 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison requires valid measurement: Rethinking attack success rate comparisons in AI red teaming
Jan 26, 2026We argue that conclusions drawn about relative system safety or attack method efficacy via AI red teaming are often not supported by evidence provided by attack success rate (ASR) comparisons. We show, through conceptual, theoretical, and empirical contributions, that many conclusions are founded on apples-to-oranges comparisons or low-validity measurements. Our arguments are grounded in asking a simple question: When can attack success rates be meaningfully compared? To answer this question, we draw on ideas from social science measurement theory and inferential statistics, which, taken together, provide a conceptual grounding for understanding when numerical values obtained through the quantification of system attributes can be meaningfully compared. Through this lens, we articulate conditions under which ASRs can and cannot be meaningfully compared. Using jailbreaking as a running example, we provide examples and extensive discussion of apples-to-oranges ASR comparisons and measurement validity challenges.
Extracting books from production language models
Jan 06, 2026Many unresolved legal questions over LLMs and copyright center on memorization: whether specific training data have been encoded in the model's weights during training, and whether those memorized data can be extracted in the model's outputs. While many believe that LLMs do not memorize much of their training data, recent work shows that substantial amounts of copyrighted text can be extracted from open-weight models. However, it remains an open question if similar extraction is feasible for production LLMs, given the safety measures these systems implement. We investigate this question using a two-phase procedure: (1) an initial probe to test for extraction feasibility, which sometimes uses a Best-of-N (BoN) jailbreak, followed by (2) iterative continuation prompts to attempt to extract the book. We evaluate our procedure on four production LLMs -- Claude 3.7 Sonnet, GPT-4.1, Gemini 2.5 Pro, and Grok 3 -- and we measure extraction success with a score computed from a block-based approximation of longest common substring (nv-recall). With different per-LLM experimental configurations, we were able to extract varying amounts of text. For the Phase 1 probe, it was unnecessary to jailbreak Gemini 2.5 Pro and Grok 3 to extract text (e.g, nv-recall of 76.8% and 70.3%, respectively, for Harry Potter and the Sorcerer's Stone), while it was necessary for Claude 3.7 Sonnet and GPT-4.1. In some cases, jailbroken Claude 3.7 Sonnet outputs entire books near-verbatim (e.g., nv-recall=95.8%). GPT-4.1 requires significantly more BoN attempts (e.g., 20X), and eventually refuses to continue (e.g., nv-recall=4.0%). Taken together, our work highlights that, even with model- and system-level safeguards, extraction of (in-copyright) training data remains a risk for production LLMs.
The Common Pile v0.1: An 8TB Dataset of Public Domain and Openly Licensed Text
Jun 05, 2025Large language models (LLMs) are typically trained on enormous quantities of unlicensed text, a practice that has led to scrutiny due to possible intellectual property infringement and ethical concerns. Training LLMs on openly licensed text presents a first step towards addressing these issues, but prior data collection efforts have yielded datasets too small or low-quality to produce performant LLMs. To address this gap, we collect, curate, and release the Common Pile v0.1, an eight terabyte collection of openly licensed text designed for LLM pretraining. The Common Pile comprises content from 30 sources that span diverse domains including research papers, code, books, encyclopedias, educational materials, audio transcripts, and more. Crucially, we validate our efforts by training two 7 billion parameter LLMs on text from the Common Pile: Comma v0.1-1T and Comma v0.1-2T, trained on 1 and 2 trillion tokens respectively. Both models attain competitive performance to LLMs trained on unlicensed text with similar computational budgets, such as Llama 1 and 2 7B. In addition to releasing the Common Pile v0.1 itself, we also release the code used in its creation as well as the training mixture and checkpoints for the Comma v0.1 models.
Strong Membership Inference Attacks on Massive Datasets and (Moderately) Large Language Models
May 24, 2025State-of-the-art membership inference attacks (MIAs) typically require training many reference models, making it difficult to scale these attacks to large pre-trained language models (LLMs). As a result, prior research has either relied on weaker attacks that avoid training reference models (e.g., fine-tuning attacks), or on stronger attacks applied to small-scale models and datasets. However, weaker attacks have been shown to be brittle - achieving close-to-arbitrary success - and insights from strong attacks in simplified settings do not translate to today's LLMs. These challenges have prompted an important question: are the limitations observed in prior work due to attack design choices, or are MIAs fundamentally ineffective on LLMs? We address this question by scaling LiRA - one of the strongest MIAs - to GPT-2 architectures ranging from 10M to 1B parameters, training reference models on over 20B tokens from the C4 dataset. Our results advance the understanding of MIAs on LLMs in three key ways: (1) strong MIAs can succeed on pre-trained LLMs; (2) their effectiveness, however, remains limited (e.g., AUC<0.7) in practical settings; and, (3) the relationship between MIA success and related privacy metrics is not as straightforward as prior work has suggested.
