 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEtalumis: Bringing Probabilistic Programming to Scientific Simulators at Scale
Jul 08, 2019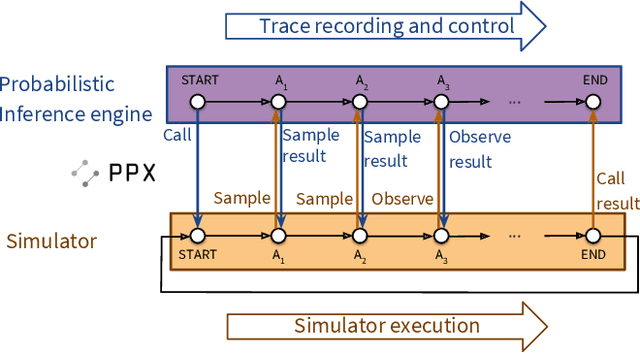

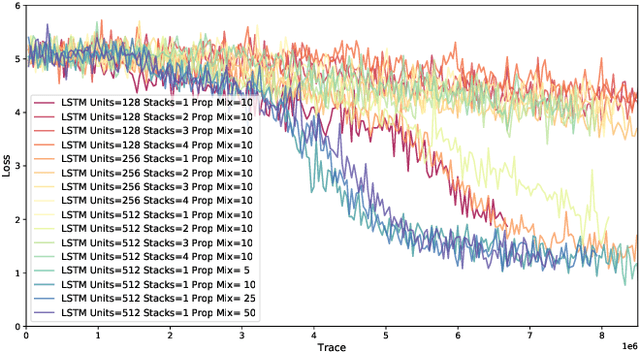
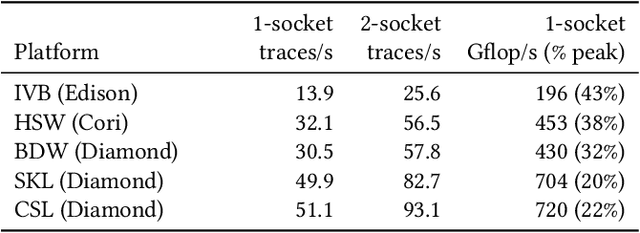
Probabilistic programming languages (PPLs) are receiving widespread attention for performing Bayesian inference in complex generative models. However, applications to science remain limited because of the impracticability of rewriting complex scientific simulators in a PPL, the computational cost of inference, and the lack of scalable implementations. To address these, we present a novel PPL framework that couples directly to existing scientific simulators through a cross-platform probabilistic execution protocol and provides Markov chain Monte Carlo (MCMC) and deep-learning-based inference compilation (IC) engines for tractable inference. To guide IC inference, we perform distributed training of a dynamic 3DCNN--LSTM architecture with a PyTorch-MPI-based framework on 1,024 32-core CPU nodes of the Cori supercomputer with a global minibatch size of 128k: achieving a performance of 450 Tflop/s through enhancements to PyTorch. We demonstrate a Large Hadron Collider (LHC) use-case with the C++ Sherpa simulator and achieve the largest-scale posterior inference in a Turing-complete PPL.
