 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Geospatial Inference with a Population Dynamics Foundation Model
Nov 13, 2024



Supporting the health and well-being of dynamic populations around the world requires governmental agencies, organizations and researchers to understand and reason over complex relationships between human behavior and local contexts in order to identify high-risk groups and strategically allocate limited resources. Traditional approaches to these classes of problems often entail developing manually curated, task-specific features and models to represent human behavior and the natural and built environment, which can be challenging to adapt to new, or even, related tasks. To address this, we introduce a Population Dynamics Foundation Model (PDFM) that aims to capture the relationships between diverse data modalities and is applicable to a broad range of geospatial tasks. We first construct a geo-indexed dataset for postal codes and counties across the United States, capturing rich aggregated information on human behavior from maps, busyness, and aggregated search trends, and environmental factors such as weather and air quality. We then model this data and the complex relationships between locations using a graph neural network, producing embeddings that can be adapted to a wide range of downstream tasks using relatively simple models. We evaluate the effectiveness of our approach by benchmarking it on 27 downstream tasks spanning three distinct domains: health indicators, socioeconomic factors, and environmental measurements. The approach achieves state-of-the-art performance on all 27 geospatial interpolation tasks, and on 25 out of the 27 extrapolation and super-resolution tasks. We combined the PDFM with a state-of-the-art forecasting foundation model, TimesFM, to predict unemployment and poverty, achieving performance that surpasses fully supervised forecasting. The full set of embeddings and sample code are publicly available for researchers.
Plots Unlock Time-Series Understanding in Multimodal Models
Oct 03, 2024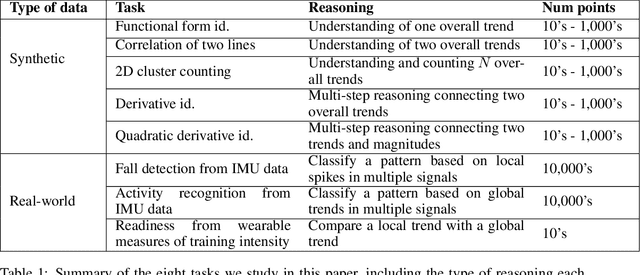

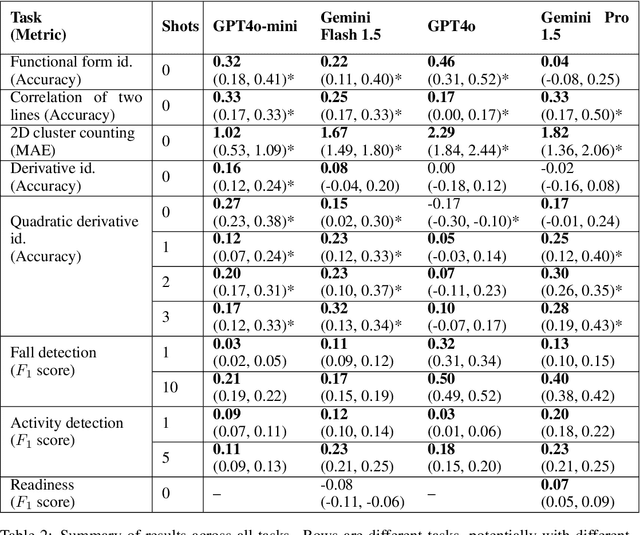
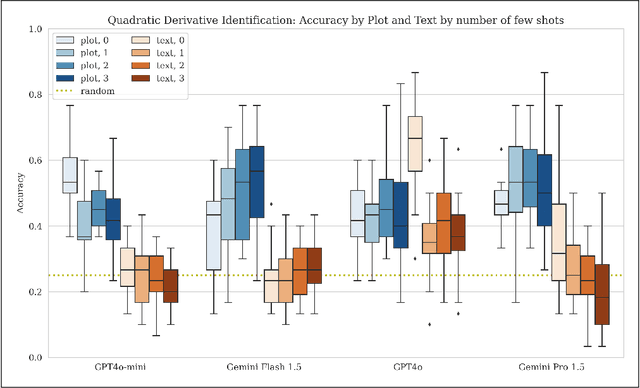
While multimodal foundation models can now natively work with data beyond text, they remain underutilized in analyzing the considerable amounts of multi-dimensional time-series data in fields like healthcare, finance, and social sciences, representing a missed opportunity for richer, data-driven insights. This paper proposes a simple but effective method that leverages the existing vision encoders of these models to "see" time-series data via plots, avoiding the need for additional, potentially costly, model training. Our empirical evaluations show that this approach outperforms providing the raw time-series data as text, with the additional benefit that visual time-series representations demonstrate up to a 90% reduction in model API costs. We validate our hypothesis through synthetic data tasks of increasing complexity, progressing from simple functional form identification on clean data, to extracting trends from noisy scatter plots. To demonstrate generalizability from synthetic tasks with clear reasoning steps to more complex, real-world scenarios, we apply our approach to consumer health tasks - specifically fall detection, activity recognition, and readiness assessment - which involve heterogeneous, noisy data and multi-step reasoning. The overall success in plot performance over text performance (up to an 120% performance increase on zero-shot synthetic tasks, and up to 150% performance increase on real-world tasks), across both GPT and Gemini model families, highlights our approach's potential for making the best use of the native capabilities of foundation models.
