 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetinal vessel segmentation by probing adaptive to lighting variations
Apr 29, 2020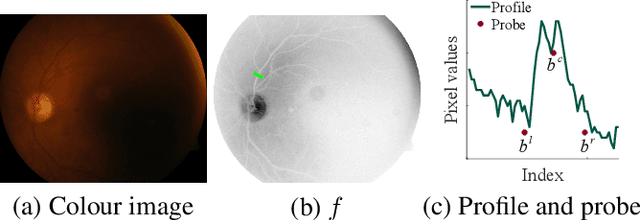
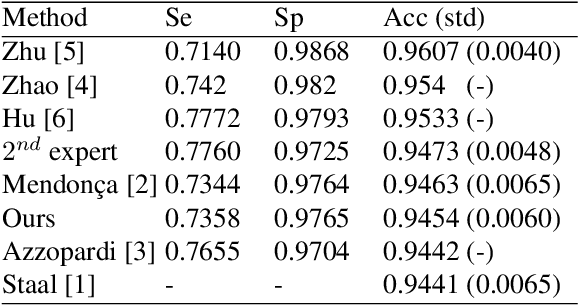
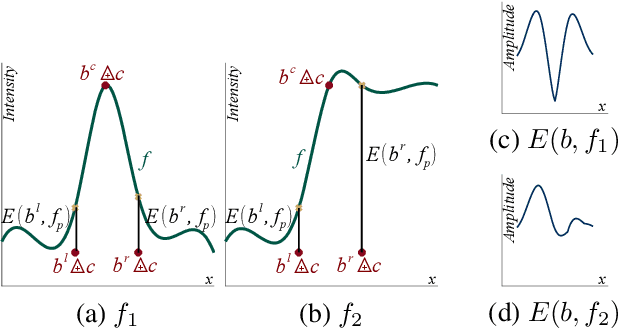
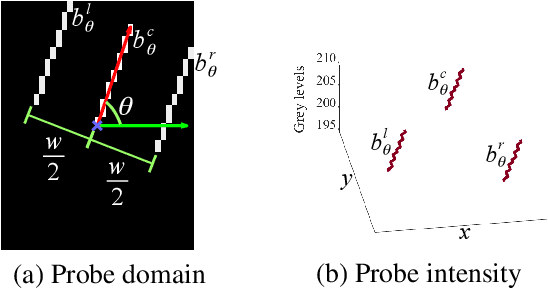
We introduce a novel method to extract the vessels in eye fun-dus images which is adaptive to lighting variations. In the Logarithmic Image Processing framework, a 3-segment probe detects the vessels by probing the topographic surface of an image from below. A map of contrasts between the probe and the image allows to detect the vessels by a threshold. In a lowly contrasted image, results show that our method better extract the vessels than another state-of the-art method. In a highly contrasted image database (DRIVE) with a reference , ours has an accuracy of 0.9454 which is similar or better than three state-of-the-art methods and below three others. The three best methods have a higher accuracy than a manual segmentation by another expert. Importantly, our method automatically adapts to the lighting conditions of the image acquisition.
