 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFostering Appropriate Reliance on Large Language Models: The Role of Explanations, Sources, and Inconsistencies
Feb 12, 2025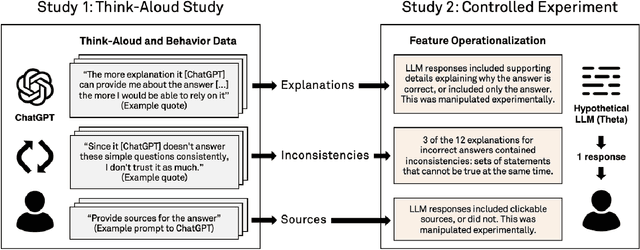
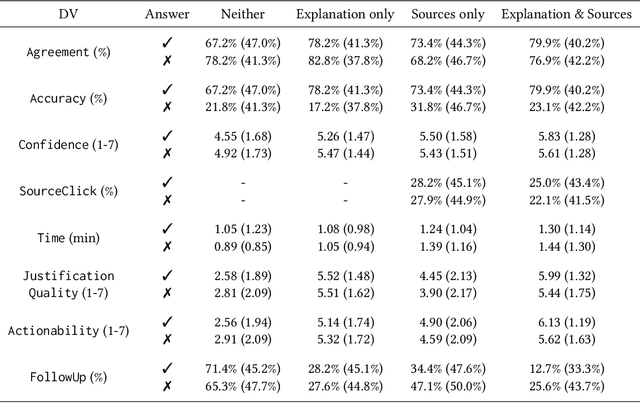
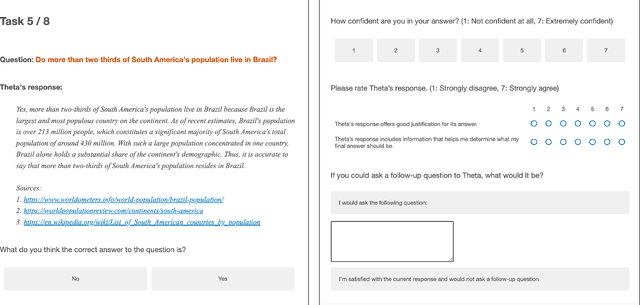

Large language models (LLMs) can produce erroneous responses that sound fluent and convincing, raising the risk that users will rely on these responses as if they were correct. Mitigating such overreliance is a key challenge. Through a think-aloud study in which participants use an LLM-infused application to answer objective questions, we identify several features of LLM responses that shape users' reliance: explanations (supporting details for answers), inconsistencies in explanations, and sources. Through a large-scale, pre-registered, controlled experiment (N=308), we isolate and study the effects of these features on users' reliance, accuracy, and other measures. We find that the presence of explanations increases reliance on both correct and incorrect responses. However, we observe less reliance on incorrect responses when sources are provided or when explanations exhibit inconsistencies. We discuss the implications of these findings for fostering appropriate reliance on LLMs.
Machine Unlearning Doesn't Do What You Think: Lessons for Generative AI Policy, Research, and Practice
Dec 09, 2024



We articulate fundamental mismatches between technical methods for machine unlearning in Generative AI, and documented aspirations for broader impact that these methods could have for law and policy. These aspirations are both numerous and varied, motivated by issues that pertain to privacy, copyright, safety, and more. For example, unlearning is often invoked as a solution for removing the effects of targeted information from a generative-AI model's parameters, e.g., a particular individual's personal data or in-copyright expression of Spiderman that was included in the model's training data. Unlearning is also proposed as a way to prevent a model from generating targeted types of information in its outputs, e.g., generations that closely resemble a particular individual's data or reflect the concept of "Spiderman." Both of these goals--the targeted removal of information from a model and the targeted suppression of information from a model's outputs--present various technical and substantive challenges. We provide a framework for thinking rigorously about these challenges, which enables us to be clear about why unlearning is not a general-purpose solution for circumscribing generative-AI model behavior in service of broader positive impact. We aim for conceptual clarity and to encourage more thoughtful communication among machine learning (ML), law, and policy experts who seek to develop and apply technical methods for compliance with policy objectives.
