 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Foundational Generative Model for Breast Ultrasound Image Analysis
Jan 12, 2025



Foundational models have emerged as powerful tools for addressing various tasks in clinical settings. However, their potential development to breast ultrasound analysis remains untapped. In this paper, we present BUSGen, the first foundational generative model specifically designed for breast ultrasound image analysis. Pretrained on over 3.5 million breast ultrasound images, BUSGen has acquired extensive knowledge of breast structures, pathological features, and clinical variations. With few-shot adaptation, BUSGen can generate repositories of realistic and informative task-specific data, facilitating the development of models for a wide range of downstream tasks. Extensive experiments highlight BUSGen's exceptional adaptability, significantly exceeding real-data-trained foundational models in breast cancer screening, diagnosis, and prognosis. In breast cancer early diagnosis, our approach outperformed all board-certified radiologists (n=9), achieving an average sensitivity improvement of 16.5% (P-value<0.0001). Additionally, we characterized the scaling effect of using generated data which was as effective as the collected real-world data for training diagnostic models. Moreover, extensive experiments demonstrated that our approach improved the generalization ability of downstream models. Importantly, BUSGen protected patient privacy by enabling fully de-identified data sharing, making progress forward in secure medical data utilization. An online demo of BUSGen is available at https://aibus.bio.
Mapping the Increasing Use of LLMs in Scientific Papers
Apr 01, 2024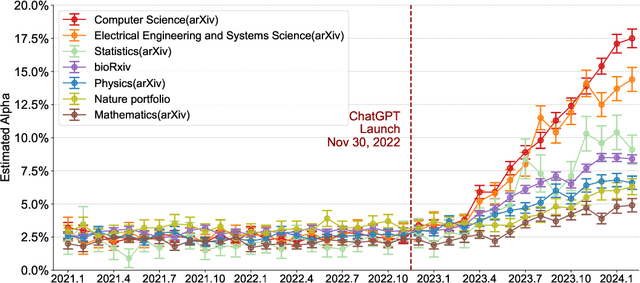
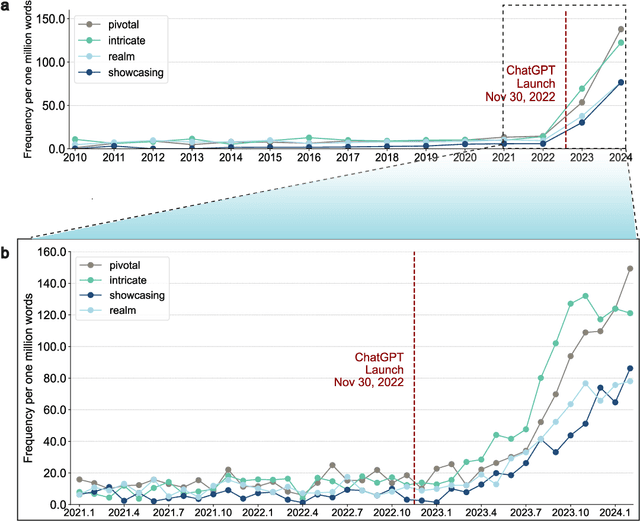
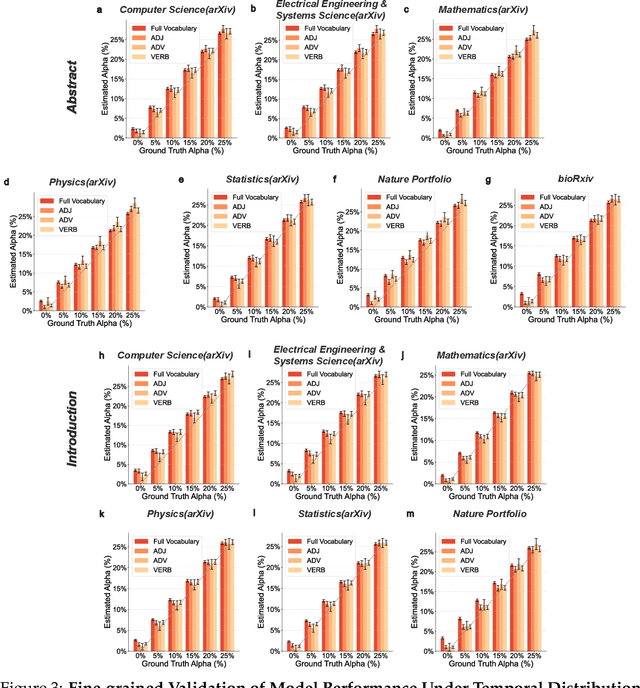
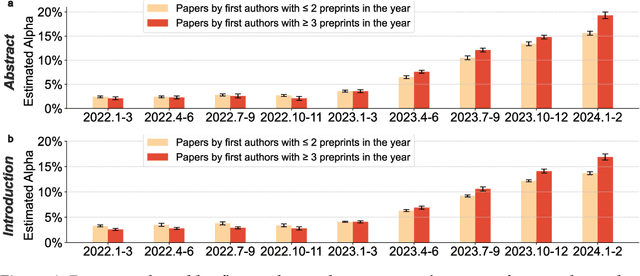
Scientific publishing lays the foundation of science by disseminating research findings, fostering collaboration, encouraging reproducibility, and ensuring that scientific knowledge is accessible, verifiable, and built upon over time. Recently, there has been immense speculation about how many people are using large language models (LLMs) like ChatGPT in their academic writing, and to what extent this tool might have an effect on global scientific practices. However, we lack a precise measure of the proportion of academic writing substantially modified or produced by LLMs. To address this gap, we conduct the first systematic, large-scale analysis across 950,965 papers published between January 2020 and February 2024 on the arXiv, bioRxiv, and Nature portfolio journals, using a population-level statistical framework to measure the