CosmoFlow: Using Deep Learning to Learn the Universe at Scale
Aug 14, 2018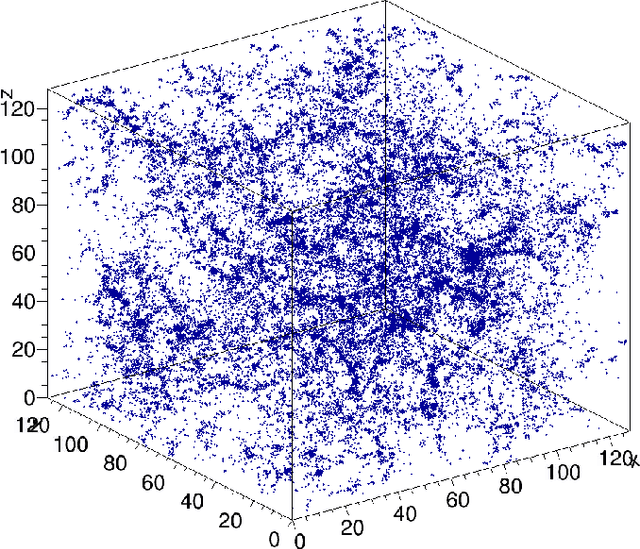
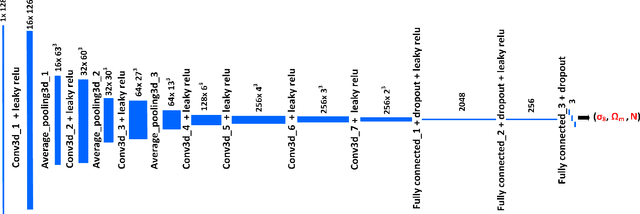
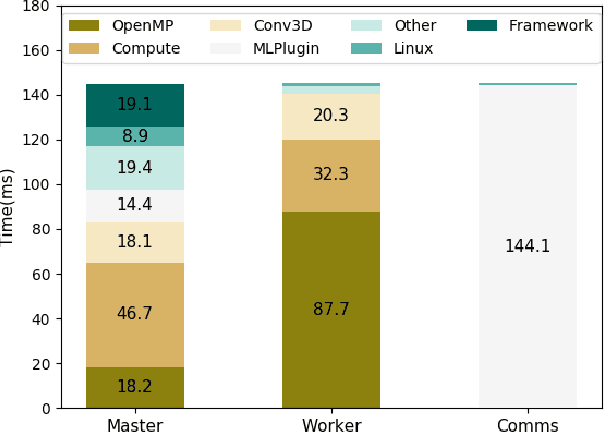
Deep learning is a promising tool to determine the physical model that describes our universe. To handle the considerable computational cost of this problem, we present CosmoFlow: a highly scalable deep learning application built on top of the TensorFlow framework. CosmoFlow uses efficient implementations of 3D convolution and pooling primitives, together with improvements in threading for many element-wise operations, to improve training performance on Intel(C) Xeon Phi(TM) processors. We also utilize the Cray PE Machine Learning Plugin for efficient scaling to multiple nodes. We demonstrate fully synchronous data-parallel training on 8192 nodes of Cori with 77% parallel efficiency, achieving 3.5 Pflop/s sustained performance. To our knowledge, this is the first large-scale science application of the TensorFlow framework at supercomputer scale with fully-synchronous training. These enhancements enable us to process large 3D dark matter distribution and predict the cosmological parameters $\Omega_M$, $\sigma_8$ and n$_s$ with unprecedented accuracy.
Accelerating HPC codes on Intel Omni-Path Architecture networks: From particle physics to Machine Learning
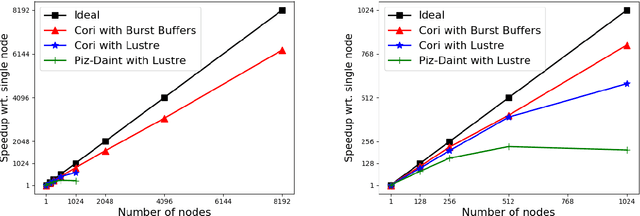
Nov 13, 2017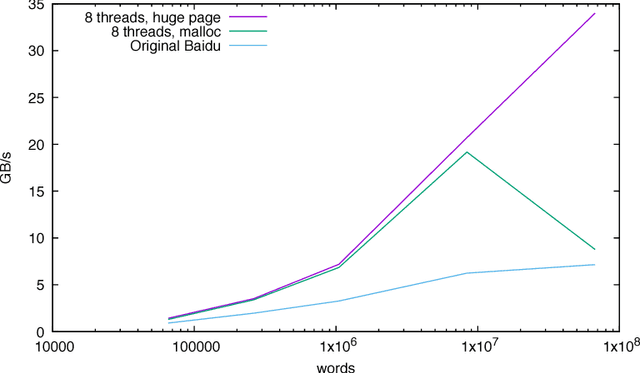
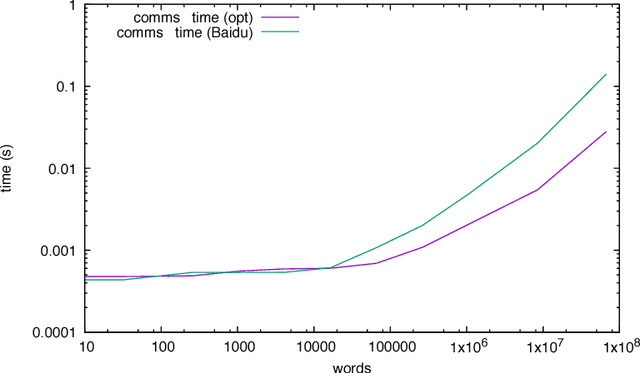
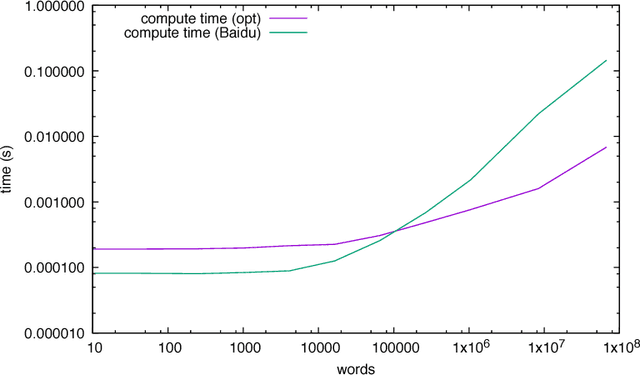
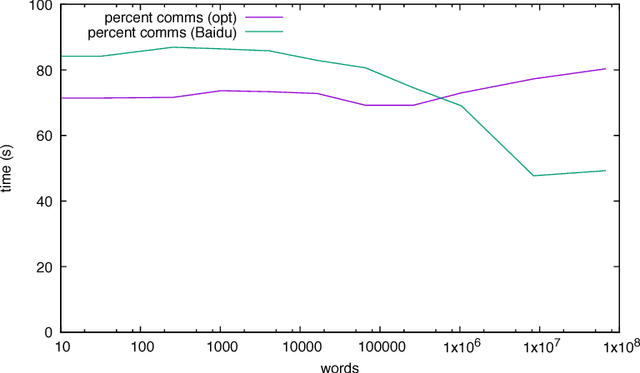
