 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-registration for Predictive Modeling
Nov 30, 2023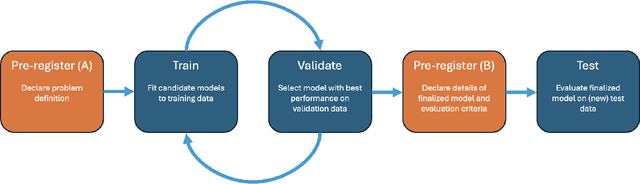



Amid rising concerns of reproducibility and generalizability in predictive modeling, we explore the possibility and potential benefits of introducing pre-registration to the field. Despite notable advancements in predictive modeling, spanning core machine learning tasks to various scientific applications, challenges such as overlooked contextual factors, data-dependent decision-making, and unintentional re-use of test data have raised questions about the integrity of results. To address these issues, we propose adapting pre-registration practices from explanatory modeling to predictive modeling. We discuss current best practices in predictive modeling and their limitations, introduce a lightweight pre-registration template, and present a qualitative study with machine learning researchers to gain insight into the effectiveness of pre-registration in preventing biased estimates and promoting more reliable research outcomes. We conclude by exploring the scope of problems that pre-registration can address in predictive modeling and acknowledging its limitations within this context.
REFORMS: Reporting Standards for Machine Learning Based Science
Aug 15, 2023
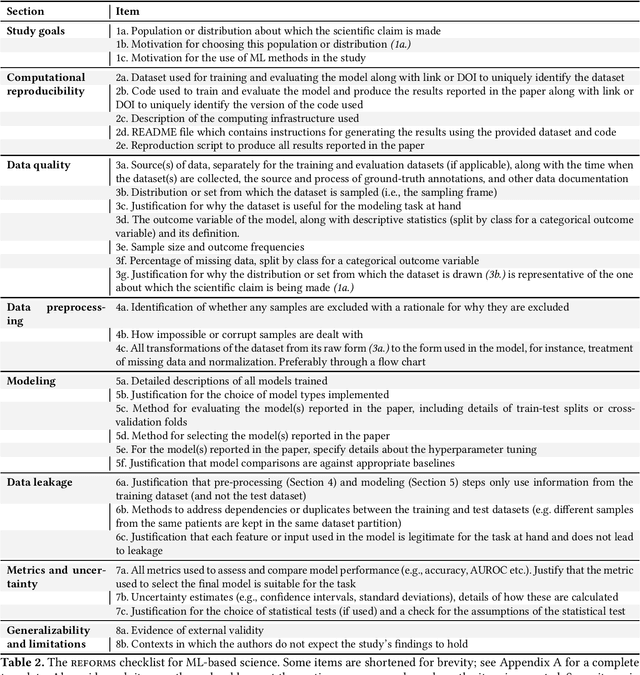
Machine learning (ML) methods are proliferating in scientific research. However, the adoption of these methods has been accompanied by failures of validity, reproducibility, and generalizability. These failures can hinder scientific progress, lead to false consensus around invalid claims, and undermine the credibility of ML-based science. ML methods are often applied and fail in similar ways across disciplines. Motivated by this observation, our goal is to provide clear reporting standards for ML-based science. Drawing from an extensive review of past literature, we present the REFORMS checklist ($\textbf{Re}$porting Standards $\textbf{For}$ $\textbf{M}$achine Learning Based $\textbf{S}$cience). It consists of 32 questions and a paired set of guidelines. REFORMS was developed based on a consensus of 19 researchers across computer science, data science, mathematics, social sciences, and biomedical sciences. REFORMS can serve as a resource for researchers when designing and implementing a study, for referees when reviewing papers, and for journals when enforcing standards for transparency and reproducibility.
Comparing scalable strategies for generating numerical perspectives
Aug 03, 2023



Numerical perspectives help people understand extreme and unfamiliar numbers (e.g., \$330 billion is about \$1,000 per person in the United States). While research shows perspectives to be helpful, generating them at scale is challenging both because it is difficult to identify what makes some analogies more helpful than others, and because what is most helpful can vary based on the context in which a given number appears. Here we present and compare three policies for large-scale perspective generation: a rule-based approach, a crowdsourced system, and a model that uses Wikipedia data and semantic similarity (via BERT embeddings) to generate context-specific perspectives. We find that the combination of these three approaches dominates any single method, with different approaches excelling in different settings and users displaying heterogeneous preferences across approaches. We conclude by discussing our deployment of perspectives in a widely-used online word processor.
Multi-Target Multiplicity: Flexibility and Fairness in Target Specification under Resource Constraints
Jun 23, 2023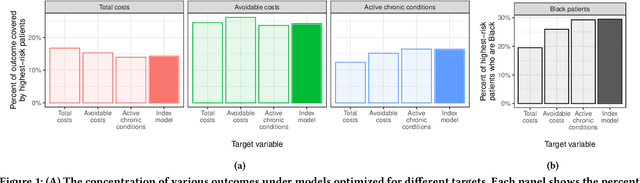