prevalence of LLM-modified content over time. Our statistical estimation operates on the corpus level and is more robust than inference on individual instances. Our findings reveal a steady increase in LLM usage, with the largest and fastest growth observed in Computer Science papers (up to 17.5%). In comparison, Mathematics papers and the Nature portfolio showed the least LLM modification (up to 6.3%). Moreover, at an aggregate level, our analysis reveals that higher levels of LLM-modification are associated with papers whose first authors post preprints more frequently, papers in more crowded research areas, and papers of shorter lengths. Our findings suggests that LLMs are being broadly used in scientific writings.
Can large language models provide useful feedback on research papers? A large-scale empirical analysis
Oct 03, 2023



Expert feedback lays the foundation of rigorous research. However, the rapid growth of scholarly production and intricate knowledge specialization challenge the conventional scientific feedback mechanisms. High-quality peer reviews are increasingly difficult to obtain. Researchers who are more junior or from under-resourced settings have especially hard times getting timely feedback. With the breakthrough of large language models (LLM) such as GPT-4, there is growing interest in using LLMs to generate scientific feedback on research manuscripts. However, the utility of LLM-generated feedback has not been systematically studied. To address this gap, we created an automated pipeline using GPT-4 to provide comments on the full PDFs of scientific papers. We evaluated the quality of GPT-4's feedback through two large-scale studies. We first quantitatively compared GPT-4's generated feedback with human peer reviewer feedback in 15 Nature family journals (3,096 papers in total) and the ICLR machine learning conference (1,709 papers). The overlap in the points raised by GPT-4 and by human reviewers (average overlap 30.85% for Nature journals, 39.23% for ICLR) is comparable to the overlap between two human reviewers (average overlap 28.58% for Nature journals, 35.25% for ICLR). The overlap between GPT-4 and human reviewers is larger for the weaker papers. We then conducted a prospective user study with 308 researchers from 110 US institutions in the field of AI and computational biology to understand how researchers perceive feedback generated by our GPT-4 system on their own papers. Overall, more than half (57.4%) of the users found GPT-4 generated feedback helpful/very helpful and 82.4% found it more beneficial than feedback from at least some human reviewers. While our findings show that LLM-generated feedback can help researchers, we also identify several limitations.
