 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing scalable strategies for generating numerical perspectives
Aug 03, 2023



Numerical perspectives help people understand extreme and unfamiliar numbers (e.g., \$330 billion is about \$1,000 per person in the United States). While research shows perspectives to be helpful, generating them at scale is challenging both because it is difficult to identify what makes some analogies more helpful than others, and because what is most helpful can vary based on the context in which a given number appears. Here we present and compare three policies for large-scale perspective generation: a rule-based approach, a crowdsourced system, and a model that uses Wikipedia data and semantic similarity (via BERT embeddings) to generate context-specific perspectives. We find that the combination of these three approaches dominates any single method, with different approaches excelling in different settings and users displaying heterogeneous preferences across approaches. We conclude by discussing our deployment of perspectives in a widely-used online word processor.
How good is good enough for COVID19 apps? The influence of benefits, accuracy, and privacy on willingness to adopt
May 18, 2020
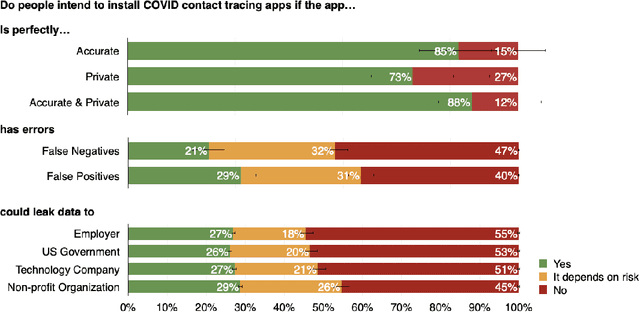
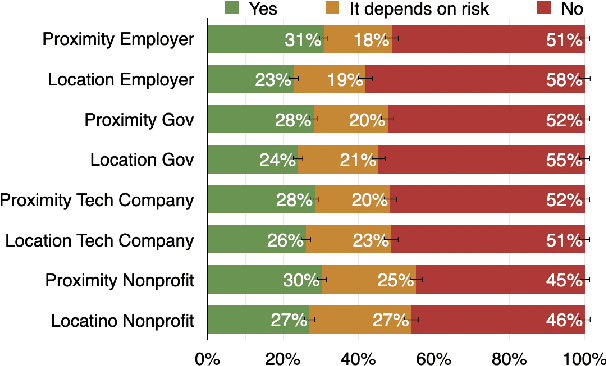
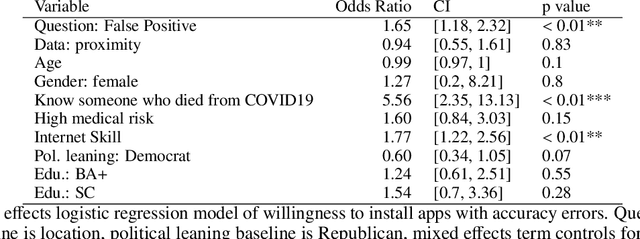
A growing number of contact tracing apps are being developed to complement manual contact tracing. A key question is whether users will be willing to adopt these contact tracing apps. In this work, we survey over 4,500 Americans to evaluate (1) the effect of both accuracy and privacy concerns on reported willingness to install COVID19 contact tracing apps and (2) how different groups of users weight accuracy vs. privacy. Drawing on our findings from these first two research questions, we (3) quantitatively model how the amount of public health benefit (reduction in infection rate), amount of individual benefit (true-positive detection of exposures to COVID), and degree of privacy risk in a hypothetical contact tracing app may influence American's willingness to install. Our work takes a descriptive ethics approach toward offering implications for the development of policy and app designs related to COVID19.
