 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA generative, predictive model for menstrual cycle lengths that accounts for potential self-tracking artifacts in mobile health data
Mar 16, 2021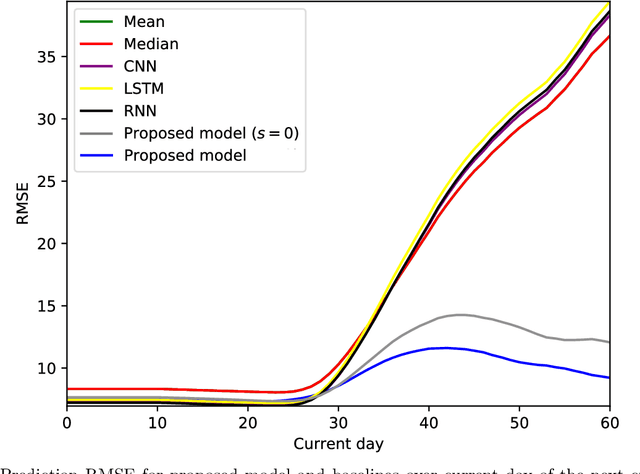
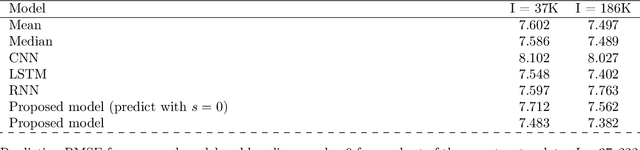
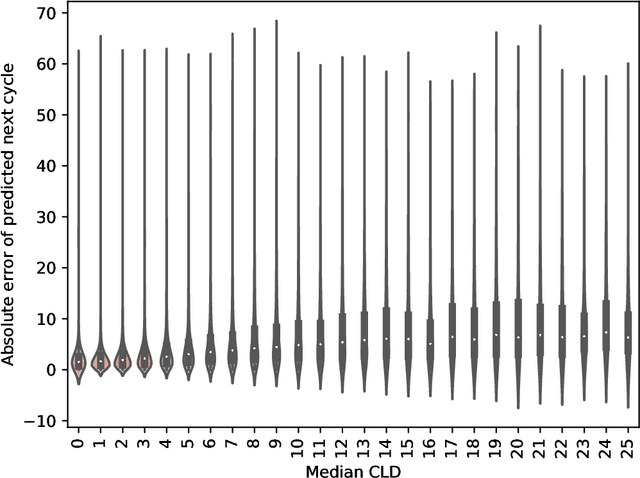

Mobile health (mHealth) apps such as menstrual trackers provide a rich source of self-tracked health observations that can be leveraged for health-relevant research. However, such data streams have questionable reliability since they hinge on user adherence to the app. Therefore, it is crucial for researchers to separate true behavior from self-tracking artifacts. By taking a machine learning approach to modeling self-tracked cycle lengths, we can both make more informed predictions and learn the underlying structure of the observed data. In this work, we propose and evaluate a hierarchical, generative model for predicting next cycle length based on previously-tracked cycle lengths that accounts explicitly for the possibility of users skipping tracking their period. Our model offers several advantages: 1) accounting explicitly for self-tracking artifacts yields better prediction accuracy as likelihood of skipping increases; 2) because it is a generative model, predictions can be updated online as a given cycle evolves, and we can gain interpretable insight into how these predictions change over time; and 3) its hierarchical nature enables modeling of an individual's cycle length history while incorporating population-level information. Our experiments using mHealth cycle length data encompassing over 186,000 menstruators with over 2 million natural menstrual cycles show that our method yields state-of-the-art performance against neural network-based and summary statistic-based baselines, while providing insights on disentangling menstrual patterns from self-tracking artifacts. This work can benefit users, mHealth app developers, and researchers in better understanding cycle patterns and user adherence.