Simple lessons from complex learning: what a neural network model learns about cosmic structure formation
Jun 14, 2022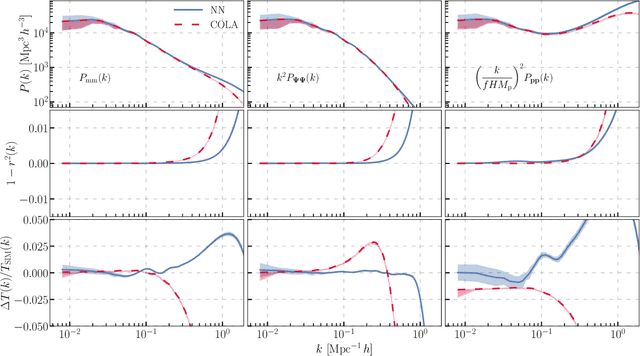
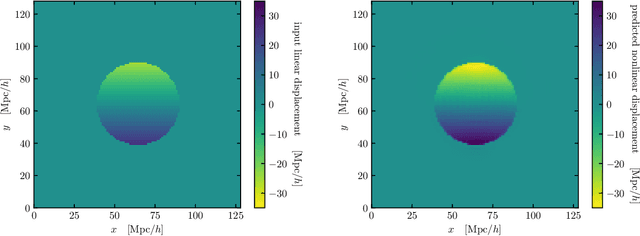
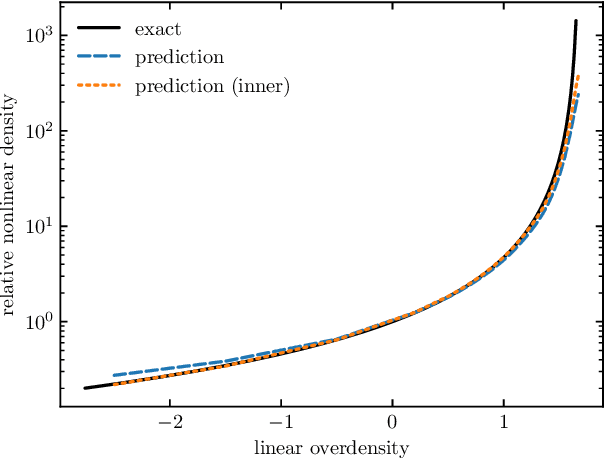
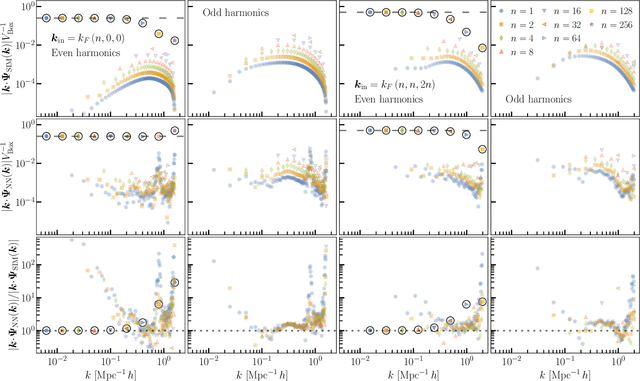
We train a neural network model to predict the full phase space evolution of cosmological N-body simulations. Its success implies that the neural network model is accurately approximating the Green's function expansion that relates the initial conditions of the simulations to its outcome at later times in the deeply nonlinear regime. We test the accuracy of this approximation by assessing its performance on well understood simple cases that have either known exact solutions or well understood expansions. These scenarios include spherical configurations, isolated plane waves, and two interacting plane waves: initial conditions that are very different from the Gaussian random fields used for training. We find our model generalizes well to these well understood scenarios, demonstrating that the networks have inferred general physical principles and learned the nonlinear mode couplings from the complex, random Gaussian training data. These tests also provide a useful diagnostic for finding the model's strengths and weaknesses, and identifying strategies for model improvement. We also test the model on initial conditions that contain only transverse modes, a family of modes that differ not only in their phases but also in their evolution from the longitudinal growing modes used in the training set. When the network encounters these initial conditions that are orthogonal to the training set, the model fails completely. In addition to these simple configurations, we evaluate the model's predictions for the density, displacement, and momentum power spectra with standard initial conditions for N-body simulations. We compare these summary statistics against N-body results and an approximate, fast simulation method called COLA. Our model achieves percent level accuracy at nonlinear scales of $k\sim 1\ \mathrm{Mpc}^{-1}\, h$, representing a significant improvement over COLA.