Extracting memorized pieces of (copyrighted) books from open-weight language models
May 18, 2025Plaintiffs and defendants in copyright lawsuits over generative AI often make sweeping, opposing claims about the extent to which large language models (LLMs) have memorized plaintiffs' protected expression. Drawing on adversarial ML and copyright law, we show that these polarized positions dramatically oversimplify the relationship between memorization and copyright. To do so, we leverage a recent probabilistic extraction technique to extract pieces of the Books3 dataset from 13 open-weight LLMs. Through numerous experiments, we show that it's possible to extract substantial parts of at least some books from different LLMs. This is evidence that the LLMs have memorized the extracted text; this memorized content is copied inside the model parameters. But the results are complicated: the extent of memorization varies both by model and by book. With our specific experiments, we find that the largest LLMs don't memorize most books -- either in whole or in part. However, we also find that Llama 3.1 70B memorizes some books, like Harry Potter and 1984, almost entirely. We discuss why our results have significant implications for copyright cases, though not ones that unambiguously favor either side.
Machine Unlearning Doesn't Do What You Think: Lessons for Generative AI Policy, Research, and Practice
Dec 09, 2024



We articulate fundamental mismatches between technical methods for machine unlearning in Generative AI, and documented aspirations for broader impact that these methods could have for law and policy. These aspirations are both numerous and varied, motivated by issues that pertain to privacy, copyright, safety, and more. For example, unlearning is often invoked as a solution for removing the effects of targeted information from a generative-AI model's parameters, e.g., a particular individual's personal data or in-copyright expression of Spiderman that was included in the model's training data. Unlearning is also proposed as a way to prevent a model from generating targeted types of information in its outputs, e.g., generations that closely resemble a particular individual's data or reflect the concept of "Spiderman." Both of these goals--the targeted removal of information from a model and the targeted suppression of information from a model's outputs--present various technical and substantive challenges. We provide a framework for thinking rigorously about these challenges, which enables us to be clear about why unlearning is not a general-purpose solution for circumscribing generative-AI model behavior in service of broader positive impact. We aim for conceptual clarity and to encourage more thoughtful communication among machine learning (ML), law, and policy experts who seek to develop and apply technical methods for compliance with policy objectives.
Between Randomness and Arbitrariness: Some Lessons for Reliable Machine Learning at Scale
Jun 13, 2024To develop rigorous knowledge about ML models -- and the systems in which they are embedded -- we need reliable measurements. But reliable measurement is fundamentally challenging, and touches on issues of reproducibility, scalability, uncertainty quantification, epistemology, and more. This dissertation addresses criteria needed to take reliability seriously: both criteria for designing meaningful metrics, and for methodologies that ensure that we can dependably and efficiently measure these metrics at scale and in practice. In doing so, this dissertation articulates a research vision for a new field of scholarship at the intersection of machine learning, law, and policy. Within this frame, we cover topics that fit under three different themes: (1) quantifying and mitigating sources of arbitrariness in ML, (2) taming randomness in uncertainty estimation and optimization algorithms, in order to achieve scalability without sacrificing reliability, and (3) providing methods for evaluating generative-AI systems, with specific focuses on quantifying memorization in language models and training latent diffusion models on open-licensed data. By making contributions in these three themes, this dissertation serves as an empirical proof by example that research on reliable measurement for machine learning is intimately and inescapably bound up with research in law and policy. These different disciplines pose similar research questions about reliable measurement in machine learning. They are, in fact, two complementary sides of the same research vision, which, broadly construed, aims to construct machine-learning systems that cohere with broader societal values.
On the Standardization of Behavioral Use Clauses and Their Adoption for Responsible Licensing of AI
Feb 07, 2024Growing concerns over negligent or malicious uses of AI have increased the appetite for tools that help manage the risks of the technology. In 2018, licenses with behaviorial-use clauses (commonly referred to as Responsible AI Licenses) were proposed to give developers a framework for releasing AI assets while specifying their users to mitigate negative applications. As of the end of 2023, on the order of 40,000 software and model repositories have adopted responsible AI licenses licenses. Notable models licensed with behavioral use clauses include BLOOM (language) and LLaMA2 (language), Stable Diffusion (image), and GRID (robotics). This paper explores why and how these licenses have been adopted, and why and how they have been adapted to fit particular use cases. We use a mixed-methods methodology of qualitative interviews, clustering of license clauses, and quantitative analysis of license adoption. Based on this evidence we take the position that responsible AI licenses need standardization to avoid confusing users or diluting their impact. At the same time, customization of behavioral restrictions is also appropriate in some contexts (e.g., medical domains). We advocate for ``standardized customization'' that can meet users' needs and can be supported via tooling.