(Sequential) Importance Sampling Bandits
Aug 29, 2018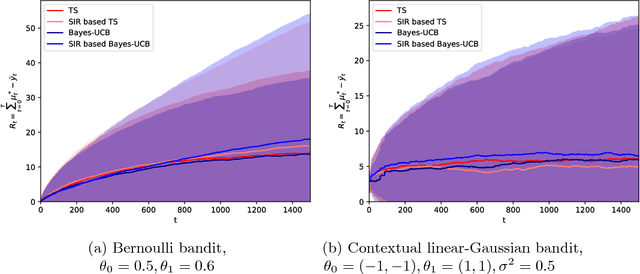

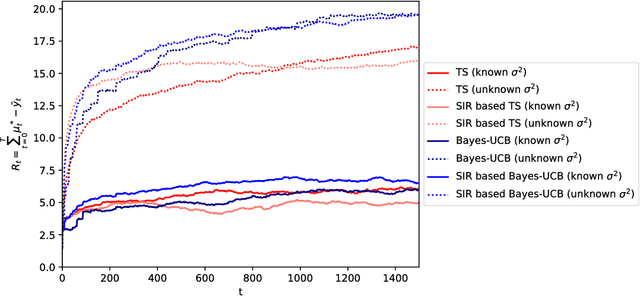
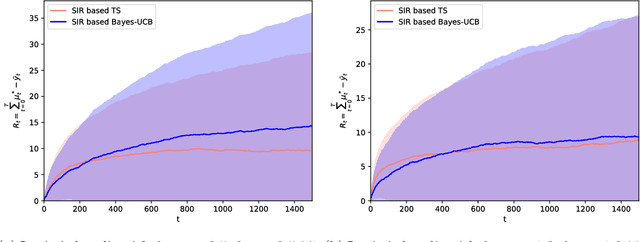
The multi-armed bandit (MAB) problem is a sequential allocation task where the goal is to learn a policy that maximizes long term payoff, where only the reward of the executed action is observed; i.e., sequential optimal decisions are made, while simultaneously learning how the world operates. In the stochastic setting, the reward for each action is generated from an unknown distribution. To decide the next optimal action to take, one must compute sufficient statistics of this unknown reward distribution, e.g. upper-confidence bounds (UCB), or expectations in Thompson sampling. Closed-form expressions for these statistics of interest are analytically intractable except for simple cases. We here propose to leverage Monte Carlo estimation and, in particular, the flexibility of (sequential) importance sampling (IS) to allow for accurate estimation of the statistics of interest within the MAB problem. IS methods estimate posterior densities or expectations in probabilistic models that are analytically intractable. We first show how IS can be combined with state-of-the-art MAB algorithms (Thompson sampling and Bayes-UCB) for classic (Bernoulli and contextual linear-Gaussian) bandit problems. Furthermore, we leverage the power of sequential IS to extend the applicability of these algorithms beyond the classic settings, and tackle additional useful cases. Specifically, we study the dynamic linear-Gaussian bandit, and both the static and dynamic logistic cases too. The flexibility of (sequential) importance sampling is shown to be fundamental for obtaining efficient estimates of the key sufficient statistics in these challenging scenarios.
Nonparametric Gaussian mixture models for the multi-armed contextual bandit
Aug 08, 2018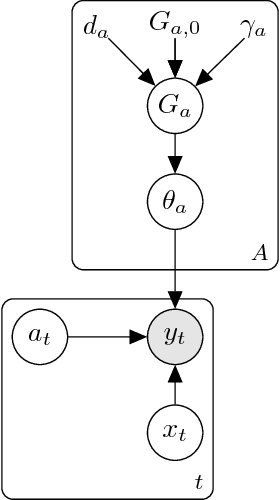


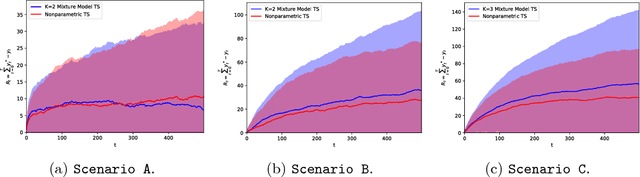
The multi-armed bandit is a sequential allocation task where an agent must learn a policy that maximizes long term payoff, where only the reward of the played arm is observed at each iteration. In the stochastic setting, the reward for each action is generated from an unknown distribution, which depends on a given 'context', available at each interaction with the world. Thompson sampling is a generative, interpretable multi-armed bandit algorithm that has been shown both to perform well in practice, and to enjoy optimality properties for certain reward functions. Nevertheless, Thompson sampling requires sampling from parameter posteriors and calculation of expected rewards, which are possible for a very limited choice of distributions. We here extend Thompson sampling to more complex scenarios by adopting a very flexible set of reward distributions: nonparametric Gaussian mixture models. The generative process of Bayesian nonparametric mixtures naturally aligns with the Bayesian modeling of multi-armed bandits. This allows for the implementation of an efficient and flexible Thompson sampling algorithm: the nonparametric model autonomously determines its complexity in an online fashion, as it observes new rewards for the played arms. We show how the proposed method sequentially learns the nonparametric mixture model that best approximates the true underlying reward distribution. Our contribution is valuable for practical scenarios, as it avoids stringent model specifications, and yet attains reduced regret.
