 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroducing v0.5 of the AI Safety Benchmark from MLCommons
Apr 18, 2024



This paper introduces v0.5 of the AI Safety Benchmark, which has been created by the MLCommons AI Safety Working Group. The AI Safety Benchmark has been designed to assess the safety risks of AI systems that use chat-tuned language models. We introduce a principled approach to specifying and constructing the benchmark, which for v0.5 covers only a single use case (an adult chatting to a general-purpose assistant in English), and a limited set of personas (i.e., typical users, malicious users, and vulnerable users). We created a new taxonomy of 13 hazard categories, of which 7 have tests in the v0.5 benchmark. We plan to release version 1.0 of the AI Safety Benchmark by the end of 2024. The v1.0 benchmark will provide meaningful insights into the safety of AI systems. However, the v0.5 benchmark should not be used to assess the safety of AI systems. We have sought to fully document the limitations, flaws, and challenges of v0.5. This release of v0.5 of the AI Safety Benchmark includes (1) a principled approach to specifying and constructing the benchmark, which comprises use cases, types of systems under test (SUTs), language and context, personas, tests, and test items; (2) a taxonomy of 13 hazard categories with definitions and subcategories; (3) tests for seven of the hazard categories, each comprising a unique set of test items, i.e., prompts. There are 43,090 test items in total, which we created with templates; (4) a grading system for AI systems against the benchmark; (5) an openly available platform, and downloadable tool, called ModelBench that can be used to evaluate the safety of AI systems on the benchmark; (6) an example evaluation report which benchmarks the performance of over a dozen openly available chat-tuned language models; (7) a test specification for the benchmark.
Aligning Offline Metrics and Human Judgments of Value of AI-Pair Programmers
Oct 29, 2022Large language models trained on massive amounts of natural language data and code have shown impressive capabilities in automatic code generation scenarios. Development and evaluation of these models has largely been driven by offline functional correctness metrics, which consider a task to be solved if the generated code passes corresponding unit tests. While functional correctness is clearly an important property of a code generation model, we argue that it may not fully capture what programmers value when collaborating with their AI pair programmers. For example, while a nearly correct suggestion that does not consider edge cases may fail a unit test, it may still provide a substantial starting point or hint to the programmer, thereby reducing total needed effort to complete a coding task. To investigate this, we conduct a user study with (N=49) experienced programmers, and find that while both correctness and effort correlate with value, the association is strongest for effort. We argue that effort should be considered as an important dimension of evaluation in code generation scenarios. We also find that functional correctness remains better at identifying the highest-value generations; but participants still saw considerable value in code that failed unit tests. Conversely, similarity-based metrics are very good at identifying the lowest-value generations among those that fail unit tests. Based on these findings, we propose a simple hybrid metric, which combines functional correctness and similarity-based metrics to capture different dimensions of what programmers might value and show that this hybrid metric more strongly correlates with both value and effort. Our findings emphasize the importance of designing human-centered metrics that capture what programmers need from and value in their AI pair programmers.
Manipulating and Measuring Model Interpretability
Sep 26, 2018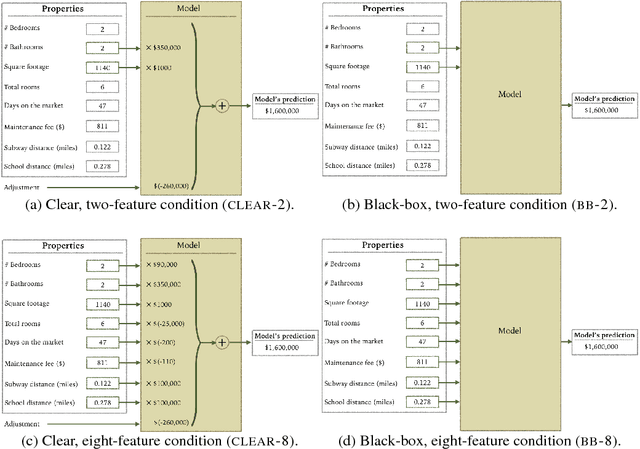

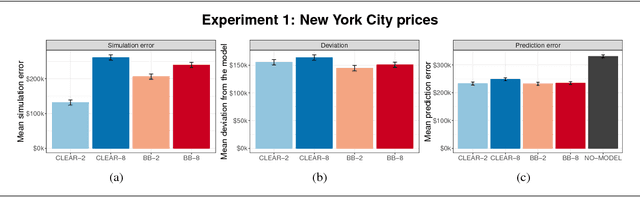
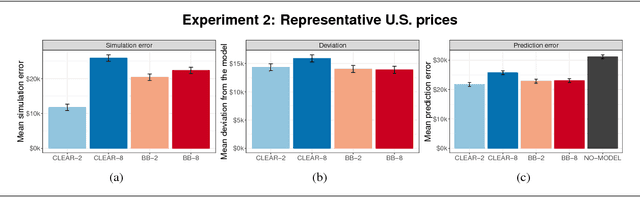
Despite a growing literature on creating interpretable machine learning methods, there have been few experimental studies of their effects on end users. We present a series of large-scale, randomized, pre-registered experiments in which participants were shown functionally identical models that varied only in two factors thought to influence interpretability: the number of input features and the model transparency (clear or black-box). Participants who were shown a clear model with a small number of features were better able to simulate the model's predictions. However, contrary to what one might expect when manipulating interpretability, we found no significant difference in multiple measures of trust across conditions. Even more surprisingly, increased transparency hampered people's ability to detect when a model has made a sizeable mistake. These findings emphasize the importance of studying how models are presented to people and empirically verifying that interpretable models achieve their intended effects on end users.