From Dark Matter to Galaxies with Convolutional Neural Networks
Oct 17, 2019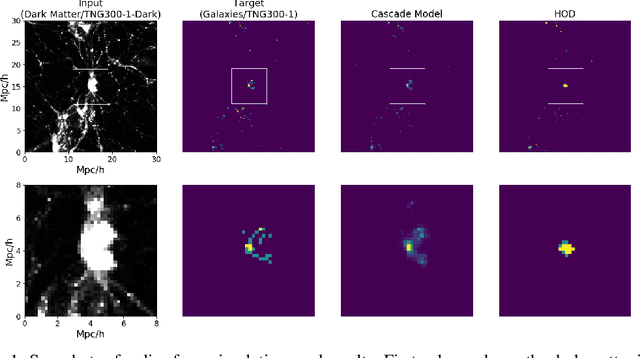
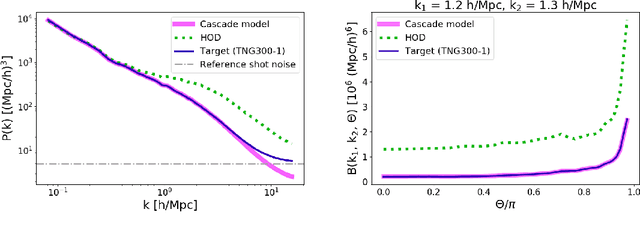
Cosmological simulations play an important role in the interpretation of astronomical data, in particular in comparing observed data to our theoretical expectations. However, to compare data with these simulations, the simulations in principle need to include gravity, magneto-hydrodyanmics, radiative transfer, etc. These ideal large-volume simulations (gravo-magneto-hydrodynamical) are incredibly computationally expensive which can cost tens of millions of CPU hours to run. In this paper, we propose a deep learning approach to map from the dark-matter-only simulation (computationally cheaper) to the galaxy distribution (from the much costlier cosmological simulation). The main challenge of this task is the high sparsity in the target galaxy distribution: space is mainly empty. We propose a cascade architecture composed of a classification filter followed by a regression procedure. We show that our result outperforms a state-of-the-art model used in the astronomical community, and provides a good trade-off between computational cost and prediction accuracy.
Learning neutrino effects in Cosmology with Convolutional Neural Networks
Oct 09, 2019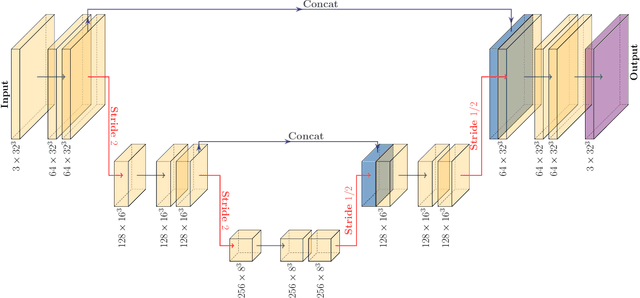

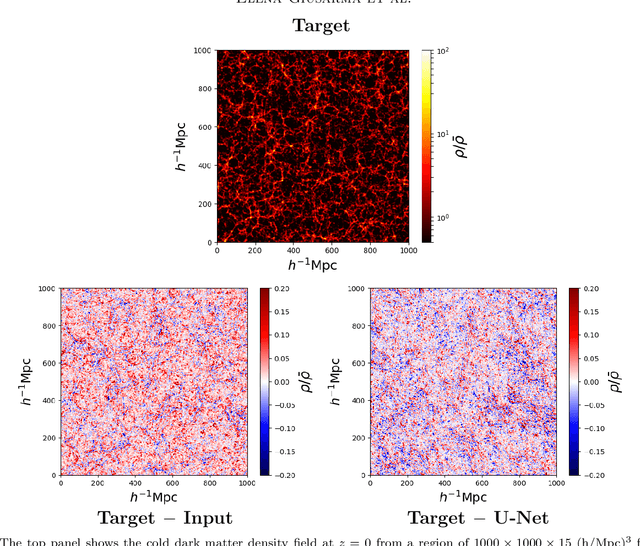
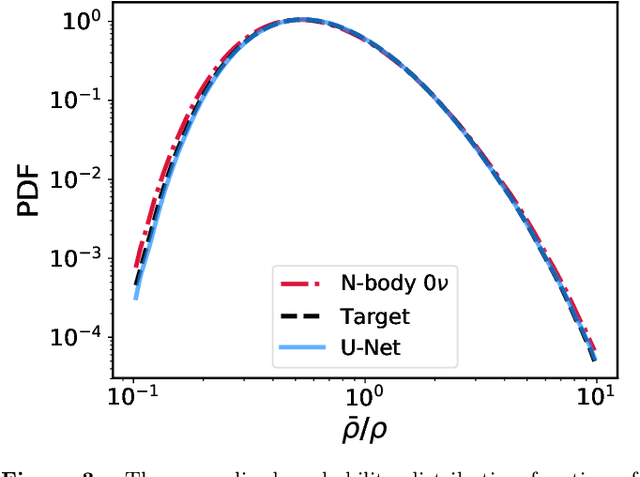
Measuring the sum of the three active neutrino masses, $M_\nu$, is one of the most important challenges in modern cosmology. Massive neutrinos imprint characteristic signatures on several cosmological observables in particular on the large-scale structure of the Universe. In order to maximize the information that can be retrieved from galaxy surveys, accurate theoretical predictions in the non-linear regime are needed. Currently, one way to achieve those predictions is by running cosmological numerical simulations. Unfortunately, producing those simulations requires high computational resources -- seven hundred CPU hours for each neutrino mass case. In this work, we propose