Bayesian bandits: balancing the exploration-exploitation tradeoff via double sampling
Aug 08, 2018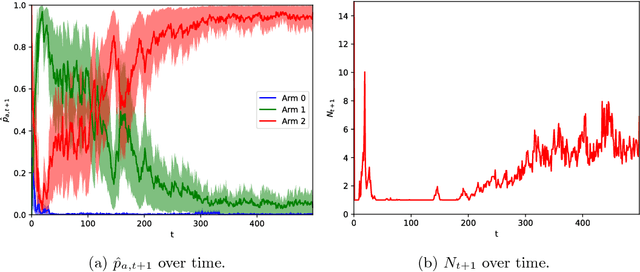
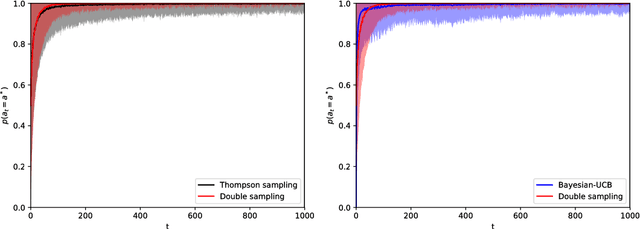

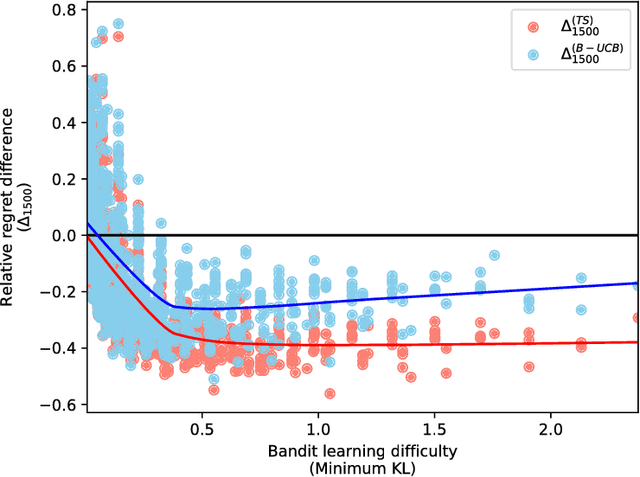
Reinforcement learning studies how to balance exploration and exploitation in real-world systems, optimizing interactions with the world while simultaneously learning how the world operates. One general class of algorithms for such learning is the multi-armed bandit setting. Randomized probability matching, based upon the Thompson sampling approach introduced in the 1930s, has recently been shown to perform well and to enjoy provable optimality properties. It permits generative, interpretable modeling in a Bayesian setting, where prior knowledge is incorporated, and the computed posteriors naturally capture the full state of knowledge. In this work, we harness the information contained in the Bayesian posterior and estimate its sufficient statistics via sampling. In several application domains, for example in health and medicine, each interaction with the world can be expensive and invasive, whereas drawing samples from the model is relatively inexpensive. Exploiting this viewpoint, we develop a double sampling technique driven by the uncertainty in the learning process: it favors exploitation when certain about the properties of each arm, exploring otherwise. The proposed algorithm does not make any distributional assumption and it is applicable to complex reward distributions, as long as Bayesian posterior updates are computable. Utilizing the estimated posterior sufficient statistics, double sampling autonomously balances the exploration-exploitation tradeoff to make better informed decisions. We empirically show its reduced cumulative regret when compared to state-of-the-art alternatives in representative bandit settings.