"I'm Not Sure, But": Examining the Impact of Large Language Models' Uncertainty Expression on User Reliance and Trust
May 01, 2024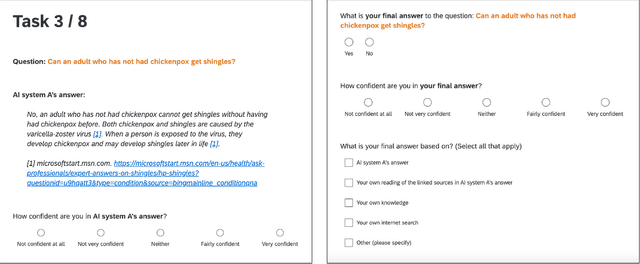
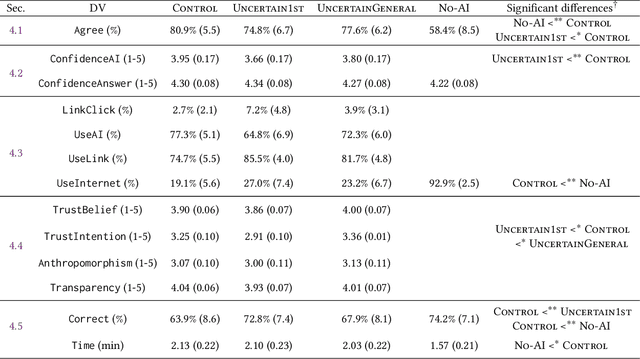
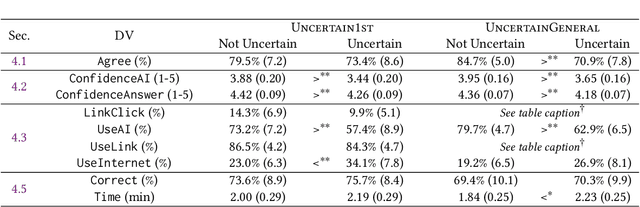
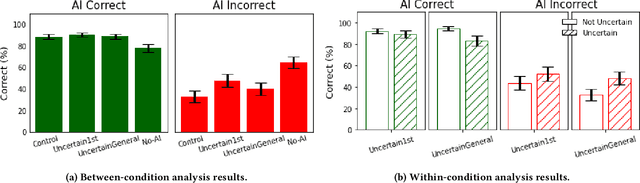
Widely deployed large language models (LLMs) can produce convincing yet incorrect outputs, potentially misleading users who may rely on them as if they were correct. To reduce such overreliance, there have been calls for LLMs to communicate their uncertainty to end users. However, there has been little empirical work examining how users perceive and act upon LLMs' expressions of uncertainty. We explore this question through a large-scale, pre-registered, human-subject experiment (N=404) in which participants answer medical questions with or without access to responses from a fictional LLM-infused search engine. Using both behavioral and self-reported measures, we examine how different natural language expressions of uncertainty impact participants' reliance, trust, and overall task performance. We find that first-person expressions (e.g., "I'm not sure, but...") decrease participants' confidence in the system and tendency to agree with the system's answers, while increasing participants' accuracy. An exploratory analysis suggests that this increase can be attributed to reduced (but not fully eliminated) overreliance on incorrect answers. While we observe similar effects for uncertainty expressed from a general perspective (e.g., "It's not clear, but..."), these effects are weaker and not statistically significant. Our findings suggest that using natural language expressions of uncertainty may be an effective approach for reducing overreliance on LLMs, but that the precise language used matters. This highlights the importance of user testing before deploying LLMs at scale.
Open Datasheets: Machine-readable Documentation for Open Datasets and Responsible AI Assessments
Dec 11, 2023
This paper introduces a no-code, machine-readable documentation framework for open datasets, with a focus on Responsible AI (RAI) considerations. The framework aims to improve the accessibility, comprehensibility, and usability of open datasets, facilitating easier discovery and use, better understanding of content and context, and evaluation of dataset quality and accuracy. The proposed framework is designed to streamline the evaluation of datasets, helping researchers, data scientists, and other open data users quickly identify datasets that meet their needs and/or organizational policies or regulations. The paper also discusses the implementation of the framework and provides recommendations to maximize its potential. The framework is expected to enhance the quality and reliability of data used in research and decision-making, fostering the development of more responsible and trustworthy AI systems.