Towards a Personal Health Large Language Model
Jun 10, 2024



In health, most large language model (LLM) research has focused on clinical tasks. However, mobile and wearable devices, which are rarely integrated into such tasks, provide rich, longitudinal data for personal health monitoring. Here we present Personal Health Large Language Model (PH-LLM), fine-tuned from Gemini for understanding and reasoning over numerical time-series personal health data. We created and curated three datasets that test 1) production of personalized insights and recommendations from sleep patterns, physical activity, and physiological responses, 2) expert domain knowledge, and 3) prediction of self-reported sleep outcomes. For the first task we designed 857 case studies in collaboration with domain experts to assess real-world scenarios in sleep and fitness. Through comprehensive evaluation of domain-specific rubrics, we observed that Gemini Ultra 1.0 and PH-LLM are not statistically different from expert performance in fitness and, while experts remain superior for sleep, fine-tuning PH-LLM provided significant improvements in using relevant domain knowledge and personalizing information for sleep insights. We evaluated PH-LLM domain knowledge using multiple choice sleep medicine and fitness examinations. PH-LLM achieved 79% on sleep and 88% on fitness, exceeding average scores from a sample of human experts. Finally, we trained PH-LLM to predict self-reported sleep quality outcomes from textual and multimodal encoding representations of wearable data, and demonstrate that multimodal encoding is required to match performance of specialized discriminative models. Although further development and evaluation are necessary in the safety-critical personal health domain, these results demonstrate both the broad knowledge and capabilities of Gemini models and the benefit of contextualizing physiological data for personal health applications as done with PH-LLM.
Advancing Multimodal Medical Capabilities of Gemini
May 06, 2024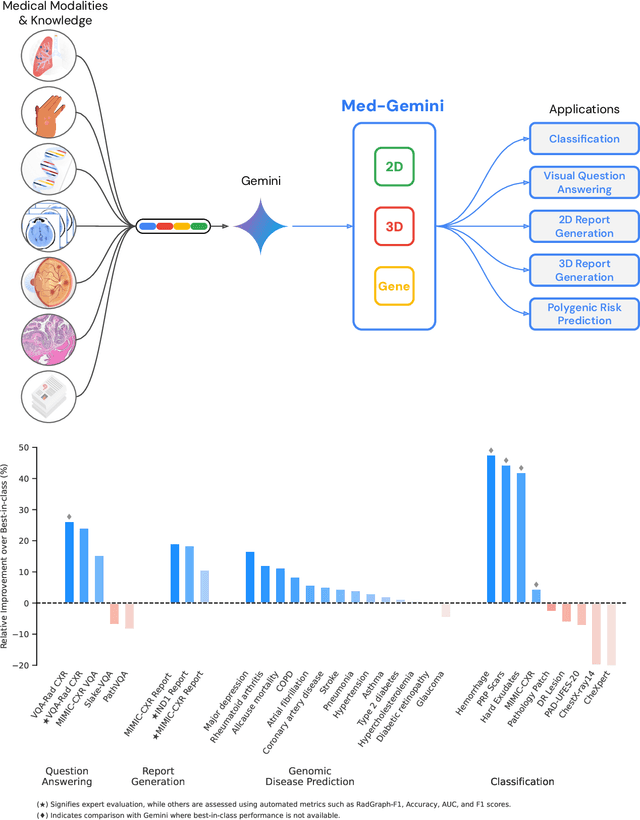
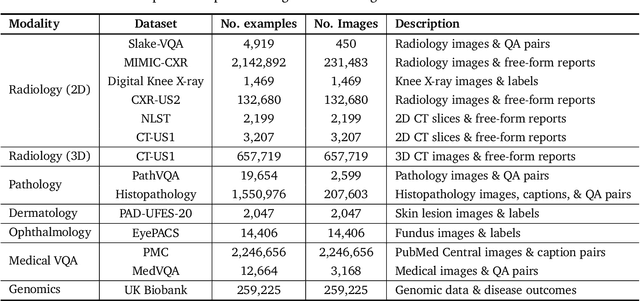

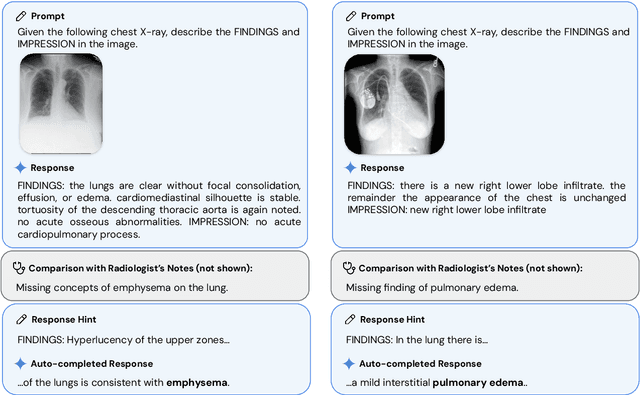
Many clinical tasks require an understanding of specialized data, such as medical images and genomics, which is not typically found in general-purpose large multimodal models. Building upon Gemini's multimodal models, we develop several models within the new Med-Gemini family that inherit core capabilities of Gemini and are optimized for medical use via fine-tuning with 2D and 3D