Variational inference for the multi-armed contextual bandit
Aug 08, 2018
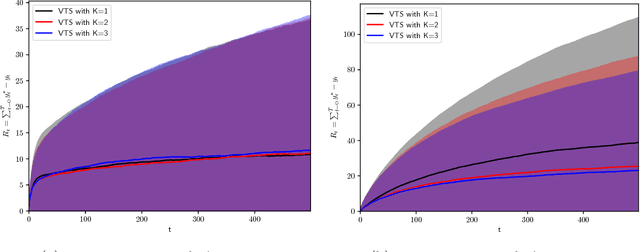
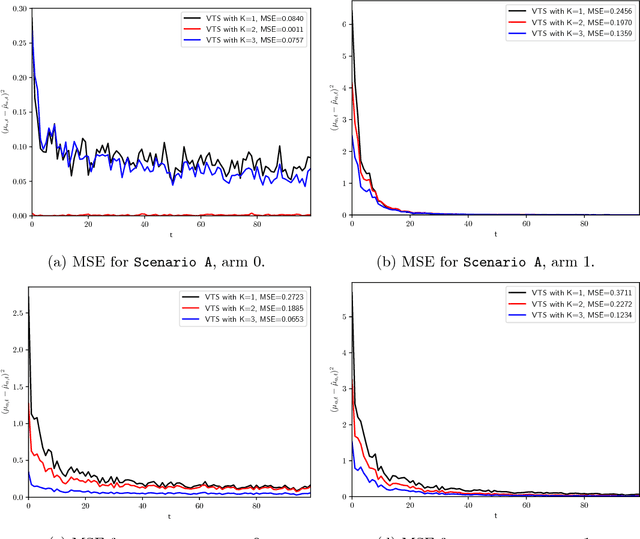
In many biomedical, science, and engineering problems, one must sequentially decide which action to take next so as to maximize rewards. One general class of algorithms for optimizing interactions with the world, while simultaneously learning how the world operates, is the multi-armed bandit setting and, in particular, the contextual bandit case. In this setting, for each executed action, one observes rewards that are dependent on a given 'context', available at each interaction with the world. The Thompson sampling algorithm has recently been shown to enjoy provable optimality properties for this set of problems, and to perform well in real-world settings. It facilitates generative and interpretable modeling of the problem at hand. Nevertheless, the design and complexity of the model limit its application, since one must both sample from the distributions modeled and calculate their expected rewards. We here show how these limitations can be overcome using variational inference to approximate complex models, applying to the reinforcement learning case advances developed for the inference case in the machine learning community over the past two decades. We consider contextual multi-armed bandit applications where the true reward distribution is unknown and complex, which we approximate with a mixture model whose parameters are inferred via variational inference. We show how the proposed variational Thompson sampling approach is accurate in approximating the true distribution, and attains reduced regrets even with complex reward distributions. The proposed algorithm is valuable for practical scenarios where restrictive modeling assumptions are undesirable.
* The software used for this study is publicly available at https://github.com/iurteaga/bandits
Stylistic Clusters and the Syrian/South Syrian Tradition of First-Millennium BCE Levantine Ivory Carving: A Machine Learning Approach
Jan 05, 2014
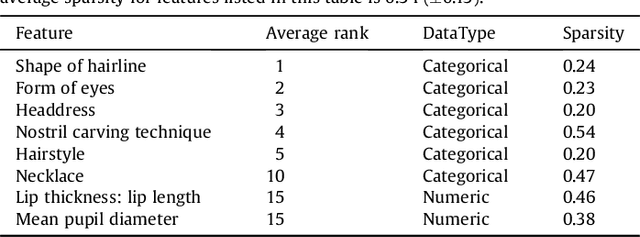


Thousands of first-millennium BCE ivory carvings have been excavated from Neo-Assyrian sites in Mesopotamia (primarily Nimrud, Khorsabad, and Arslan Tash) hundreds of miles from their Levantine production contexts. At present, their specific manufacture dates and workshop localities are unknown. Relying on subjective, visual methods, scholars have grappled with their classification and regional attribution for over a century. This study combines visual approaches with machine-learning techniques to offer data-driven perspectives on the classification and attribution of this early Iron Age corpus. The study sample consisted of 162 sculptures of female figures. We have developed an algorithm that clusters the ivories based on a combination of descriptive and anthropometric data. The resulting categories, which are based on purely statistical criteria, show good agreement with conventional art historical classifications, while revealing new perspectives, especially with regard to the contested Syrian/South Syrian/Intermediate tradition. Specifically, we have identified that objects of the Syrian/South Syrian/Intermediate tradition may be more closely related to Phoenician objects than to North Syrian objects; we offer a reconsideration of a subset of Phoenician objects, and we confirm Syrian/South Syrian/Intermediate stylistic subgroups that might distinguish networks of acquisition among the sites of Nimrud, Khorsabad, Arslan Tash and the Levant. We have also identified which features are most significant in our cluster assignments and might thereby be most diagnostic of regional carving traditions. In short, our study both corroborates traditional visual classification methods and demonstrates how machine-learning techniques may be employed to reveal complementary information not accessible through the exclusively visual analysis of an archaeological corpus.
