 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-AI Collaboration in Science at Scale: A Global Large-scale Randomized Field Experiment
May 22, 2026Collaboration is the defining mode of modern science, yet its core mechanism -- feedback -- remains hard to observe, difficult to scale, and unequally distributed. Here we test whether large language models (LLMs) can contribute to this hidden but vital practice and reallocate scientific feedback, an essential yet scarce resource for knowledge production. In a global large-scale randomized field experiment, we delivered customized LLM-generated feedback for over 31,000 arXiv preprints across 150 fields and more than 45,000 researchers from 133 geographic regions. Relative to controls, authors who received feedback had a significantly higher likelihood of revising their manuscripts, corresponding to a 12.55% relative increase over the baseline revision rate. Exposure to AI feedback also increased authors' subsequent use of LLM tools in their future papers, suggesting longer-run shifts in scientific practice. These effects were strongest among authors from non-English-dominant research regions, manuscripts less embedded in the scholarly literature, and teams with lower h-indexes and earlier career stages, consistent with the idea that AI feedback may provide the greatest benefit where access to timely critique is otherwise limited. Together, these findings provide causal evidence that structured AI-based interventions can transform access to scientific feedback from a largely private advantage into a more widely distributed resource, with broader implications for productivity, equity, and capacity across the global research system.
Multi-Agent Teams Hold Experts Back
Feb 03, 2026Multi-agent LLM systems are increasingly deployed as autonomous collaborators, where agents interact freely rather than execute fixed, pre-specified workflows. In such settings, effective coordination cannot be fully designed in advance and must instead emerge through interaction. However, most prior work enforces coordination through fixed roles, workflows, or aggregation rules, leaving open the question of how well self-organizing teams perform when coordination is unconstrained. Drawing on organizational psychology, we study whether self-organizing LLM teams achieve strong synergy, where team performance matches or exceeds the best individual member. Across human-inspired and frontier ML benchmarks, we find that -- unlike human teams -- LLM teams consistently fail to match their expert agent's performance, even when explicitly told who the expert is, incurring performance losses of up to 37.6%. Decomposing this failure, we show that expert leveraging, rather than identification, is the primary bottleneck. Conversational analysis reveals a tendency toward integrative compromise -- averaging expert and non-expert views rather than appropriately weighting expertise -- which increases with team size and correlates negatively with performance. Interestingly, this consensus-seeking behavior improves robustness to adversarial agents, suggesting a trade-off between alignment and effective expertise utilization. Our findings reveal a significant gap in the ability of self-organizing multi-agent teams to harness the collective expertise of their members.