We discuss practical methods to ensure near wirespeed performance from clusters with either one or two Intel(R) Omni-Path host fabric interfaces (HFI) per node, and Intel(R) Xeon Phi(TM) 72xx (Knight's Landing) processors, and using the Linux operating system. The study evaluates the performance improvements achievable and the required programming approaches in two distinct example problems: firstly in Cartesian communicator halo exchange problems, appropriate for structured grid PDE solvers that arise in quantum chromodynamics simulations of particle physics, and secondly in gradient reduction appropriate to synchronous stochastic gradient descent for machine learning. As an example, we accelerate a published Baidu Research reduction code and obtain a factor of ten speedup over the original code using the techniques discussed in this paper. This displays how a factor of ten speedup in strongly scaled distributed machine learning could be achieved when synchronous stochastic gradient descent is massively parallelised with a fixed mini-batch size. We find a significant improvement in performance robustness when memory is obtained using carefully allocated 2MB "huge" virtual memory pages, implying that either non-standard allocation routines should be used for communication buffers. These can be accessed via a LD\_PRELOAD override in the manner suggested by libhugetlbfs. We make use of a the Intel(R) MPI 2019 library "Technology Preview" and underlying software to enable thread concurrency throughout the communication software stake via multiple PSM2 endpoints per process and use of multiple independent MPI communicators. When using a single MPI process per node, we find that this greatly accelerates delivered bandwidth in many core Intel(R) Xeon Phi processors.