Hierarchically-coupled hidden Markov models for learning kinetic rates from single-molecule data
May 15, 2013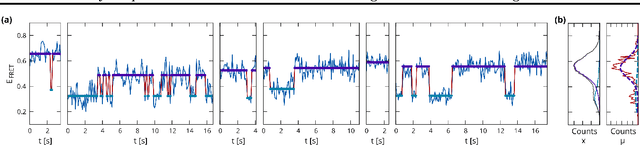
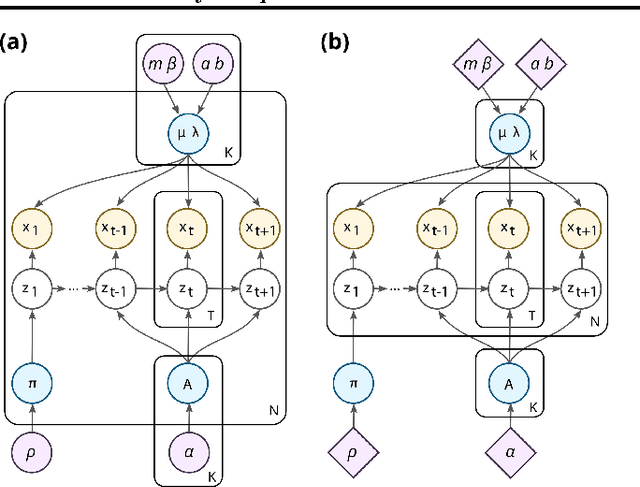
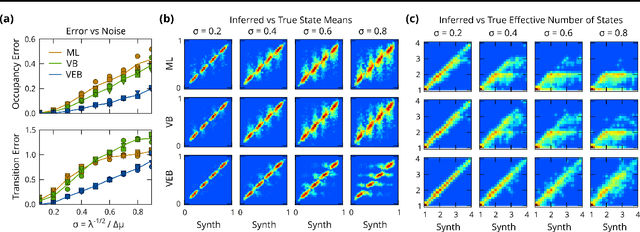
We address the problem of analyzing sets of noisy time-varying signals that all report on the same process but confound straightforward analyses due to complex inter-signal heterogeneities and measurement artifacts. In particular we consider single-molecule experiments which indirectly measure the distinct steps in a biomolecular process via observations of noisy time-dependent signals such as a fluorescence intensity or bead position. Straightforward hidden Markov model (HMM) analyses attempt to characterize such processes in terms of a set of conformational states, the transitions that can occur between these states, and the associated rates at which those transitions occur; but require ad-hoc post-processing steps to combine multiple signals. Here we develop a hierarchically coupled HMM that allows experimentalists to deal with inter-signal variability in a principled and automatic way. Our approach is a generalized expectation maximization hyperparameter point estimation procedure with variational Bayes at the level of individual time series that learns an single interpretable representation of the overall data generating process.
* 9 pages, 5 figures
An information-theoretic derivation of min-cut based clustering
Nov 26, 2008

Min-cut clustering, based on minimizing one of two heuristic cost-functions proposed by Shi and Malik, has spawned tremendous research, both analytic and algorithmic, in the graph partitioning and image segmentation communities over the last decade. It is however unclear if these heuristics can be derived from a more general principle facilitating generalization to new problem settings. Motivated by an existing graph partitioning framework, we derive relationships between optimizing relevance information, as defined in the Information Bottleneck method, and the regularized cut in a K-partitioned graph. For fast mixing graphs, we show that the cost functions introduced by Shi and Malik can be well approximated as the rate of loss of predictive information about the location of random walkers on the graph. For graphs generated from a stochastic algorithm designed to model community structure, the optimal information theoretic partition and the optimal min-cut partition are shown to be the same with high probability.
A non-negative expansion for small Jensen-Shannon Divergences
Oct 28, 2008

In this report, we derive a non-negative series expansion for the Jensen-Shannon divergence (JSD) between two probability distributions. This series expansion is shown to be useful for numerical calculations of the JSD, when the probability distributions are nearly equal, and for which, consequently, small numerical errors dominate evaluation.
Predicting Regional Classification of Levantine Ivory Sculptures: A Machine Learning Approach
Jun 28, 2008



Art historians and archaeologists have long grappled with the regional classification of ancient Near Eastern ivory carvings. Based on the visual similarity of sculptures, individuals within these fields have proposed object assemblages linked to hypothesized regional production centers. Using quantitative rather than visual methods, we here approach this classification task by exploiting computational methods from machine learning currently used with success in a variety of statistical problems in science and engineering. We first construct a prediction function using 66 categorical features as inputs and regional style as output. The model assigns regional style group (RSG), with 98 percent prediction accuracy. We then rank these features by their mutual information with RSG, quantifying single-feature predictive power. Using the highest- ranking features in combination with nomographic visualization, we have found previously unknown relationships that may aid in the regional classification of these ivories and their interpretation in art historical context.