Has the Machine Learning Review Process Become More Arbitrary as the Field Has Grown? The NeurIPS 2021 Consistency Experiment
Jun 05, 2023
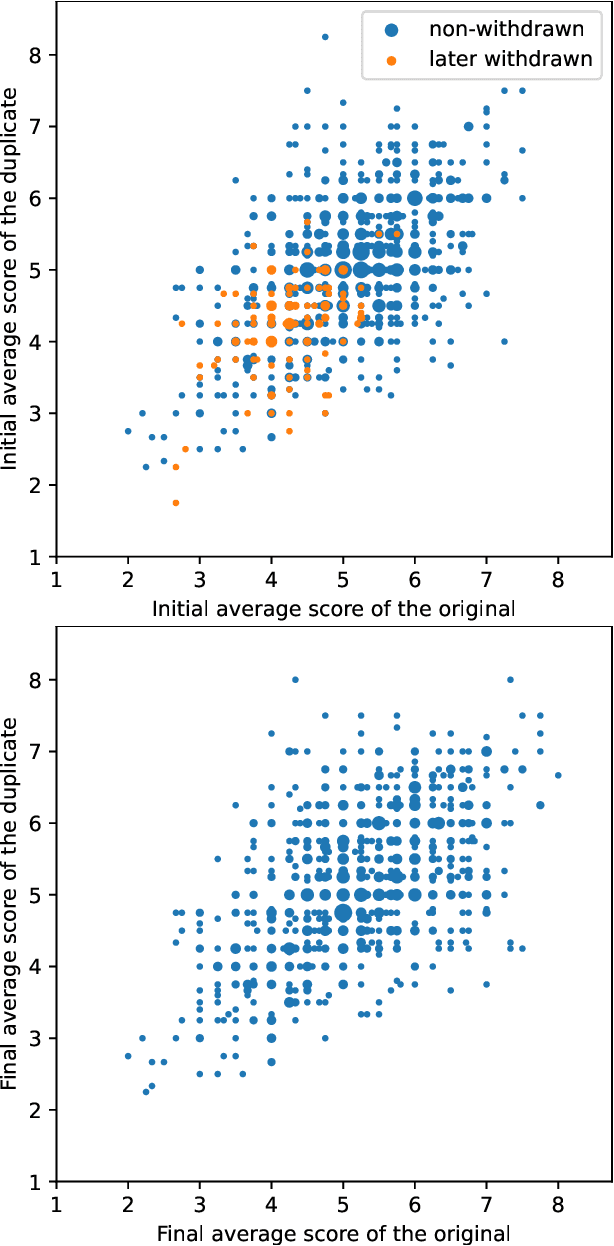
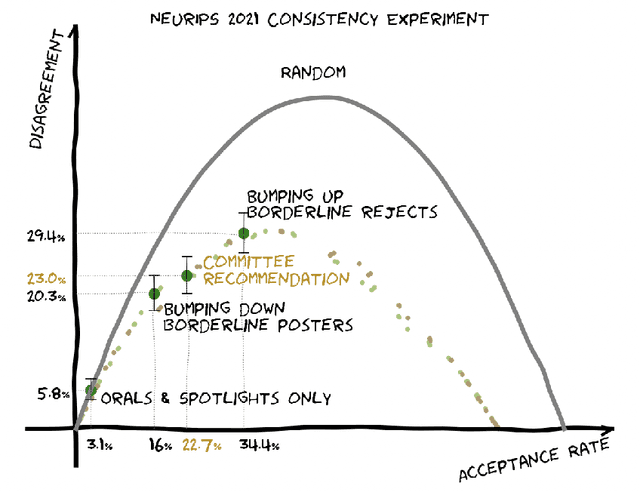
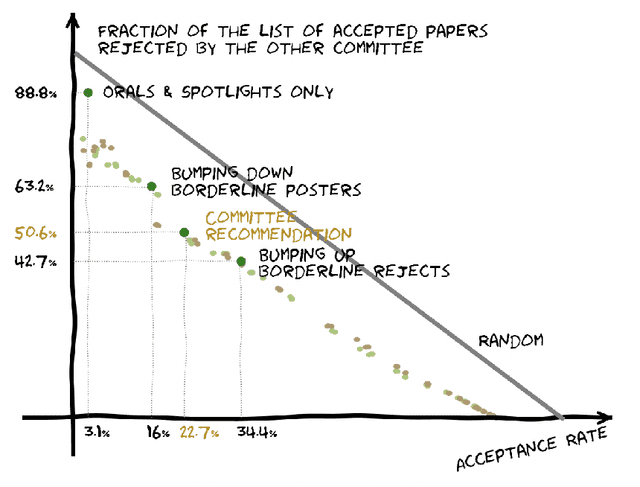
We present the NeurIPS 2021 consistency experiment, a larger-scale variant of the 2014 NeurIPS experiment in which 10% of conference submissions were reviewed by two independent committees to quantify the randomness in the review process. We observe that the two committees disagree on their accept/reject recommendations for 23% of the papers and that, consistent with the results from 2014, approximately half of the list of accepted papers would change if the review process were randomly rerun. Our analysis suggests that making the conference more selective would increase the arbitrariness of the process. Taken together with previous research, our results highlight the inherent difficulty of objectively measuring the quality of research, and suggest that authors should not be excessively discouraged by rejected work.
AI Transparency in the Age of LLMs: A Human-Centered Research Roadmap
Jun 02, 2023
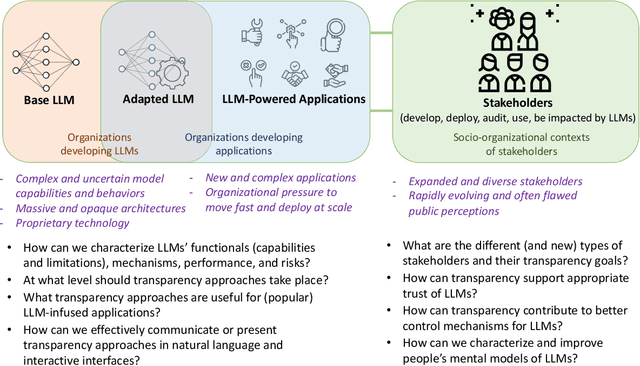
The rise of powerful large language models (LLMs) brings about tremendous opportunities for innovation but also looming risks for individuals and society at large. We have reached a pivotal moment for ensuring that LLMs and LLM-infused applications are developed and deployed responsibly. However, a central pillar of responsible AI -- transparency -- is largely missing from the current discourse around LLMs. It is paramount to pursue new approaches to provide transparency for LLMs, and years of research at the intersection of AI and human-computer interaction (HCI) highlight that we must do so with a human-centered perspective: Transparency is fundamentally about supporting appropriate human understanding, and this understanding is sought by different stakeholders with different goals in different contexts. In this new era of LLMs, we must develop and design approaches to transparency by considering the needs of stakeholders in the emerging LLM ecosystem, the novel types of LLM-infused applications being built, and the new usage patterns and challenges around LLMs, all while building on lessons learned about how people process, interact with, and make use of information. We reflect on the unique challenges that arise in providing transparency for LLMs, along with lessons learned from HCI and responsible AI research that has taken a human-centered perspective on AI transparency. We then lay out four common approaches that the community has taken to achieve transparency -- model reporting, publishing evaluation results, providing explanations, and communicating uncertainty -- and call out open questions around how these approaches may or may not be applied to LLMs. We hope this provides a starting point for discussion and a useful roadmap for future research.