From Replication to Redesign: Exploring Pairwise Comparisons for LLM-Based Peer Review
Jun 12, 2025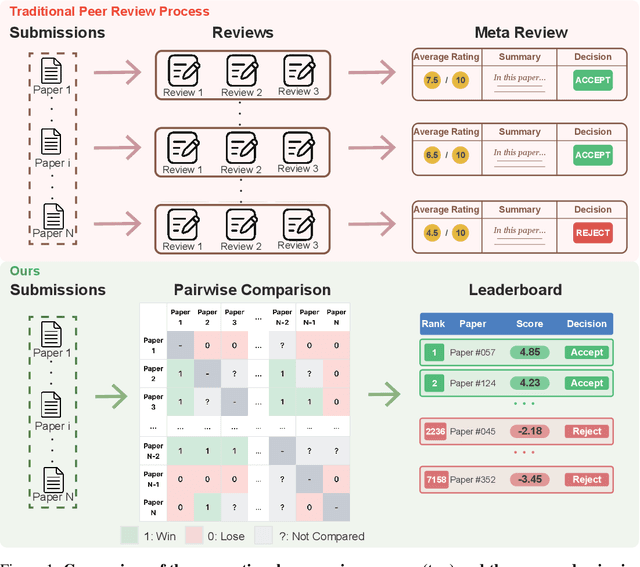
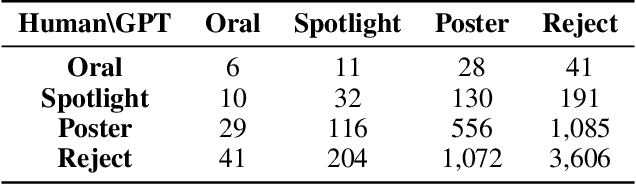
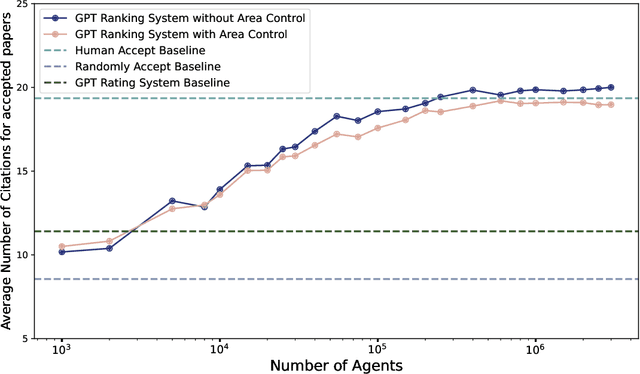
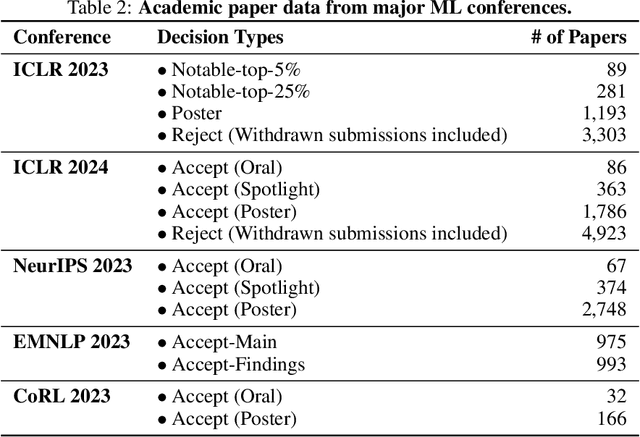
The advent of large language models (LLMs) offers unprecedented opportunities to reimagine peer review beyond the constraints of traditional workflows. Despite these opportunities, prior efforts have largely focused on replicating traditional review workflows with LLMs serving as direct substitutes for human reviewers, while limited attention has been given to exploring new paradigms that fundamentally rethink how LLMs can participate in the academic review process. In this paper, we introduce and explore a novel mechanism that employs LLM agents to perform pairwise comparisons among manuscripts instead of individual scoring. By aggregating outcomes from substantial pairwise evaluations, this approach enables a more accurate and robust measure of relative manuscript quality. Our experiments demonstrate that this comparative approach significantly outperforms traditional rating-based methods in identifying high-impact papers. However, our analysis also reveals emergent biases in the selection process, notably a reduced novelty in research topics and an increased institutional imbalance. These findings highlight both the transformative potential of rethinking peer review with LLMs and critical challenges that future systems must address to ensure equity and diversity.
Prototypical Human-AI Collaboration Behaviors from LLM-Assisted Writing in the Wild
May 21, 2025As large language models (LLMs) are used in complex writing workflows, users engage in multi-turn interactions to steer generations to better fit their needs. Rather than passively accepting output, users actively refine, explore, and co-construct text. We conduct a large-scale analysis of this collaborative behavior for users engaged in writing tasks in the wild with two popular AI assistants, Bing Copilot and WildChat. Our analysis goes beyond simple task classification or satisfaction estimation common in prior work and instead characterizes how users interact with LLMs through the course of a session. We identify prototypical behaviors in how users interact with LLMs in prompts following their original request. We refer to these as Prototypical Human-AI Collaboration Behaviors (PATHs) and find that a small group of PATHs explain a majority of the variation seen in user-LLM interaction. These PATHs span users revising intents, exploring texts, posing questions, adjusting style or injecting new content. Next, we find statistically significant correlations between specific writing intents and PATHs, revealing how users' intents shape their collaboration behaviors. We conclude by discussing the implications of our findings on LLM alignment.
