 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Multimodal Medical Capabilities of Gemini
May 06, 2024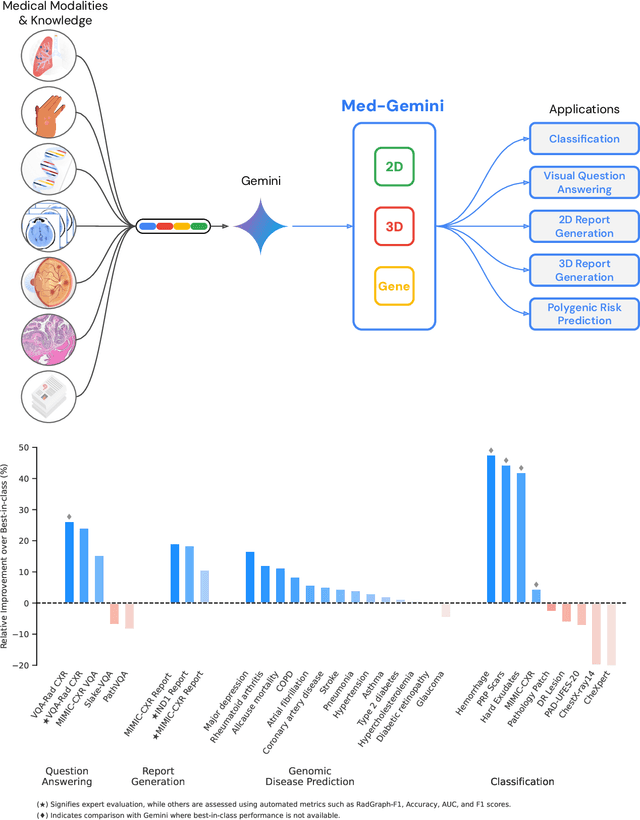

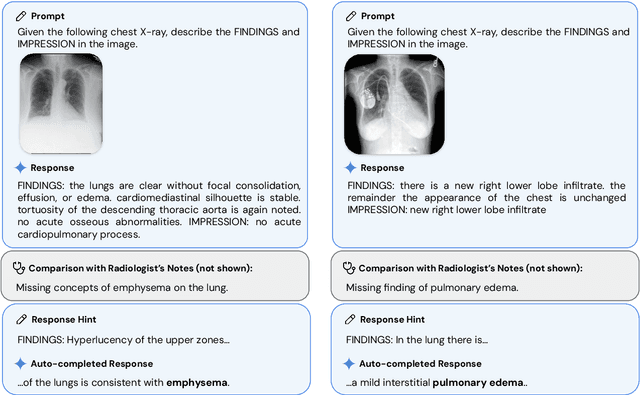
Many clinical tasks require an understanding of specialized data, such as medical images and genomics, which is not typically found in general-purpose large multimodal models. Building upon Gemini's multimodal models, we develop several models within the new Med-Gemini family that inherit core capabilities of Gemini and are optimized for medical use via fine-tuning with 2D and 3D radiology, histopathology, ophthalmology, dermatology and genomic data. Med-Gemini-2D sets a new standard for AI-based chest X-ray (CXR) report generation based on expert evaluation, exceeding previous best results across two separate datasets by an absolute margin of 1% and 12%, where 57% and 96% of AI reports on normal cases, and 43% and 65% on abnormal cases, are evaluated as "equivalent or better" than the original radiologists' reports. We demonstrate the first ever large multimodal model-based report generation for 3D computed tomography (CT) volumes using Med-Gemini-3D, with 53% of AI reports considered clinically acceptable, although additional research is needed to meet expert radiologist reporting quality. Beyond report generation, Med-Gemini-2D surpasses the previous best performance in CXR visual question answering (VQA) and performs well in CXR classification and radiology VQA, exceeding SoTA or baselines on 17 of 20 tasks. In histopathology, ophthalmology, and dermatology image classification, Med-Gemini-2D surpasses baselines across 18 out of 20 tasks and approaches task-specific model performance. Beyond imaging, Med-Gemini-Polygenic outperforms the standard linear polygenic risk score-based approach for disease risk prediction and generalizes to genetically correlated diseases for which it has never been trained. Although further development and evaluation are necessary in the safety-critical medical domain, our results highlight the potential of Med-Gemini across a wide range of medical tasks.
