 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational inference for the multi-armed contextual bandit
Paper and Code

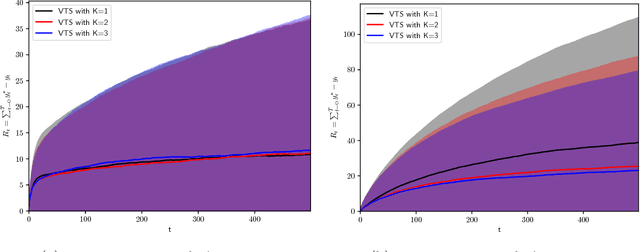
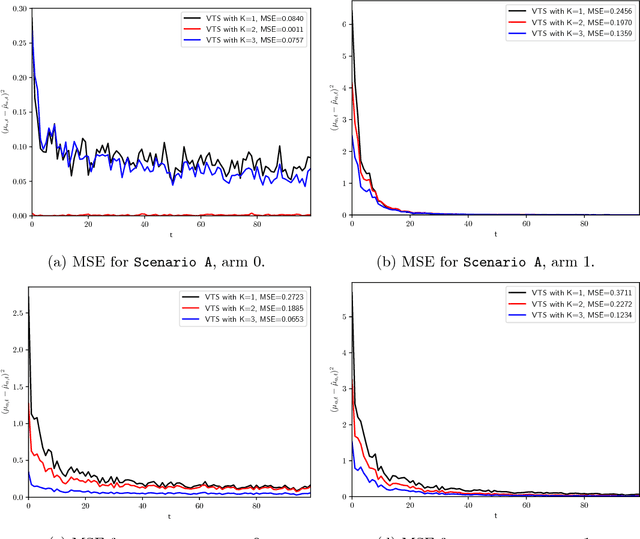
In many biomedical, science, and engineering problems, one must sequentially decide which action to take next so as to maximize rewards. One general class of algorithms for optimizing interactions with the world, while simultaneously learning how the world operates, is the multi-armed bandit setting and, in particular, the contextual bandit case. In this setting, for each executed action, one observes rewards that are dependent on a given 'context', available at each interaction with the world. The Thompson sampling algorithm has recently been shown to enjoy provable optimality properties for this set of problems, and to perform well in real-world settings. It facilitates generative and interpretable modeling of the problem at hand. Nevertheless, the design and complexity of the model limit its application, since one must both sample from the distributions modeled and calculate their expected rewards. We here show how these limitations can be overcome using variational inference to approximate complex models, applying to the reinforcement learning case advances developed for the inference case in the machine learning community over the past two decades. We consider contextual multi-armed bandit applications where the true reward distribution is unknown and complex, which we approximate with a mixture model whose parameters are inferred via variational inference. We show how the proposed variational Thompson sampling approach is accurate in approximating the true distribution, and attains reduced regrets even with complex reward distributions. The proposed algorithm is valuable for practical scenarios where restrictive modeling assumptions are undesirable.