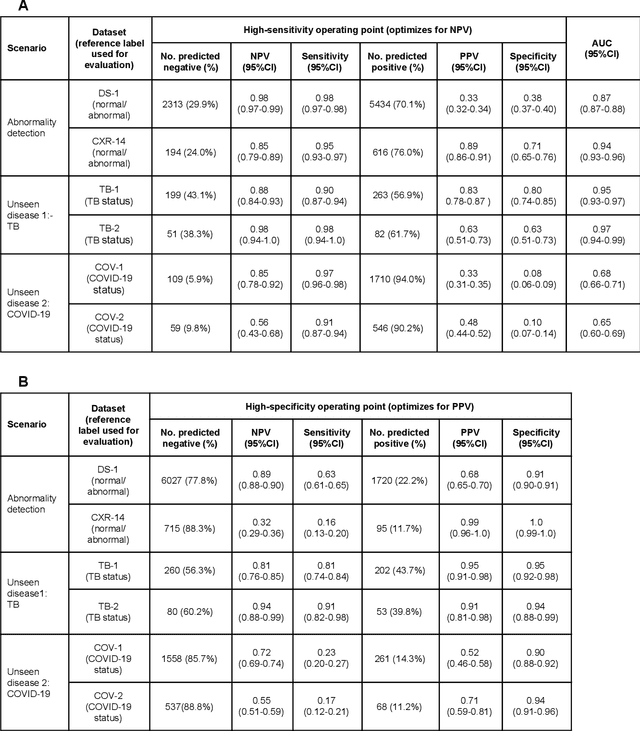
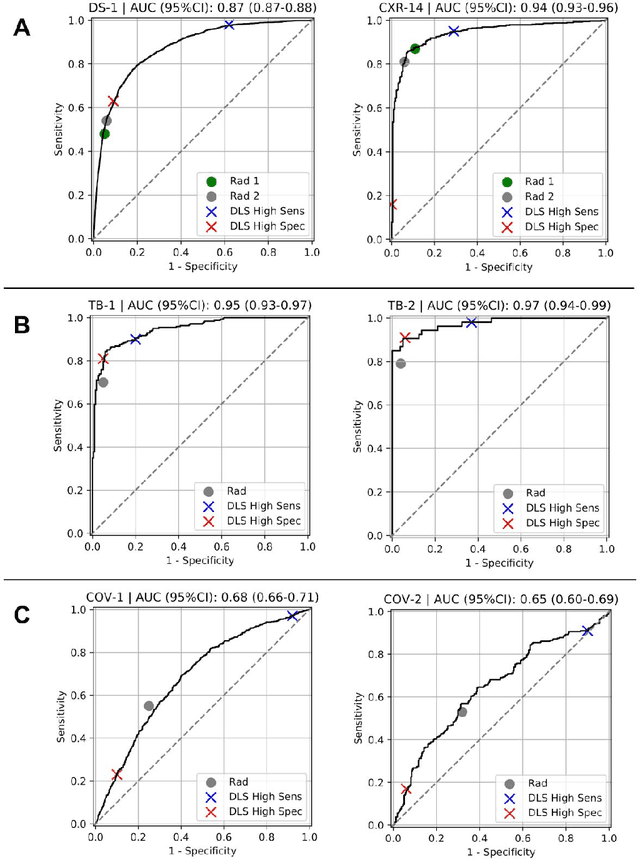
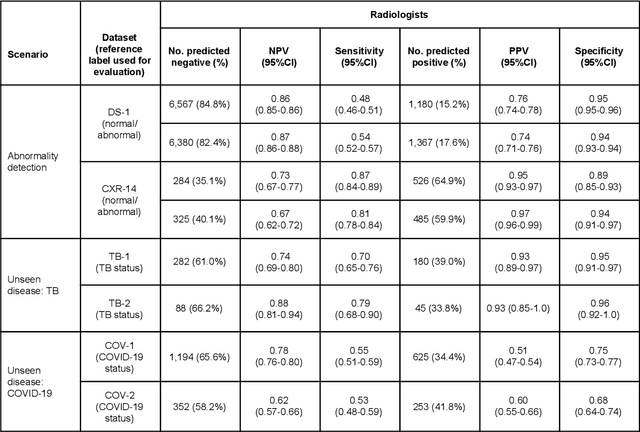
Chest radiography (CXR) is the most widely-used thoracic clinical imaging modality and is crucial for guiding the management of cardiothoracic conditions. The detection of specific CXR findings has been the main focus of several artificial intelligence (AI) systems. However, the wide range of possible CXR abnormalities makes it impractical to build specific systems to detect every possible condition. In this work, we developed and evaluated an AI system to classify CXRs as normal or abnormal. For development, we used a de-identified dataset of 248,445 patients from a multi-city hospital network in India. To assess generalizability, we evaluated our system using 6 international datasets from India, China, and the United States. Of these datasets, 4 focused on diseases that the AI was not trained to detect: 2 datasets with tuberculosis and 2 datasets with coronavirus disease 2019. Our results suggest that the AI system generalizes to new patient populations and abnormalities. In a simulated workflow where the AI system prioritized abnormal cases, the turnaround time for abnormal cases reduced by 7-28%. These results represent an important step towards evaluating whether AI can be safely used to flag cases in a general setting where previously unseen abnormalities exist.