radiology, histopathology, ophthalmology, dermatology and genomic data. Med-Gemini-2D sets a new standard for AI-based chest X-ray (CXR) report generation based on expert evaluation, exceeding previous best results across two separate datasets by an absolute margin of 1% and 12%, where 57% and 96% of AI reports on normal cases, and 43% and 65% on abnormal cases, are evaluated as "equivalent or better" than the original radiologists' reports. We demonstrate the first ever large multimodal model-based report generation for 3D computed tomography (CT) volumes using Med-Gemini-3D, with 53% of AI reports considered clinically acceptable, although additional research is needed to meet expert radiologist reporting quality. Beyond report generation, Med-Gemini-2D surpasses the previous best performance in CXR visual question answering (VQA) and performs well in CXR classification and radiology VQA, exceeding SoTA or baselines on 17 of 20 tasks. In histopathology, ophthalmology, and dermatology image classification, Med-Gemini-2D surpasses baselines across 18 out of 20 tasks and approaches task-specific model performance. Beyond imaging, Med-Gemini-Polygenic outperforms the standard linear polygenic risk score-based approach for disease risk prediction and generalizes to genetically correlated diseases for which it has never been trained. Although further development and evaluation are necessary in the safety-critical medical domain, our results highlight the potential of Med-Gemini across a wide range of medical tasks.
HeAR -- Health Acoustic Representations
Mar 04, 2024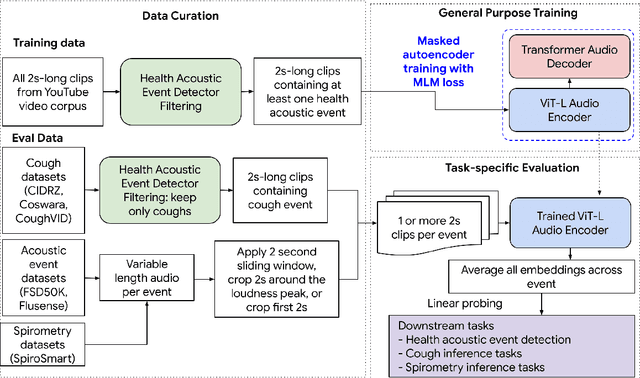

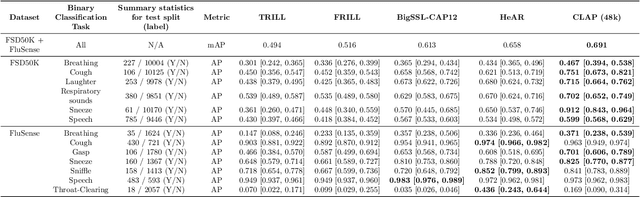
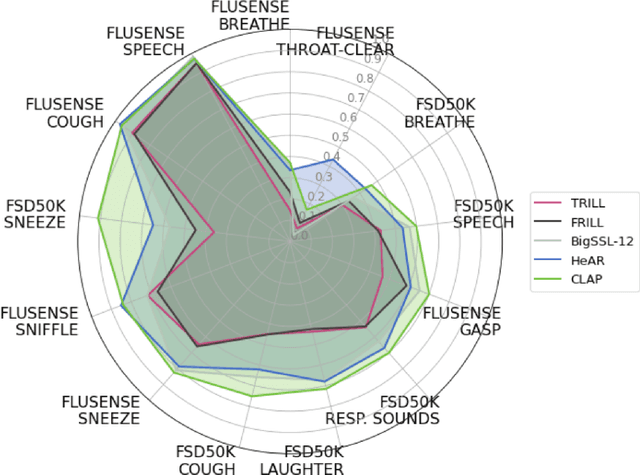
Health acoustic sounds such as coughs and breaths are known to contain useful health signals with significant potential for monitoring health and disease, yet are underexplored in the medical machine learning community. The existing deep learning systems for health acoustics are often narrowly trained and evaluated on a single task, which is limited by data and may hinder generalization to other tasks. To mitigate these gaps, we develop HeAR, a scalable self-supervised learning-based deep learning system using masked autoencoders trained on a large dataset of 313 million two-second long audio clips. Through linear probes, we establish HeAR as a state-of-the-art health audio embedding model on a benchmark of 33 health acoustic tasks across 6 datasets. By introducing this work, we hope to enable and accelerate further health acoustics research.