* Proceedings of 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI).To appear in https://ieeexplore.ieee.org
Superimposition of eye fundus images for longitudinal analysis from large public health databases
Jul 18, 2018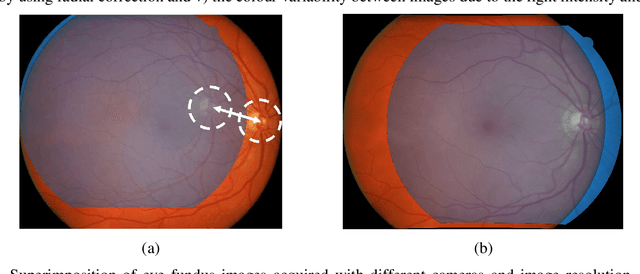
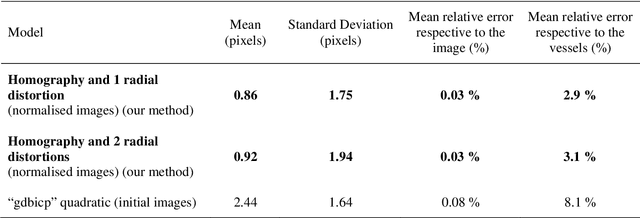
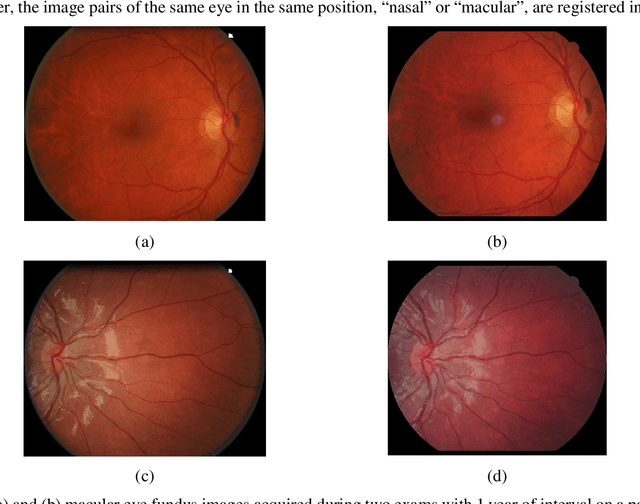
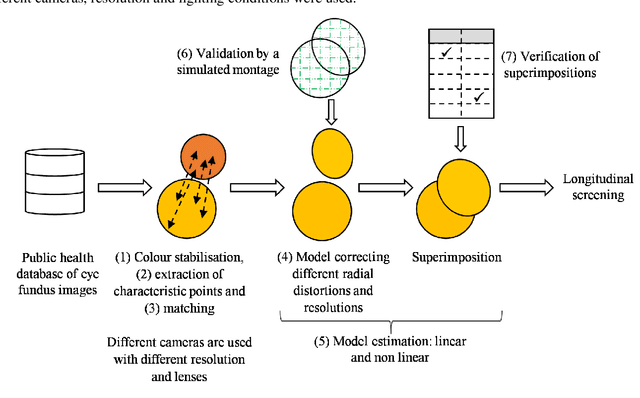
In this paper, a method is presented for superimposition (i.e. registration) of eye fundus images from persons with diabetes screened over many years for diabetic retinopathy. The method is fully automatic and robust to camera changes and colour variations across the images both in space and time. All the stages of the process are designed for longitudinal analysis of cohort public health databases where retinal examinations are made at approximately yearly intervals. The method relies on a model correcting two radial distortions and an affine transformation between pairs of images which is robustly fitted on salient points. Each stage involves linear estimators followed by non-linear optimisation. The model of image warping is also invertible for fast computation. The method has been validated (1) on a simulated montage and (2) on public health databases with 69 patients with high quality images (271 pairs acquired mostly with different types of camera and 268 pairs acquired mostly with the same type of camera) with success rates of 92% and 98%, and five patients (20 pairs) with low quality images with a success rate of 100%. Compared to two state-of-the-art methods, ours gives better results.