Prediction models have been widely adopted as the basis for decision-making in domains as diverse as employment, education, lending, and health. Yet, few real world problems readily present themselves as precisely formulated prediction tasks. In particular, there are often many reasonable target variable options. Prior work has argued that this is an important and sometimes underappreciated choice, and has also shown that target choice can have a significant impact on the fairness of the resulting model. However, the existing literature does not offer a formal framework for characterizing the extent to which target choice matters in a particular task. Our work fills this gap by drawing connections between the problem of target choice and recent work on predictive multiplicity. Specifically, we introduce a conceptual and computational framework for assessing how the choice of target affects individuals' outcomes and selection rate disparities across groups. We call this multi-target multiplicity. Along the way, we refine the study of single-target multiplicity by introducing notions of multiplicity that respect resource constraints -- a feature of many real-world tasks that is not captured by existing notions of predictive multiplicity. We apply our methods on a healthcare dataset, and show that the level of multiplicity that stems from target variable choice can be greater than that stemming from nearly-optimal models of a single target.
* Conference on Fairness, Accountability, and Transparency (FAccT '23), June 12-15, 2023, Chicago, IL, USA
Manipulating and Measuring Model Interpretability
Sep 26, 2018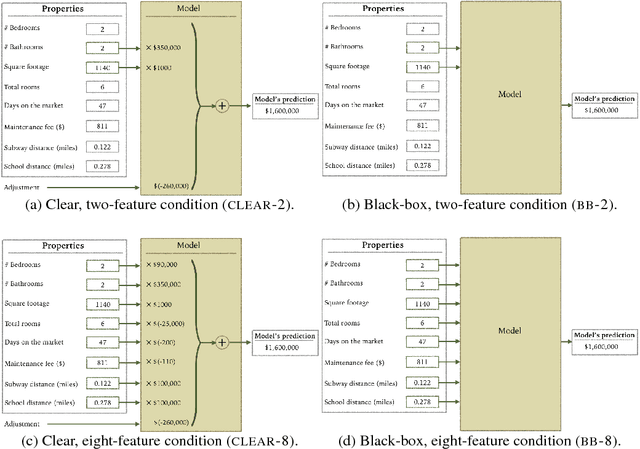

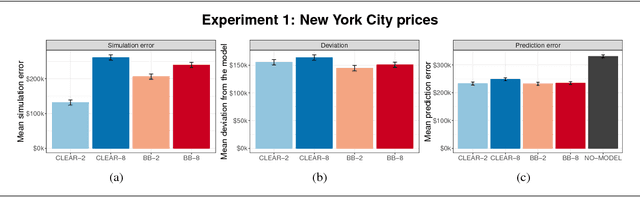
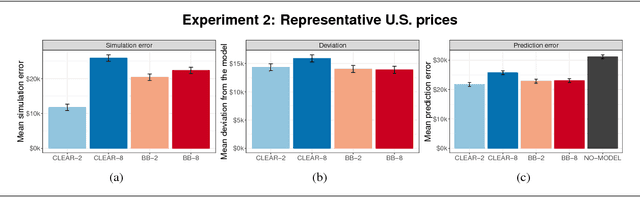
Despite a growing literature on creating interpretable machine learning methods, there have been few experimental studies of their effects on end users. We present a series of large-scale, randomized, pre-registered experiments in which participants were shown functionally identical models that varied only in two factors thought to influence interpretability: the number of input features and the model transparency (clear or black-box). Participants who were shown a clear model with a small number of features were better able to simulate the model's predictions. However, contrary to what one might expect when manipulating interpretability, we found no significant difference in multiple measures of trust across conditions. Even more surprisingly, increased transparency hampered people's ability to detect when a model has made a sizeable mistake. These findings emphasize the importance of studying how models are presented to people and empirically verifying that interpretable models achieve their intended effects on end users.
Split-door criterion: Identification of causal effects through auxiliary outcomes
Jun 14, 2018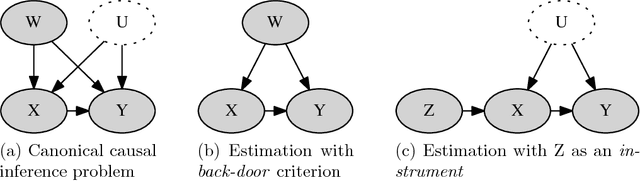
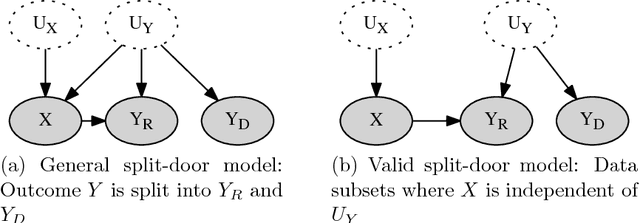
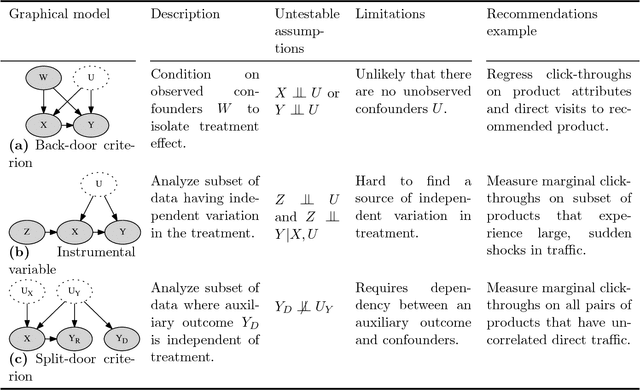