GAM Coach: Towards Interactive and User-centered Algorithmic Recourse
Mar 01, 2023



Machine learning (ML) recourse techniques are increasingly used in high-stakes domains, providing end users with actions to alter ML predictions, but they assume ML developers understand what input variables can be changed. However, a recourse plan's actionability is subjective and unlikely to match developers' expectations completely. We present GAM Coach, a novel open-source system that adapts integer linear programming to generate customizable counterfactual explanations for Generalized Additive Models (GAMs), and leverages interactive visualizations to enable end users to iteratively generate recourse plans meeting their needs. A quantitative user study with 41 participants shows our tool is usable and useful, and users prefer personalized recourse plans over generic plans. Through a log analysis, we explore how users discover satisfactory recourse plans, and provide empirical evidence that transparency can lead to more opportunities for everyday users to discover counterintuitive patterns in ML models. GAM Coach is available at: https://poloclub.github.io/gam-coach/.
Designerly Understanding: Information Needs for Model Transparency to Support Design Ideation for AI-Powered User Experience
Feb 21, 2023

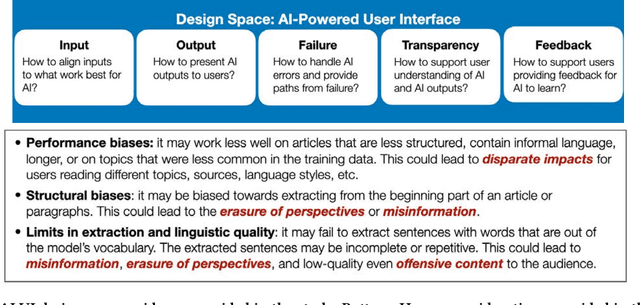

Despite the widespread use of artificial intelligence (AI), designing user experiences (UX) for AI-powered systems remains challenging. UX designers face hurdles understanding AI technologies, such as pre-trained language models, as design materials. This limits their ability to ideate and make decisions about whether, where, and how to use AI. To address this problem, we bridge the literature on AI design and AI transparency to explore whether and how frameworks for transparent model reporting can support design ideation with pre-trained models. By interviewing 23 UX practitioners, we find that practitioners frequently work with pre-trained models, but lack support for UX-led ideation. Through a scenario-based design task, we identify common goals that designers seek model understanding for and pinpoint their model transparency information needs. Our study highlights the pivotal role that UX designers can play in Responsible AI and calls for supporting their understanding of AI limitations through model transparency and interrogation.
Generation Probabilities Are Not Enough: Exploring the Effectiveness of Uncertainty Highlighting in AI-Powered Code Completions
Feb 14, 2023



Large-scale generative models enabled the development of AI-powered code completion tools to assist programmers in writing code. However, much like other AI-powered tools, AI-powered code completions are not always accurate, potentially introducing bugs or even security vulnerabilities into code if not properly detected and corrected by a human programmer. One technique that has been proposed and implemented to help programmers identify potential errors is to highlight uncertain tokens. However, there have been no empirical studies exploring the effectiveness of this technique-- nor investigating the different and not-yet-agreed-upon notions of uncertainty in the context of generative models. We explore the question of whether conveying information about uncertainty enables programmers to more quickly and accurately produce code when collaborating with an AI-powered code completion tool, and if so, what measure of uncertainty best fits programmers' needs. Through a mixed-methods study with 30 programmers, we compare three conditions: providing the AI system's code completion alone, highlighting tokens with the lowest likelihood of being generated by the underlying generative model, and highlighting tokens with the highest predicted likelihood of being edited by a programmer. We find that highlighting tokens with the highest predicted likelihood of being edited leads to faster task completion and more targeted edits, and is subjectively preferred by study participants. In contrast, highlighting tokens according to their probability of being generated does not provide any benefit over the baseline with no highlighting. We further explore the design space of how to convey uncertainty in AI-powered code completion tools, and find that programmers prefer highlights that are granular, informative, interpretable, and not overwhelming.