Optimizing Audio Augmentations for Contrastive Learning of Health-Related Acoustic Signals
Sep 11, 2023

Health-related acoustic signals, such as cough and breathing sounds, are relevant for medical diagnosis and continuous health monitoring. Most existing machine learning approaches for health acoustics are trained and evaluated on specific tasks, limiting their generalizability across various healthcare applications. In this paper, we leverage a self-supervised learning framework, SimCLR with a Slowfast NFNet backbone, for contrastive learning of health acoustics. A crucial aspect of optimizing Slowfast NFNet for this application lies in identifying effective audio augmentations. We conduct an in-depth analysis of various audio augmentation strategies and demonstrate that an appropriate augmentation strategy enhances the performance of the Slowfast NFNet audio encoder across a diverse set of health acoustic tasks. Our findings reveal that when augmentations are combined, they can produce synergistic effects that exceed the benefits seen when each is applied individually.
ELIXR: Towards a general purpose X-ray artificial intelligence system through alignment of large language models and radiology vision encoders
Aug 02, 2023Our approach, which we call Embeddings for Language/Image-aligned X-Rays, or ELIXR, leverages a language-aligned image encoder combined or grafted onto a fixed LLM, PaLM 2, to perform a broad range of tasks. We train this lightweight adapter architecture using images paired with corresponding free-text radiology reports from the MIMIC-CXR dataset. ELIXR achieved state-of-the-art performance on zero-shot chest X-ray (CXR) classification (mean AUC of 0.850 across 13 findings), data-efficient CXR classification (mean AUCs of 0.893 and 0.898 across five findings (atelectasis, cardiomegaly, consolidation, pleural effusion, and pulmonary edema) for 1% (~2,200 images) and 10% (~22,000 images) training data), and semantic search (0.76 normalized discounted cumulative gain (NDCG) across nineteen queries, including perfect retrieval on twelve of them). Compared to existing data-efficient methods including supervised contrastive learning (SupCon), ELIXR required two orders of magnitude less data to reach similar performance. ELIXR also showed promise on CXR vision-language tasks, demonstrating overall accuracies of 58.7% and 62.5% on visual question answering and report quality assurance tasks, respectively. These results suggest that ELIXR is a robust and versatile approach to CXR AI.