We present a method for estimating causal effects in time series data when fine-grained information about the outcome of interest is available. Specifically, we examine what we call the split-door setting, where the outcome variable can be split into two parts: one that is potentially affected by the cause being studied and another that is independent of it, with both parts sharing the same (unobserved) confounders. We show that under these conditions, the problem of identification reduces to that of testing for independence among observed variables, and present a method that uses this approach to automatically find subsets of the data that are causally identified. We demonstrate the method by estimating the causal impact of Amazon's recommender system on traffic to product pages, finding thousands of examples within the dataset that satisfy the split-door criterion. Unlike past studies based on natural experiments that were limited to a single product category, our method applies to a large and representative sample of products viewed on the site. In line with previous work, we find that the widely-used click-through rate (CTR) metric overestimates the causal impact of recommender systems; depending on the product category, we estimate that 50-80\% of the traffic attributed to recommender systems would have happened even without any recommendations. We conclude with guidelines for using the split-door criterion as well as a discussion of other contexts where the method can be applied.
Scalable Recommendation with Poisson Factorization
May 20, 2014
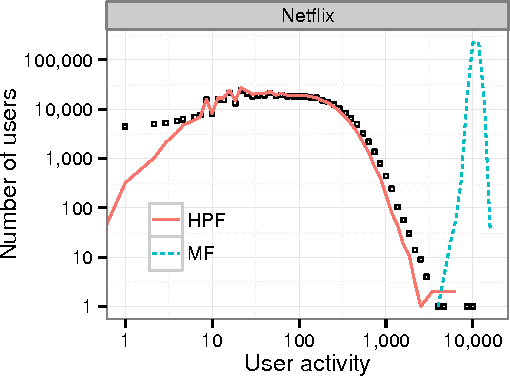


We develop a Bayesian Poisson matrix factorization model for forming recommendations from sparse user behavior data. These data are large user/item matrices where each user has provided feedback on only a small subset of items, either explicitly (e.g., through star ratings) or implicitly (e.g., through views or purchases). In contrast to traditional matrix factorization approaches, Poisson factorization implicitly models each user's limited attention to consume items. Moreover, because of the mathematical form of the Poisson likelihood, the model needs only to explicitly consider the observed entries in the matrix, leading to both scalable computation and good predictive performance. We develop a variational inference algorithm for approximate posterior inference that scales up to massive data sets. This is an efficient algorithm that iterates over the observed entries and adjusts an approximate posterior over the user/item representations. We apply our method to large real-world user data containing users rating movies, users listening to songs, and users reading scientific papers. In all these settings, Bayesian Poisson factorization outperforms state-of-the-art matrix factorization methods.
A Bayesian Approach to Network Modularity
Jun 23, 2008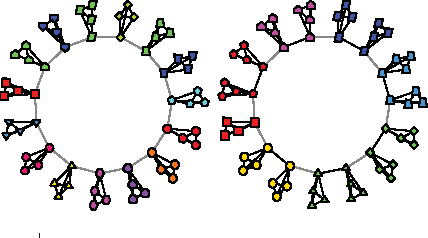
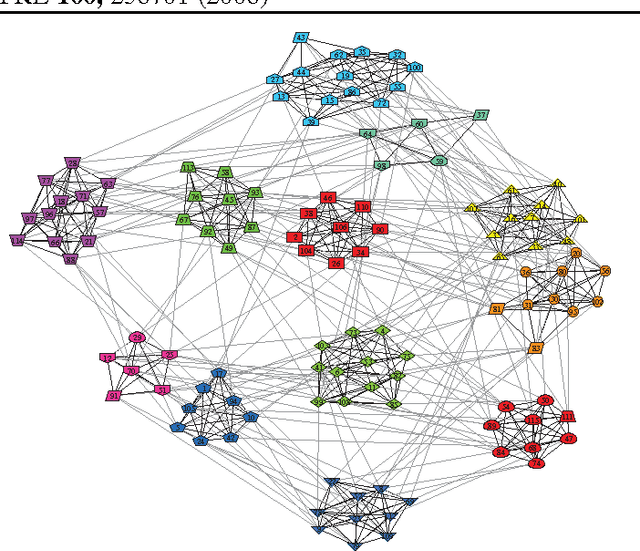
We present an efficient, principled, and interpretable technique for inferring module assignments and for identifying the optimal number of modules in a given network. We show how several existing methods for finding modules can be described as variant, special, or limiting cases of our work, and how the method overcomes the resolution limit problem, accurately recovering the true number of modules. Our approach is based on Bayesian methods for model selection which have been used with success for almost a century, implemented using a variational technique developed only in the past decade. We apply the technique to synthetic and real networks and outline how the method naturally allows selection among competing models.
* Phys. Rev. Lett. 100, 258701 (2008)