Understanding the Role of Human Intuition on Reliance in Human-AI Decision-Making with Explanations
Jan 18, 2023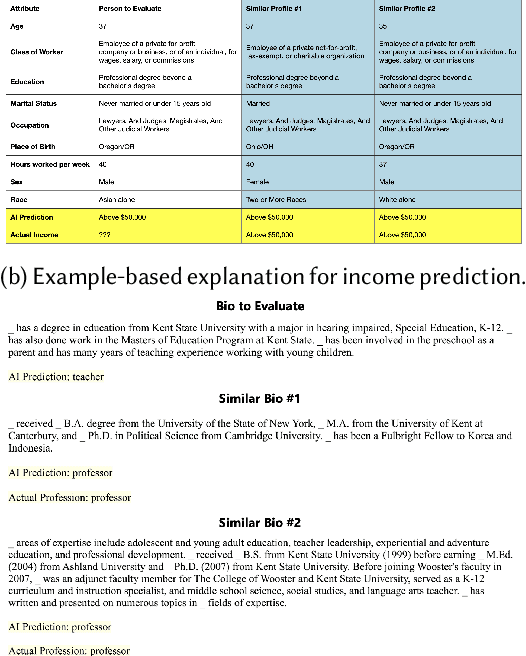
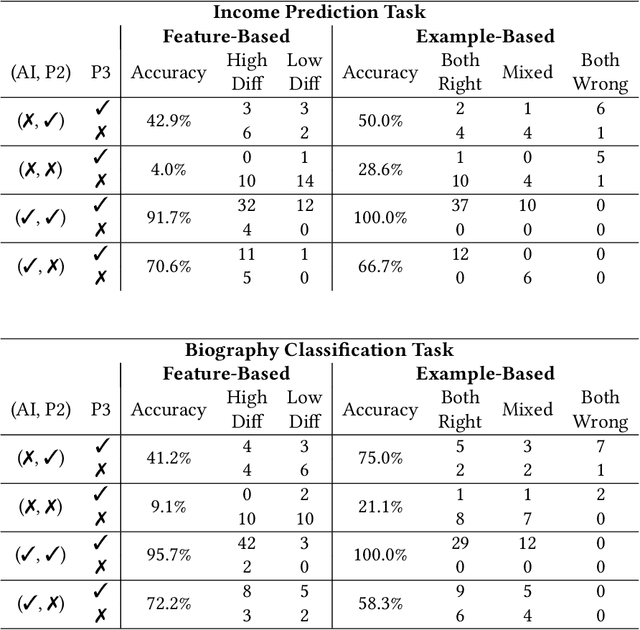
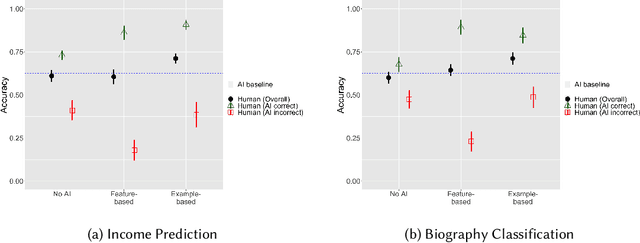
AI explanations are often mentioned as a way to improve human-AI decision-making. Yet, empirical studies have not found consistent evidence of explanations' effectiveness and, on the contrary, suggest that they can increase overreliance when the AI system is wrong. While many factors may affect reliance on AI support, one important factor is how decision-makers reconcile their own intuition -- which may be based on domain knowledge, prior task experience, or pattern recognition -- with the information provided by the AI system to determine when to override AI predictions. We conduct a think-aloud, mixed-methods study with two explanation types (feature- and example-based) for two prediction tasks to explore how decision-makers' intuition affects their use of AI predictions and explanations, and ultimately their choice of when to rely on AI. Our results identify three types of intuition involved in reasoning about AI predictions and explanations: intuition about the task outcome, features, and AI limitations. Building on these, we summarize three observed pathways for decision-makers to apply their own intuition and override AI predictions. We use these pathways to explain why (1) the feature-based explanations we used did not improve participants' decision outcomes and increased their overreliance on AI, and (2) the example-based explanations we used improved decision-makers' performance over feature-based explanations and helped achieve complementary human-AI performance. Overall, our work identifies directions for further development of AI decision-support systems and explanation methods that help decision-makers effectively apply their intuition to achieve appropriate reliance on AI.