Predicting Cardiovascular Disease Risk using Photoplethysmography and Deep Learning
May 09, 2023Cardiovascular diseases (CVDs) are responsible for a large proportion of premature deaths in low- and middle-income countries. Early CVD detection and intervention is critical in these populations, yet many existing CVD risk scores require a physical examination or lab measurements, which can be challenging in such health systems due to limited accessibility. Here we investigated the potential to use photoplethysmography (PPG), a sensing technology available on most smartphones that can potentially enable large-scale screening at low cost, for CVD risk prediction. We developed a deep learning PPG-based CVD risk score (DLS) to predict the probability of having major adverse cardiovascular events (MACE: non-fatal myocardial infarction, stroke, and cardiovascular death) within ten years, given only age, sex, smoking status and PPG as predictors. We compared the DLS with the office-based refit-WHO score, which adopts the shared predictors from WHO and Globorisk scores (age, sex, smoking status, height, weight and systolic blood pressure) but refitted on the UK Biobank (UKB) cohort. In UKB cohort, DLS's C-statistic (71.1%, 95% CI 69.9-72.4) was non-inferior to office-based refit-WHO score (70.9%, 95% CI 69.7-72.2; non-inferiority margin of 2.5%, p<0.01). The calibration of the DLS was satisfactory, with a 1.8% mean absolute calibration error. Adding DLS features to the office-based score increased the C-statistic by 1.0% (95% CI 0.6-1.4). DLS predicts ten-year MACE risk comparable with the office-based refit-WHO score. It provides a proof-of-concept and suggests the potential of a PPG-based approach strategies for community-based primary prevention in resource-limited regions.
Learning to Detect Touches on Cluttered Tables
Apr 10, 2023
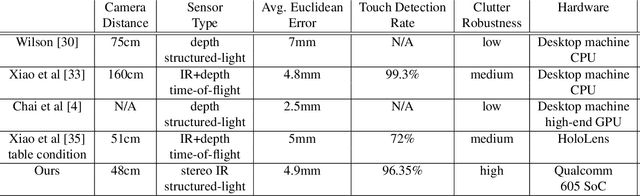

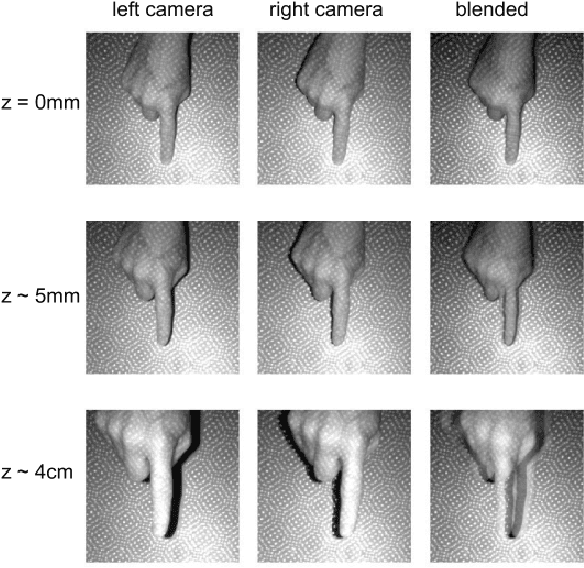
We present a novel self-contained camera-projector tabletop system with a lamp form-factor that brings digital intelligence to our tables. We propose a real-time, on-device, learning-based touch detection algorithm that makes any tabletop interactive. The top-down configuration and learning-based algorithm makes our method robust to the presence of clutter, a main limitation of existing camera-projector tabletop systems. Our research prototype enables a set of experiences that combine hand interactions and objects present on the table. A video can be found at https://youtu.be/hElC_c25Fg8.