An Evaluation of Real-time Adaptive Sampling Change Point Detection Algorithm using KCUSUM
Feb 15, 2024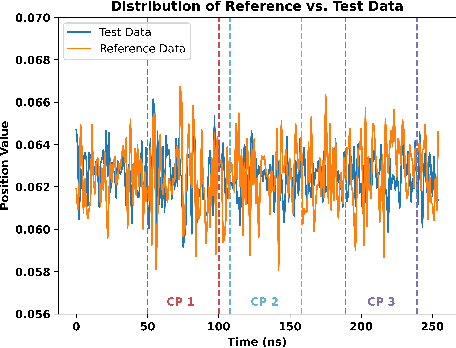

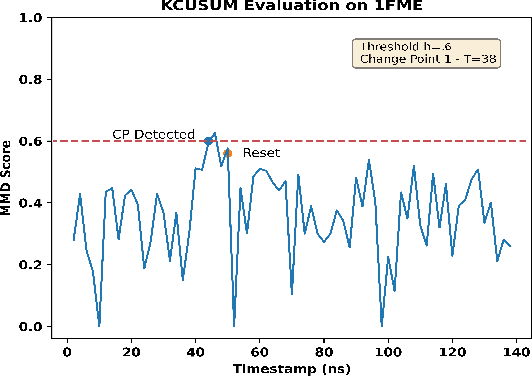
Detecting abrupt changes in real-time data streams from scientific simulations presents a challenging task, demanding the deployment of accurate and efficient algorithms. Identifying change points in live data stream involves continuous scrutiny of incoming observations for deviations in their statistical characteristics, particularly in high-volume data scenarios. Maintaining a balance between sudden change detection and minimizing false alarms is vital. Many existing algorithms for this purpose rely on known probability distributions, limiting their feasibility. In this study, we introduce the Kernel-based Cumulative Sum (KCUSUM) algorithm, a non-parametric extension of the traditional Cumulative Sum (CUSUM) method, which has gained prominence for its efficacy in online change point detection under less restrictive conditions. KCUSUM splits itself by comparing incoming samples directly with reference samples and computes a statistic grounded in the Maximum Mean Discrepancy (MMD) non-parametric framework. This approach extends KCUSUM's pertinence to scenarios where only reference samples are available, such as atomic trajectories of proteins in vacuum, facilitating the detection of deviations from the reference sample without prior knowledge of the data's underlying distribution. Furthermore, by harnessing MMD's inherent random-walk structure, we can theoretically analyze KCUSUM's performance across various use cases, including metrics like expected delay and mean runtime to false alarms. Finally, we discuss real-world use cases from scientific simulations such as NWChem CODAR and protein folding data, demonstrating KCUSUM's practical effectiveness in online change point detection.
ELIXR: Towards a general purpose X-ray artificial intelligence system through alignment of large language models and radiology vision encoders
Aug 02, 2023Our approach, which we call Embeddings for Language/Image-aligned X-Rays, or ELIXR, leverages a language-aligned image encoder combined or grafted onto a fixed LLM, PaLM 2, to perform a broad range of tasks. We train this lightweight adapter architecture using images paired with corresponding free-text radiology reports from the MIMIC-CXR dataset. ELIXR achieved state-of-the-art performance on zero-shot chest X-ray (CXR) classification (mean AUC of 0.850 across 13 findings), data-efficient CXR classification (mean AUCs of 0.893 and 0.898 across five findings (atelectasis, cardiomegaly, consolidation, pleural effusion, and pulmonary edema) for 1% (~2,200 images) and 10% (~22,000 images) training data), and semantic search (0.76 normalized discounted cumulative gain (NDCG) across nineteen queries, including perfect retrieval on twelve of them). Compared to existing data-efficient methods including supervised contrastive learning (SupCon), ELIXR required two orders of magnitude less data to reach similar performance. ELIXR also showed promise on CXR vision-language tasks, demonstrating overall accuracies of 58.7% and 62.5% on visual question answering and report quality assurance tasks, respectively. These results suggest that ELIXR is a robust and versatile approach to CXR AI.