Mapping the Increasing Use of LLMs in Scientific Papers
Apr 01, 2024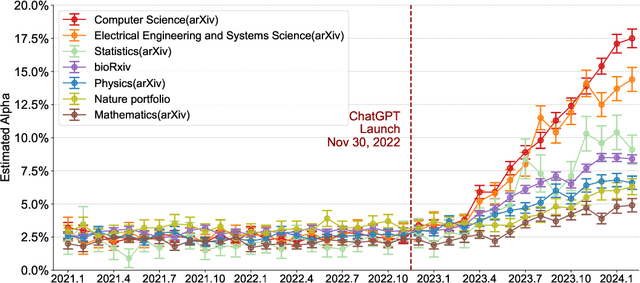
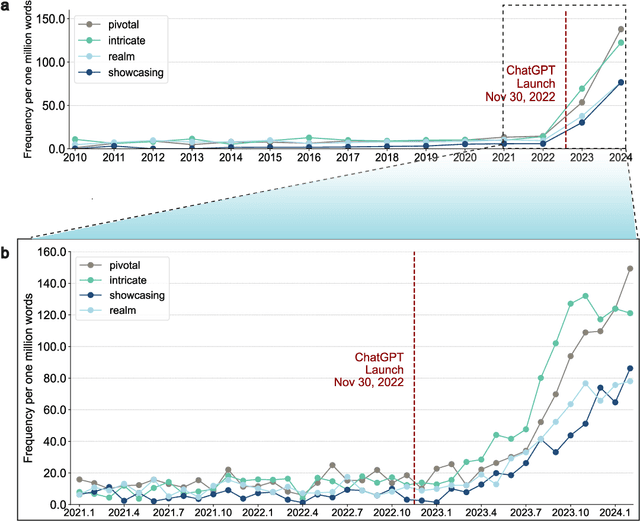
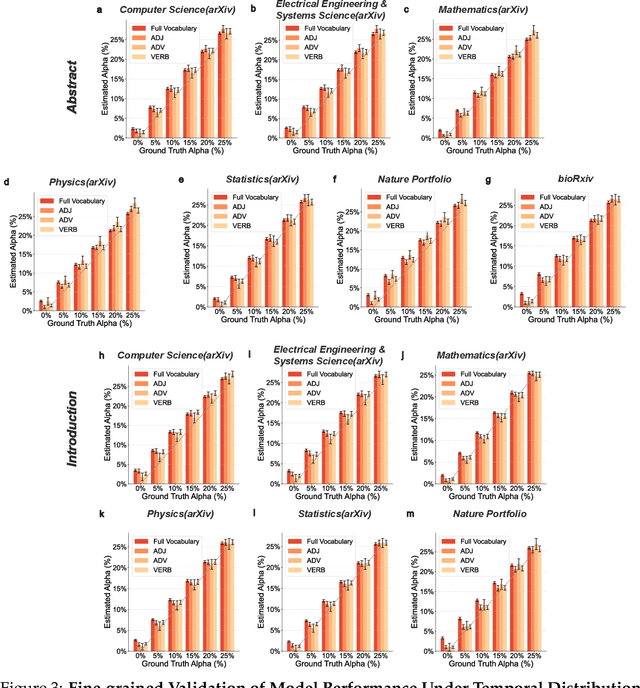
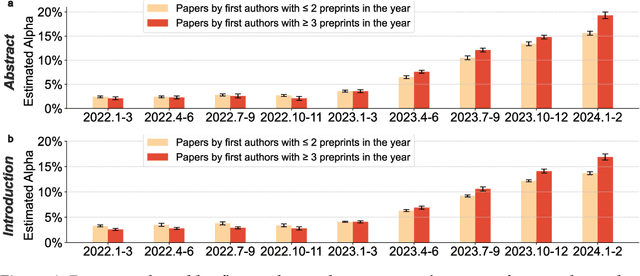
Scientific publishing lays the foundation of science by disseminating research findings, fostering collaboration, encouraging reproducibility, and ensuring that scientific knowledge is accessible, verifiable, and built upon over time. Recently, there has been immense speculation about how many people are using large language models (LLMs) like ChatGPT in their academic writing, and to what extent this tool might have an effect on global scientific practices. However, we lack a precise measure of the proportion of academic writing substantially modified or produced by LLMs. To address this gap, we conduct the first systematic, large-scale analysis across 950,965 papers published between January 2020 and February 2024 on the arXiv, bioRxiv, and Nature portfolio journals, using a population-level statistical framework to measure the prevalence of LLM-modified content over time. Our statistical estimation operates on the corpus level and is more robust than inference on individual instances. Our findings reveal a steady increase in LLM usage, with the largest and fastest growth observed in Computer Science papers (up to 17.5%). In comparison, Mathematics papers and the Nature portfolio showed the least LLM modification (up to 6.3%). Moreover, at an aggregate level, our analysis reveals that higher levels of LLM-modification are associated with papers whose first authors post preprints more frequently, papers in more crowded research areas, and papers of shorter lengths. Our findings suggests that LLMs are being broadly used in scientific writings.
Monitoring AI-Modified Content at Scale: A Case Study on the Impact of ChatGPT on AI Conference Peer Reviews
Mar 11, 2024



We present an approach for estimating the fraction of text in a large corpus which is likely to be substantially modified or produced by a large language model (LLM). Our maximum likelihood model leverages expert-written and AI-generated reference texts to accurately and efficiently examine real-world LLM-use at the corpus level. We apply this approach to a case study of scientific peer review in AI conferences that took place after the release of ChatGPT: ICLR 2024, NeurIPS 2023, CoRL 2023 and EMNLP 2023. Our results suggest that between 6.5% and 16.9% of text submitted as peer reviews to these conferences could have been substantially modified by LLMs, i.e. beyond spell-checking or minor writing updates. The circumstances in which generated text occurs offer insight into user behavior: the estimated fraction of LLM-generated text is higher in reviews which report lower confidence, were submitted close to the deadline, and from reviewers who are less likely to respond to author rebuttals. We also observe corpus-level trends in generated text which may be too subtle to detect at the individual level, and discuss the implications of such trends on peer review. We call for future interdisciplinary work to examine how LLM use is changing our information and knowledge practices.
