 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating HPC codes on Intel Omni-Path Architecture networks: From particle physics to Machine Learning
Paper and Code
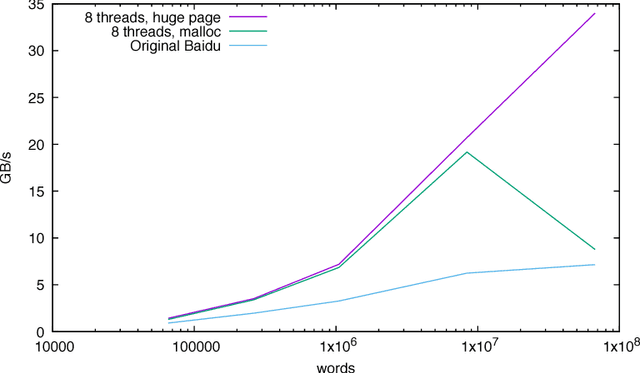
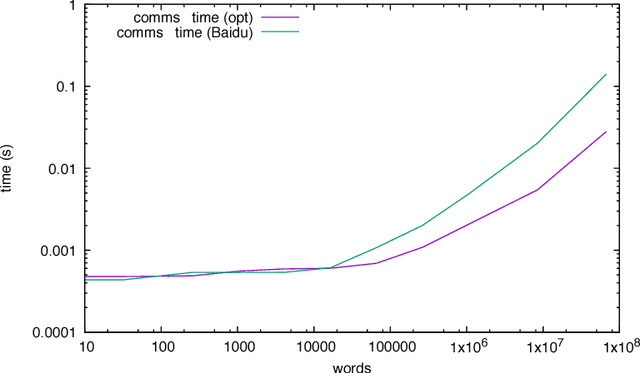
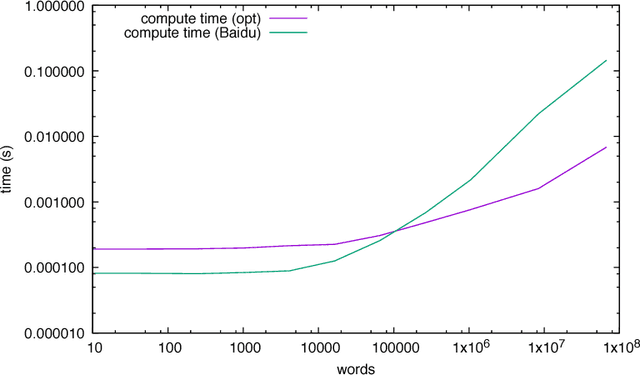
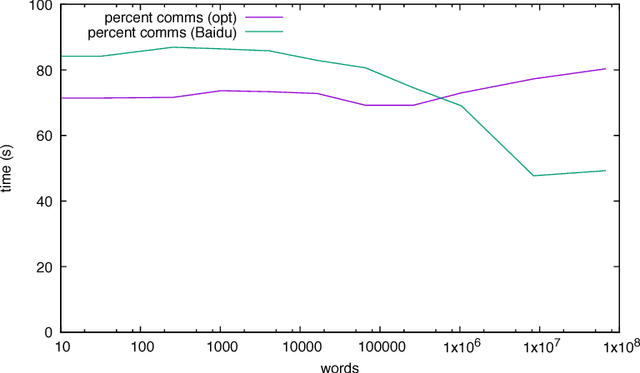
We discuss practical methods to ensure near wirespeed performance from clusters with either one or two Intel(R) Omni-Path host fabric interfaces (HFI) per node, and Intel(R) Xeon Phi(TM) 72xx (Knight's Landing) processors, and using the Linux operating system. The study evaluates the performance improvements achievable and the required programming approaches in two distinct example problems: firstly in Cartesian communicator halo exchange problems, appropriate for structured grid PDE solvers that arise in quantum chromodynamics simulations of particle physics, and secondly in gradient reduction appropriate to synchronous stochastic gradient descent for machine learning. As an example, we accelerate a published Baidu Research reduction code and obtain a factor of ten speedup over the original code using the techniques discussed in this paper. This displays how a factor of ten speedup in strongly scaled distributed machine learning could be achieved when synchronous stochastic gradient descent is massively parallelised with a fixed mini-batch size. We find a significant improvement in performance robustness when memory is obtained using carefully allocated 2MB "huge" virtual memory pages, implying that either non-standard allocation routines should be used for communication buffers. These can be accessed via a LD\_PRELOAD override in the manner suggested by libhugetlbfs. We make use of a the Intel(R) MPI 2019 library "Technology Preview" and underlying software to enable thread concurrency throughout the communication software stake via multiple PSM2 endpoints per process and use of multiple independent MPI communicators. When using a single MPI process per node, we find that this greatly accelerates delivered bandwidth in many core Intel(R) Xeon Phi processors.