Manipulating and Measuring Model Interpretability
Sep 26, 2018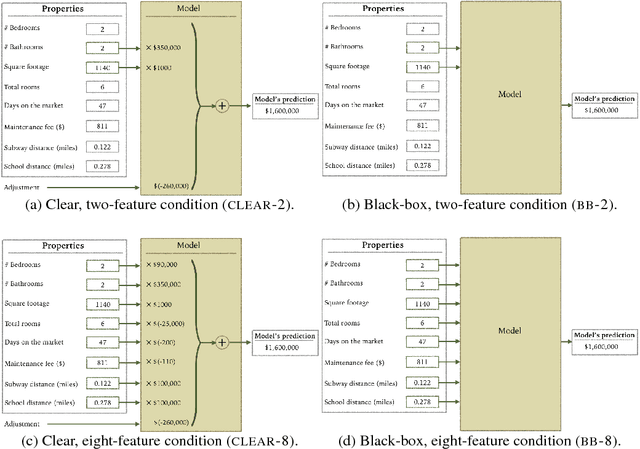

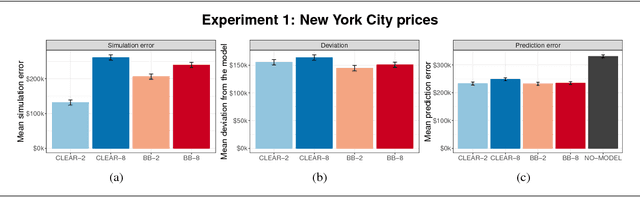
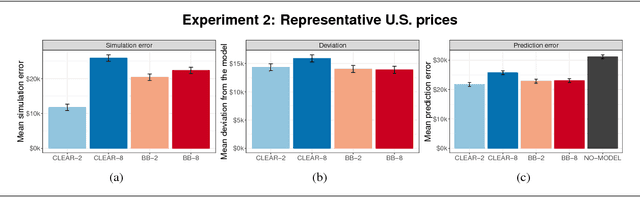
Despite a growing literature on creating interpretable machine learning methods, there have been few experimental studies of their effects on end users. We present a series of large-scale, randomized, pre-registered experiments in which participants were shown functionally identical models that varied only in two factors thought to influence interpretability: the number of input features and the model transparency (clear or black-box). Participants who were shown a clear model with a small number of features were better able to simulate the model's predictions. However, contrary to what one might expect when manipulating interpretability, we found no significant difference in multiple measures of trust across conditions. Even more surprisingly, increased transparency hampered people's ability to detect when a model has made a sizeable mistake. These findings emphasize the importance of studying how models are presented to people and empirically verifying that interpretable models achieve their intended effects on end users.
Simple rules for complex decisions
Apr 02, 2017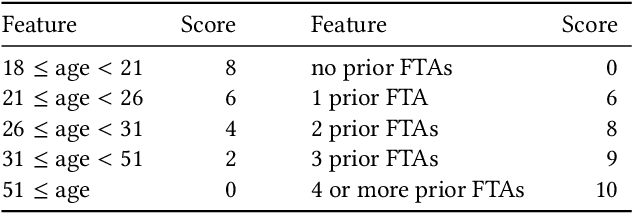
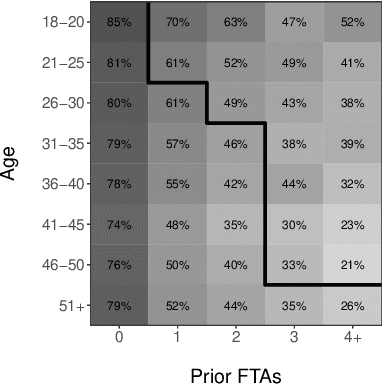
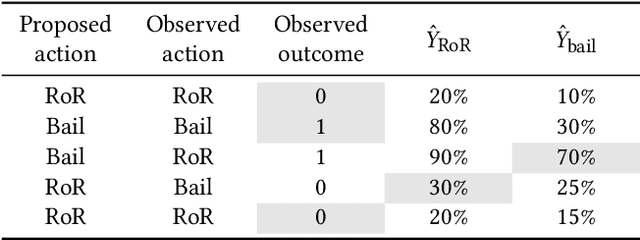
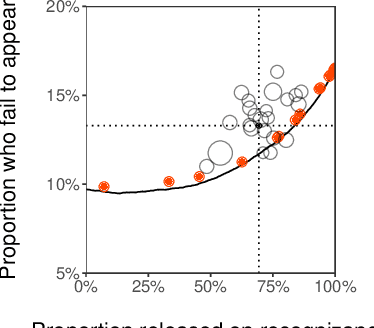
From doctors diagnosing patients to judges setting bail, experts often base their decisions on experience and intuition rather than on statistical models. While understandable, relying on intuition over models has often been found to result in inferior outcomes. Here we present a new method, select-regress-and-round, for constructing simple rules that perform well for complex decisions. These rules take the form of a weighted checklist, can be applied mentally, and nonetheless rival the performance of modern machine learning algorithms. Our method for creating these rules is itself simple, and can be carried out by practitioners with basic statistics knowledge. We demonstrate this technique with a detailed case study of judicial decisions to release or detain defendants while they await trial. In this application, as in many policy settings, the effects of proposed decision rules cannot be directly observed from historical data: if a rule recommends releasing a defendant that the judge in reality detained, we do not observe what would have happened under the proposed action. We address this key counterfactual estimation problem by drawing on tools from causal inference. We find that simple rules significantly outperform judges and are on par with decisions derived from random forests trained on all available features. Generalizing to 22 varied decision-making domains, we find this basic result replicates. We conclude with an analytical framework that helps explain why these simple decision rules perform as well as they do.