* This is an author-created, un-copyedited version of an article published in Biomedical Physics \& Engineering Express. IOP Publishing Ltd is not responsible for any errors or omissions in this version of the manuscript or any version derived from it. The Version of Record is available online at https://doi.org/10.1088/2057-1976/aa7d16
Accelerating HPC codes on Intel Omni-Path Architecture networks: From particle physics to Machine Learning
Nov 13, 2017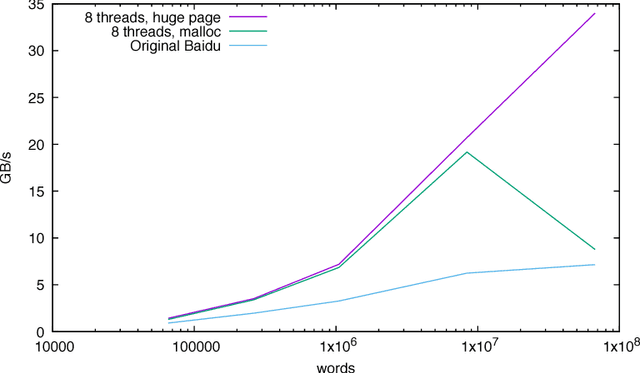
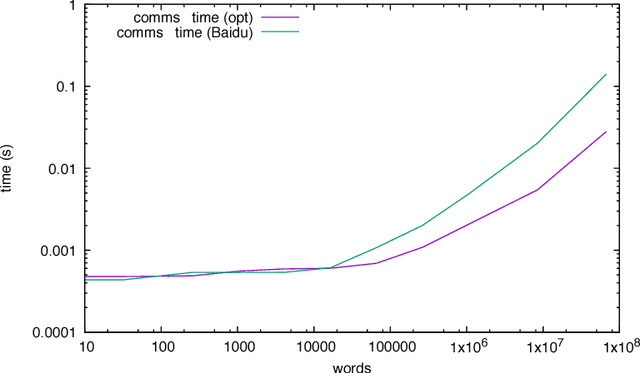
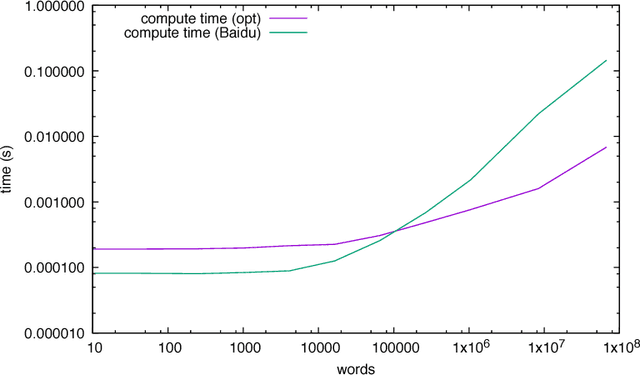
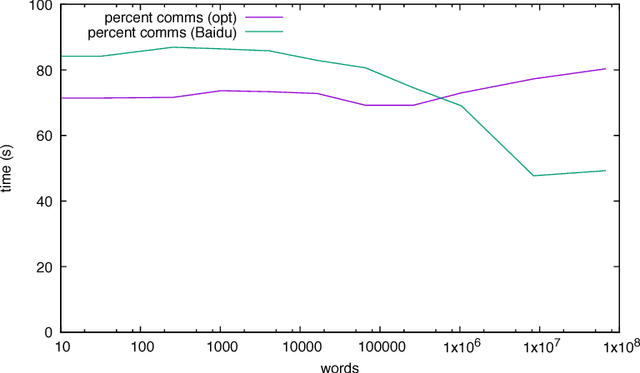
We discuss practical methods to ensure near wirespeed performance from clusters with either one or two Intel(R) Omni-Path host fabric interfaces (HFI) per node, and Intel(R) Xeon Phi(TM) 72xx (Knight's Landing) processors, and using the Linux operating system. The study evaluates the performance improvements achievable and the required programming approaches in two distinct example problems: firstly in Cartesian communicator halo exchange problems, appropriate for structured grid PDE solvers that arise in quantum chromodynamics simulations of particle physics, and secondly in gradient reduction appropriate to synchronous stochastic gradient descent for machine learning. As an example, we accelerate a published Baidu Research reduction code and obtain a factor of ten speedup over the original code using the techniques discussed in this paper. This displays how a factor of ten speedup in strongly scaled distributed machine learning could be achieved when synchronous stochastic gradient descent is massively parallelised with a fixed mini-batch size. We find a significant improvement in performance robustness when memory is obtained using carefully allocated 2MB "huge" virtual memory pages, implying that either non-standard allocation routines should be used for communication buffers. These can be accessed via a LD\_PRELOAD override in the manner suggested by libhugetlbfs. We make use of a the Intel(R) MPI 2019 library "Technology Preview" and underlying software to enable thread concurrency throughout the communication software stake via multiple PSM2 endpoints per process and use of multiple independent MPI communicators. When using a single MPI process per node, we find that this greatly accelerates delivered bandwidth in many core Intel(R) Xeon Phi processors.