The Rise of Open Science: Tracking the Evolution and Perceived Value of Data and Methods Link-Sharing Practices
Oct 04, 2023



In recent years, funding agencies and journals increasingly advocate for open science practices (e.g. data and method sharing) to improve the transparency, access, and reproducibility of science. However, quantifying these practices at scale has proven difficult. In this work, we leverage a large-scale dataset of 1.1M papers from arXiv that are representative of the fields of physics, math, and computer science to analyze the adoption of data and method link-sharing practices over time and their impact on article reception. To identify links to data and methods, we train a neural text classification model to automatically classify URL types based on contextual mentions in papers. We find evidence that the practice of link-sharing to methods and data is spreading as more papers include such URLs over time. Reproducibility efforts may also be spreading because the same links are being increasingly reused across papers (especially in computer science); and these links are increasingly concentrated within fewer web domains (e.g. Github) over time. Lastly, articles that share data and method links receive increased recognition in terms of citation count, with a stronger effect when the shared links are active (rather than defunct). Together, these findings demonstrate the increased spread and perceived value of data and method sharing practices in open science.
Can large language models provide useful feedback on research papers? A large-scale empirical analysis
Oct 03, 2023



Expert feedback lays the foundation of rigorous research. However, the rapid growth of scholarly production and intricate knowledge specialization challenge the conventional scientific feedback mechanisms. High-quality peer reviews are increasingly difficult to obtain. Researchers who are more junior or from under-resourced settings have especially hard times getting timely feedback. With the breakthrough of large language models (LLM) such as GPT-4, there is growing interest in using LLMs to generate scientific feedback on research manuscripts. However, the utility of LLM-generated feedback has not been systematically studied. To address this gap, we created an automated pipeline using GPT-4 to provide comments on the full PDFs of scientific papers. We evaluated the quality of GPT-4's feedback through two large-scale studies. We first quantitatively compared GPT-4's generated feedback with human peer reviewer feedback in 15 Nature family journals (3,096 papers in total) and the ICLR machine learning conference (1,709 papers). The overlap in the points raised by GPT-4 and by human reviewers (average overlap 30.85% for Nature journals, 39.23% for ICLR) is comparable to the overlap between two human reviewers (average overlap 28.58% for Nature journals, 35.25% for ICLR). The overlap between GPT-4 and human reviewers is larger for the weaker papers. We then conducted a prospective user study with 308 researchers from 110 US institutions in the field of AI and computational biology to understand how researchers perceive feedback generated by our GPT-4 system on their own papers. Overall, more than half (57.4%) of the users found GPT-4 generated feedback helpful/very helpful and 82.4% found it more beneficial than feedback from at least some human reviewers. While our findings show that LLM-generated feedback can help researchers, we also identify several limitations.
User Experience Design Professionals' Perceptions of Generative Artificial Intelligence
Sep 26, 2023



Among creative professionals, Generative Artificial Intelligence (GenAI) has sparked excitement over its capabilities and fear over unanticipated consequences. How does GenAI impact User Experience Design (UXD) practice, and are fears warranted? We interviewed 20 UX Designers, with diverse experience and across companies (startups to large enterprises). We probed them to characterize their practices, and sample their attitudes, concerns, and expectations. We found that experienced designers are confident in their originality, creativity, and empathic skills, and find GenAI's role as assistive. They emphasized the unique human factors of "enjoyment" and "agency", where humans remain the arbiters of "AI alignment". However, skill degradation, job replacement, and creativity exhaustion can adversely impact junior designers. We discuss implications for human-GenAI collaboration, specifically copyright and ownership, human creativity and agency, and AI literacy and access. Through the lens of responsible and participatory AI, we contribute a deeper understanding of GenAI fears and opportunities for UXD.
Comparing scalable strategies for generating numerical perspectives
Aug 03, 2023



Numerical perspectives help people understand extreme and unfamiliar numbers (e.g., \$330 billion is about \$1,000 per person in the United States). While research shows perspectives to be helpful, generating them at scale is challenging both because it is difficult to identify what makes some analogies more helpful than others, and because what is most helpful can vary based on the context in which a given number appears. Here we present and compare three policies for large-scale perspective generation: a rule-based approach, a crowdsourced system, and a model that uses Wikipedia data and semantic similarity (via BERT embeddings) to generate context-specific perspectives. We find that the combination of these three approaches dominates any single method, with different approaches excelling in different settings and users displaying heterogeneous preferences across approaches. We conclude by discussing our deployment of perspectives in a widely-used online word processor.