a new method, based on a deep learning network (U-Net), to quickly generate simulations with massive neutrinos from standard $\Lambda$CDM simulations without neutrinos. We computed multiple relevant statistical measures of deep-learning generated simulations, and conclude that our method accurately reproduces the 3-dimensional spatial distribution of matter down to non-linear scales: $k < 0.7$ h/Mpc. Finally, our method allows us to generate massive neutrino simulations 10,000 times faster than the traditional methods.
HIGAN: Cosmic Neutral Hydrogen with Generative Adversarial Networks
Apr 29, 2019


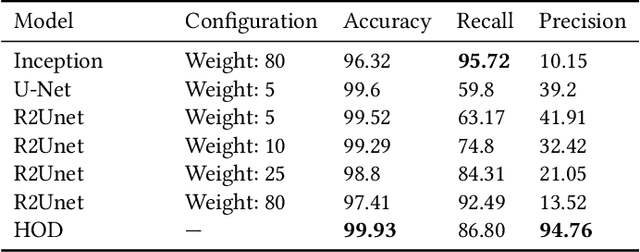
One of the most promising ways to observe the Universe is by detecting the 21cm emission from cosmic neutral hydrogen (HI) through radio-telescopes. Those observations can shed light on fundamental astrophysical questions only if accurate theoretical predictions are available. In order to maximize the scientific return of these surveys, those predictions need to include different observables and be precise on non-linear scales. Currently, one of the best ways to achieve this is via cosmological hydrodynamic simulations; however, the computational cost of these simulations is high -- tens of millions of CPU hours. In this work, we use Wasserstein Generative Adversarial Networks (WGANs) to generate new high-resolution ($35~h^{-1}{\rm kpc}$) 3D realizations of cosmic HI at $z=5$. We do so by sampling from a 100-dimension manifold, learned by the generator, that characterizes the fully non-linear abundance and clustering of cosmic HI from the state-of-the-art simulation IllustrisTNG. We show that different statistical properties of the produced samples -- 1D PDF, power spectrum, bispectrum, and void size function -- match very well those of IllustrisTNG, and outperform state-of-the-art models such as Halo Occupation Distributions (HODs). Our WGAN samples reproduce the abundance of HI across 9 orders of magnitude, from the Ly$\alpha$ forest to Damped Lyman Absorbers. WGAN can produce new samples orders of magnitude faster than hydrodynamic simulations.