Accelerating HPC codes on Intel Omni-Path Architecture networks: From particle physics to Machine Learning
Nov 13, 2017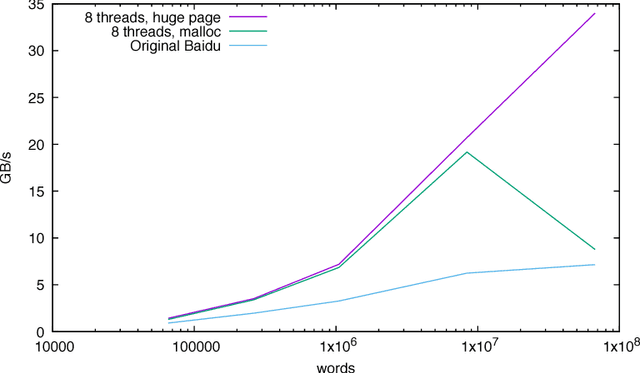
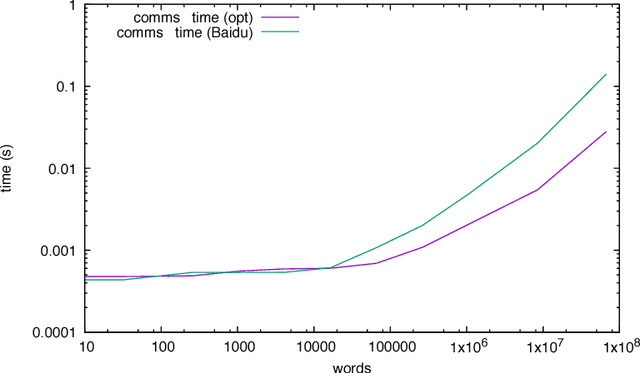
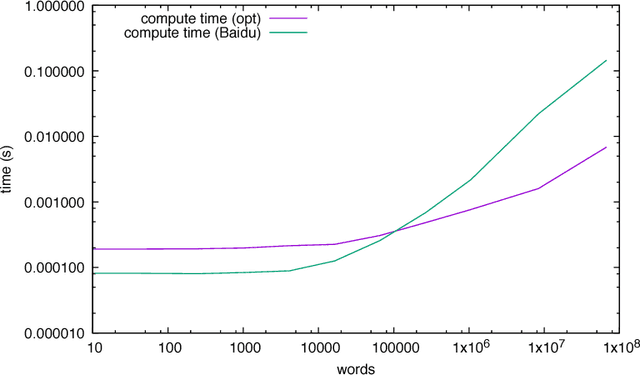
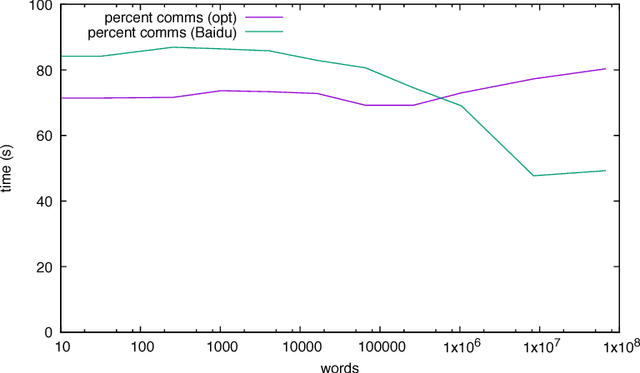
We discuss practical methods to ensure near wirespeed performance from clusters with either one or two Intel(R) Omni-Path host fabric interfaces (HFI) per node, and Intel(R) Xeon Phi(TM) 72xx (Knight's Landing) processors, and using the Linux operating system. The study evaluates the performance improvements achievable and the required programming approaches in two distinct example problems: firstly in Cartesian communicator halo exchange problems, appropriate for structured grid PDE solvers that arise in quantum chromodynamics simulations of particle physics, and secondly in gradient reduction appropriate to synchronous stochastic gradient descent for machine learning. As an example, we accelerate a published Baidu Research reduction code and obtain a factor of ten speedup over the original code using the techniques discussed in this paper. This displays how a factor of ten speedup in strongly scaled distributed machine learning could be achieved when synchronous stochastic gradient descent is massively parallelised with a fixed mini-batch size. We find a significant improvement in performance robustness when memory is obtained using carefully allocated 2MB "huge" virtual memory pages, implying that either non-standard allocation routines should be used for communication buffers. These can be accessed via a LD\_PRELOAD override in the manner suggested by libhugetlbfs. We make use of a the Intel(R) MPI 2019 library "Technology Preview" and underlying software to enable thread concurrency throughout the communication software stake via multiple PSM2 endpoints per process and use of multiple independent MPI communicators. When using a single MPI process per node, we find that this greatly accelerates delivered bandwidth in many core Intel(R) Xeon Phi processors.