Scalable Extraction of Training Data from (Production) Language Models
Nov 28, 2023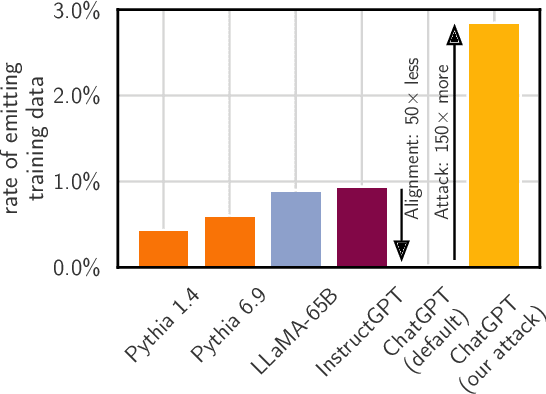
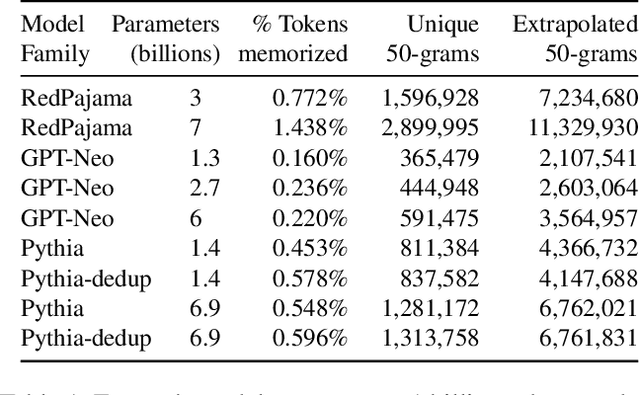
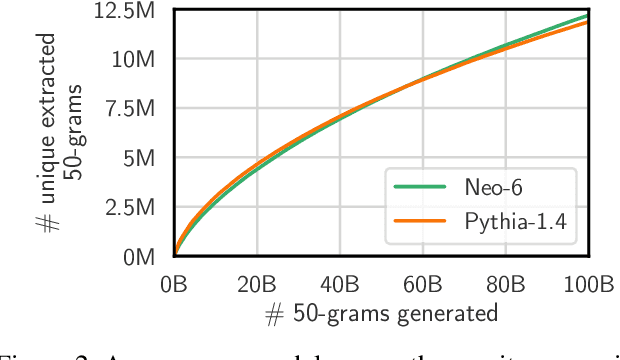

This paper studies extractable memorization: training data that an adversary can efficiently extract by querying a machine learning model without prior knowledge of the training dataset. We show an adversary can extract gigabytes of training data from open-source language models like Pythia or GPT-Neo, semi-open models like LLaMA or Falcon, and closed models like ChatGPT. Existing techniques from the literature suffice to attack unaligned models; in order to attack the aligned ChatGPT, we develop a new divergence attack that causes the model to diverge from its chatbot-style generations and emit training data at a rate 150x higher than when behaving properly. Our methods show practical attacks can recover far more data than previously thought, and reveal that current alignment techniques do not eliminate memorization.
CommonCanvas: An Open Diffusion Model Trained with Creative-Commons Images
Oct 25, 2023



We assemble a dataset of Creative-Commons-licensed (CC) images, which we use to train a set of open diffusion models that are qualitatively competitive with Stable Diffusion 2 (SD2). This task presents two challenges: (1) high-resolution CC images lack the captions necessary to train text-to-image generative models; (2) CC images are relatively scarce. In turn, to address these challenges, we use an intuitive transfer learning technique to produce a set of high-quality synthetic captions paired with curated CC images. We then develop a data- and compute-efficient training recipe that requires as little as 3% of the LAION-2B data needed to train existing SD2 models, but obtains comparable quality. These results indicate that we have a sufficient number of CC images (~70 million) for training high-quality models. Our training recipe also implements a variety of optimizations that achieve ~3X training speed-ups, enabling rapid model iteration. We leverage this recipe to train several high-quality text-to-image models, which we dub the CommonCanvas family. Our largest model achieves comparable performance to SD2 on a human evaluation, despite being trained on our CC dataset that is significantly smaller than LAION and using synthetic captions for training. We release our models, data, and code at https://github.com/mosaicml/diffusion/blob/main/assets/common-canvas.md