From Dark Matter to Galaxies with Convolutional Networks
Apr 01, 2019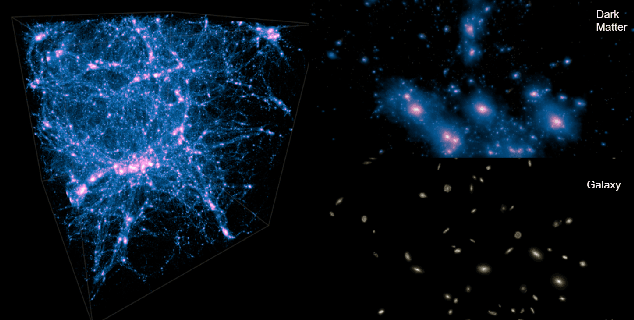
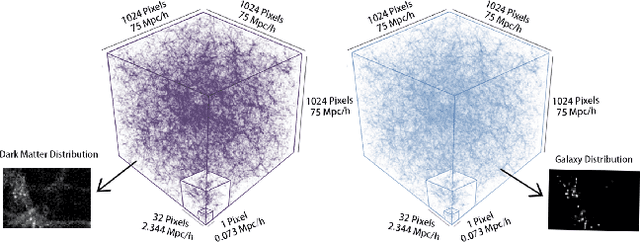
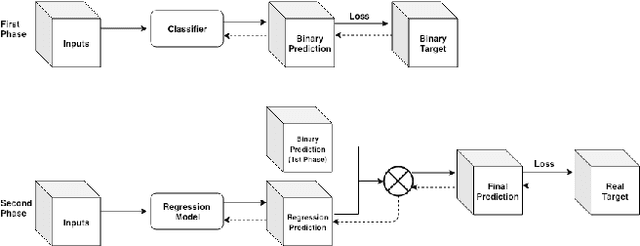
Cosmological surveys aim at answering fundamental questions about our Universe, including the nature of dark matter or the reason of unexpected accelerated expansion of the Universe. In order to answer these questions, two important ingredients are needed: 1) data from observations and 2) a theoretical model that allows fast comparison between observation and theory. Most of the cosmological surveys observe galaxies, which are very difficult to model theoretically due to the complicated physics involved in their formation and evolution; modeling realistic galaxies over cosmological volumes requires running computationally expensive hydrodynamic simulations that can cost millions of CPU hours. In this paper, we propose to use deep learning to establish a mapping between the 3D galaxy distribution in hydrodynamic simulations and its underlying dark matter distribution. One of the major challenges in this pursuit is the very high sparsity in the predicted galaxy distribution. To this end, we develop a two-phase convolutional neural network architecture to generate fast galaxy catalogues, and compare our results against a standard cosmological technique. We find that our proposed approach either outperforms or is competitive with traditional cosmological techniques. Compared to the common methods used in cosmology, our approach also provides a nice trade-off between time-consumption (comparable to fastest benchmark in the literature) and the quality and accuracy of the predicted simulation. In combination with current and upcoming data from cosmological observations, our method has the potential to answer fundamental questions about our Universe with the highest accuracy.
Learning to Predict the Cosmological Structure Formation
Nov 15, 2018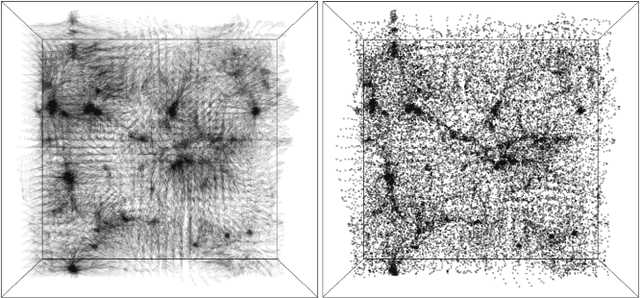
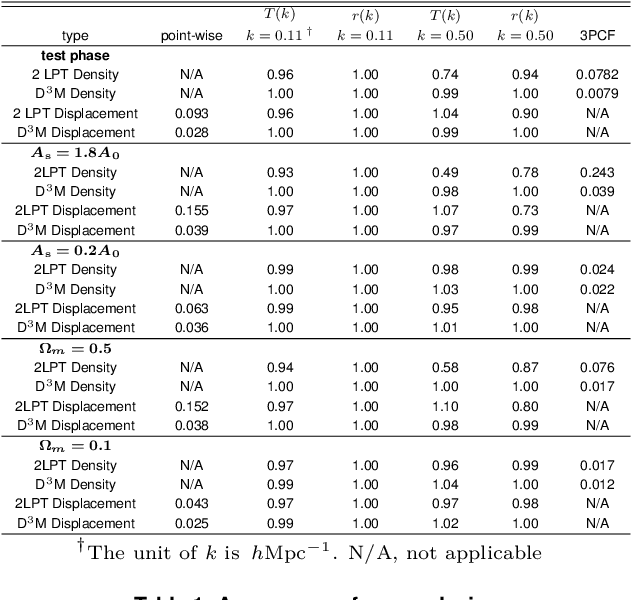

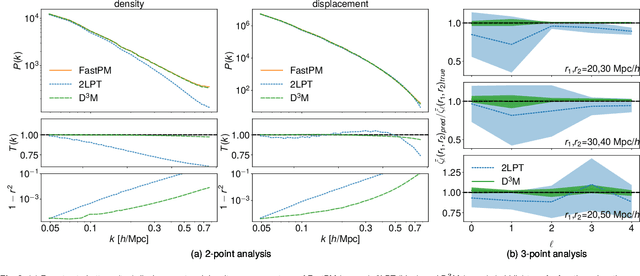
