 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlots Unlock Time-Series Understanding in Multimodal Models
Oct 03, 2024

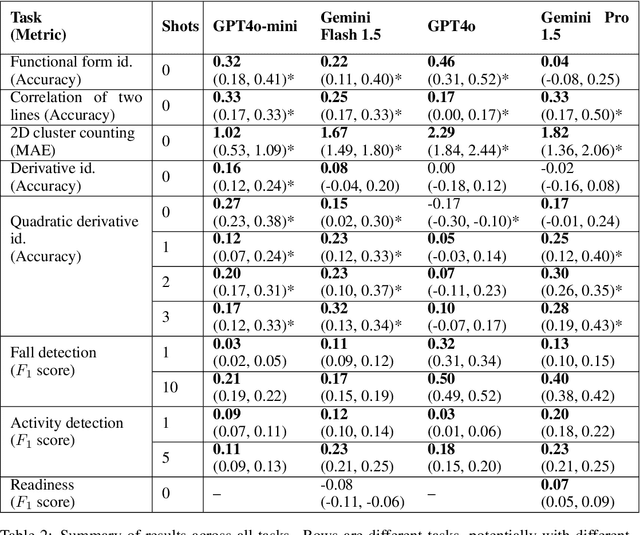
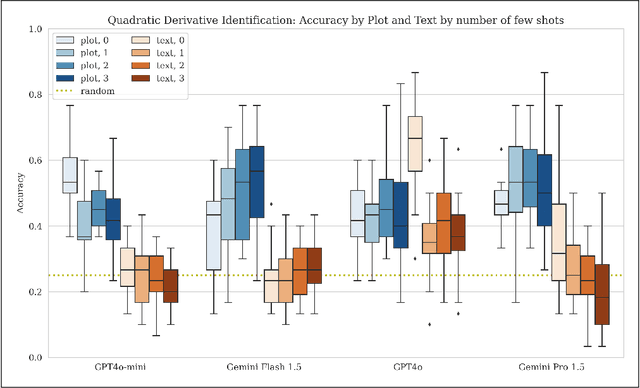
While multimodal foundation models can now natively work with data beyond text, they remain underutilized in analyzing the considerable amounts of multi-dimensional time-series data in fields like healthcare, finance, and social sciences, representing a missed opportunity for richer, data-driven insights. This paper proposes a simple but effective method that leverages the existing vision encoders of these models to "see" time-series data via plots, avoiding the need for additional, potentially costly, model training. Our empirical evaluations show that this approach outperforms providing the raw time-series data as text, with the additional benefit that visual time-series representations demonstrate up to a 90% reduction in model API costs. We validate our hypothesis through synthetic data tasks of increasing complexity, progressing from simple functional form identification on clean data, to extracting trends from noisy scatter plots. To demonstrate generalizability from synthetic tasks with clear reasoning steps to more complex, real-world scenarios, we apply our approach to consumer health tasks - specifically fall detection, activity recognition, and readiness assessment - which involve heterogeneous, noisy data and multi-step reasoning. The overall success in plot performance over text performance (up to an 120% performance increase on zero-shot synthetic tasks, and up to 150% performance increase on real-world tasks), across both GPT and Gemini model families, highlights our approach's potential for making the best use of the native capabilities of foundation models.
Predicting Cardiovascular Disease Risk using Photoplethysmography and Deep Learning
May 09, 2023Cardiovascular diseases (CVDs) are responsible for a large proportion of premature deaths in low- and middle-income countries. Early CVD detection and intervention is critical in these populations, yet many existing CVD risk scores require a physical examination or lab measurements, which can be challenging in such health systems due to limited accessibility. Here we investigated the potential to use photoplethysmography (PPG), a sensing technology available on most smartphones that can potentially enable large-scale screening at low cost, for CVD risk prediction. We developed a deep learning PPG-based CVD risk score (DLS) to predict the probability of having major adverse cardiovascular events (MACE: non-fatal myocardial infarction, stroke, and cardiovascular death) within ten years, given only age, sex, smoking status and PPG as predictors. We compared the DLS with the office-based refit-WHO score, which adopts the shared predictors from WHO and Globorisk scores (age, sex, smoking status, height, weight and systolic blood pressure) but refitted on the UK Biobank (UKB) cohort. In UKB cohort, DLS's C-statistic (71.1%, 95% CI 69.9-72.4) was non-inferior to office-based refit-WHO score (70.9%, 95% CI 69.7-72.2; non-inferiority margin of 2.5%, p<0.01). The calibration of the DLS was satisfactory, with a 1.8% mean absolute calibration error. Adding DLS features to the office-based score increased the C-statistic by 1.0% (95% CI 0.6-1.4). DLS predicts ten-year MACE risk comparable with the office-based refit-WHO score. It provides a proof-of-concept and suggests the potential of a PPG-based approach strategies for community-based primary prevention in resource-limited regions.
Self-Modification of Policy and Utility Function in Rational Agents
May 10, 2016


Any agent that is part of the environment it interacts with and has versatile actuators (such as arms and fingers), will in principle have the ability to self-modify -- for example by changing its own source code. As we continue to create more and more intelligent agents, chances increase that they will learn about this ability. The question is: will they want to use it? For example, highly intelligent systems may find ways to change their goals to something more easily achievable, thereby `escaping' the control of their designers. In an important paper, Omohundro (2008) argued that goal preservation is a fundamental drive of any intelligent system, since a goal is more likely to be achieved if future versions of the agent strive towards the same goal. In this paper, we formalise this argument in general reinforcement learning, and explore situations where it fails. Our conclusion is that the self-modification possibility is harmless if and only if the value function of the agent anticipates the consequences of self-modifications and use the current utility function when evaluating the future.
A Definition of Happiness for Reinforcement Learning Agents
May 18, 2015
What is happiness for reinforcement learning agents? We seek a formal definition satisfying a list of desiderata. Our proposed definition of happiness is the temporal difference error, i.e. the difference between the value of the obtained reward and observation and the agent's expectation of this value. This definition satisfies most of our desiderata and is compatible with empirical research on humans. We state several implications and discuss examples.