Deep learning for detecting pulmonary tuberculosis via chest radiography: an international study across 10 countries
May 16, 2021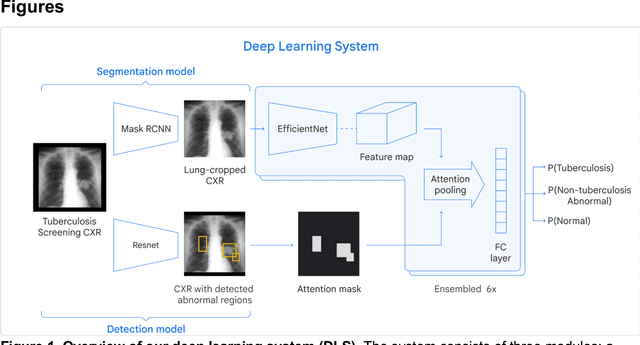
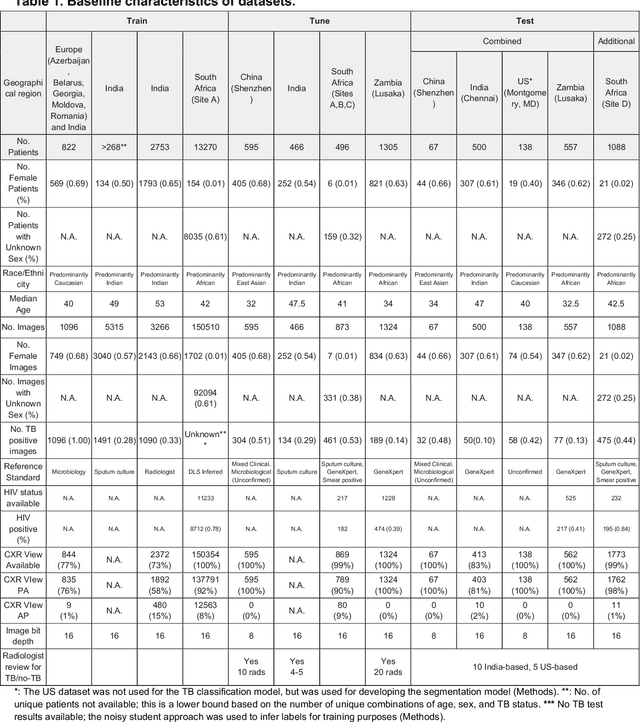
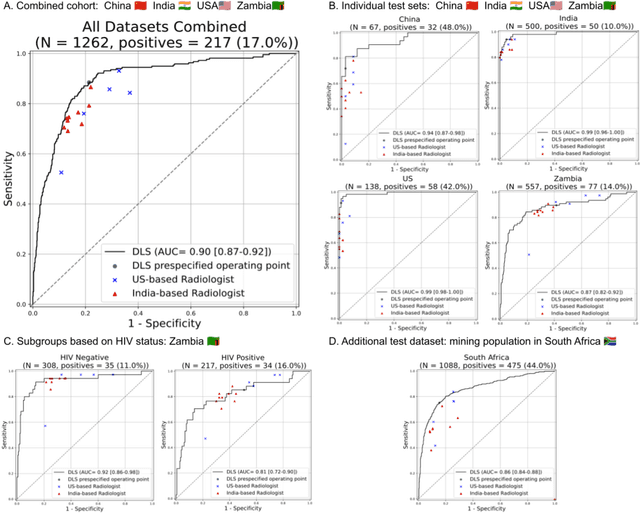
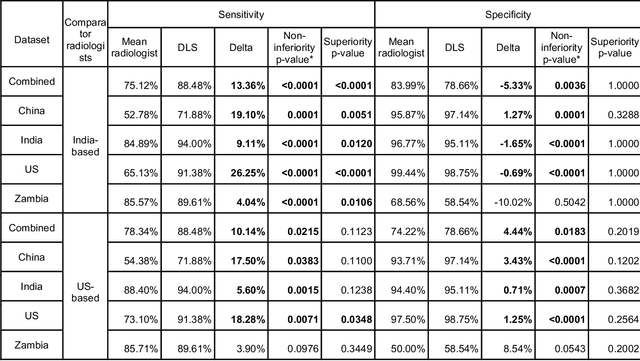
Tuberculosis (TB) is a top-10 cause of death worldwide. Though the WHO recommends chest radiographs (CXRs) for TB screening, the limited availability of CXR interpretation is a barrier. We trained a deep learning system (DLS) to detect active pulmonary TB using CXRs from 9 countries across Africa, Asia, and Europe, and utilized large-scale CXR pretraining, attention pooling, and noisy student semi-supervised learning. Evaluation was on (1) a combined test set spanning China, India, US, and Zambia, and (2) an independent mining population in South Africa. Given WHO targets of 90% sensitivity and 70% specificity, the DLS's operating point was prespecified to favor sensitivity over specificity. On the combined test set, the DLS's ROC curve was above all 9 India-based radiologists, with an AUC of 0.90 (95%CI 0.87-0.92). The DLS's sensitivity (88%) was higher than the India-based radiologists (75% mean sensitivity), p<0.001 for superiority; and its specificity (79%) was non-inferior to the radiologists (84% mean specificity), p=0.004. Similar trends were observed within HIV positive and sputum smear positive sub-groups, and in the South Africa test set. We found that 5 US-based radiologists (where TB isn't endemic) were more sensitive and less specific than the India-based radiologists (where TB is endemic). The DLS also remained non-inferior to the US-based radiologists. In simulations, using the DLS as a prioritization tool for confirmatory testing reduced the cost per positive case detected by 40-80% compared to using confirmatory testing alone. To conclude, our DLS generalized to 5 countries, and merits prospective evaluation to assist cost-effective screening efforts in radiologist-limited settings. Operating point flexibility may permit customization of the DLS to account for site-specific factors such as TB prevalence, demographics, clinical resources, and customary practice patterns.