Matter evolved under influence of gravity from minuscule density fluctuations. Non-perturbative structure formed hierarchically over all scales, and developed non-Gaussian features in the Universe, known as the Cosmic Web. To fully understand the structure formation of the Universe is one of the holy grails of modern astrophysics. Astrophysicists survey large volumes of the Universe and employ a large ensemble of computer simulations to compare with the observed data in order to extract the full information of our own Universe. However, to evolve trillions of galaxies over billions of years even with the simplest physics is a daunting task. We build a deep neural network, the Deep Density Displacement Model (hereafter D$^3$M), to predict the non-linear structure formation of the Universe from simple linear perturbation theory. Our extensive analysis, demonstrates that D$^3$M outperforms the second order perturbation theory (hereafter 2LPT), the commonly used fast approximate simulation method, in point-wise comparison, 2-point correlation, and 3-point correlation. We also show that D$^3$M is able to accurately extrapolate far beyond its training data, and predict structure formation for significantly different cosmological parameters. Our study proves, for the first time, that deep learning is a practical and accurate alternative to approximate simulations of the gravitational structure formation of the Universe.
CosmoFlow: Using Deep Learning to Learn the Universe at Scale
Aug 14, 2018
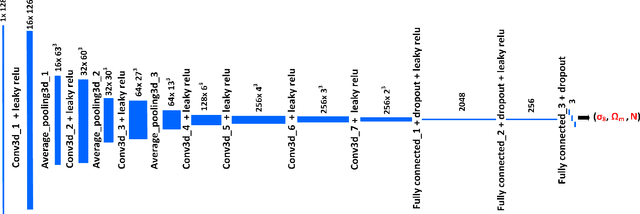
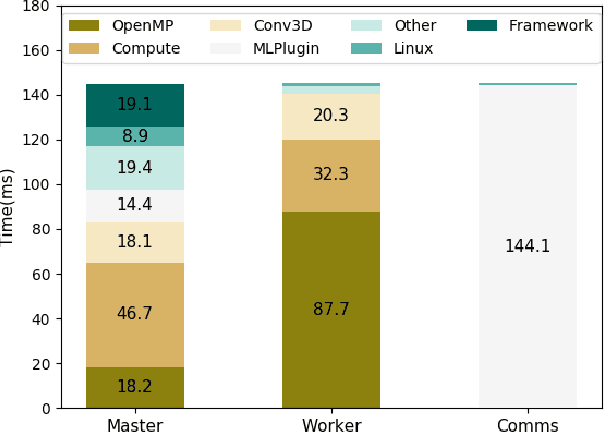
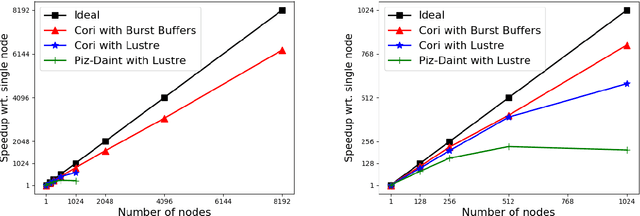
Deep learning is a promising tool to determine the physical model that describes our universe. To handle the considerable computational cost of this problem, we present CosmoFlow: a highly scalable deep learning application built on top of the TensorFlow framework. CosmoFlow uses efficient implementations of 3D convolution and pooling primitives, together with improvements in threading for many element-wise operations, to improve training performance on Intel(C) Xeon Phi(TM) processors. We also utilize the Cray PE Machine Learning Plugin for efficient scaling to multiple nodes. We demonstrate fully synchronous data-parallel training on 8192 nodes of Cori with 77% parallel efficiency, achieving 3.5 Pflop/s sustained performance. To our knowledge, this is the first large-scale science application of the TensorFlow framework at supercomputer scale with fully-synchronous training. These enhancements enable us to process large 3D dark matter distribution and predict the cosmological parameters $\Omega_M$, $\sigma_8$ and n$_s$ with unprecedented accuracy.