 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommonCanvas: An Open Diffusion Model Trained with Creative-Commons Images
Oct 25, 2023



We assemble a dataset of Creative-Commons-licensed (CC) images, which we use to train a set of open diffusion models that are qualitatively competitive with Stable Diffusion 2 (SD2). This task presents two challenges: (1) high-resolution CC images lack the captions necessary to train text-to-image generative models; (2) CC images are relatively scarce. In turn, to address these challenges, we use an intuitive transfer learning technique to produce a set of high-quality synthetic captions paired with curated CC images. We then develop a data- and compute-efficient training recipe that requires as little as 3% of the LAION-2B data needed to train existing SD2 models, but obtains comparable quality. These results indicate that we have a sufficient number of CC images (~70 million) for training high-quality models. Our training recipe also implements a variety of optimizations that achieve ~3X training speed-ups, enabling rapid model iteration. We leverage this recipe to train several high-quality text-to-image models, which we dub the CommonCanvas family. Our largest model achieves comparable performance to SD2 on a human evaluation, despite being trained on our CC dataset that is significantly smaller than LAION and using synthetic captions for training. We release our models, data, and code at https://github.com/mosaicml/diffusion/blob/main/assets/common-canvas.md
Understanding the Logit Distributions of Adversarially-Trained Deep Neural Networks
Aug 26, 2021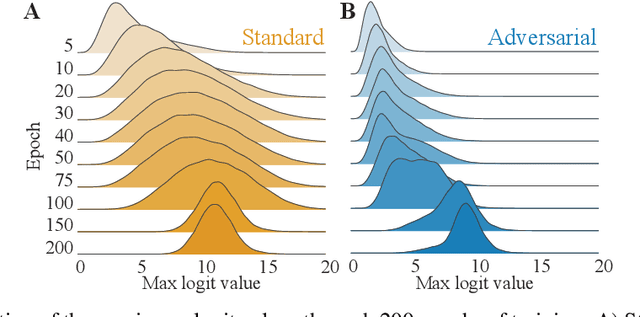

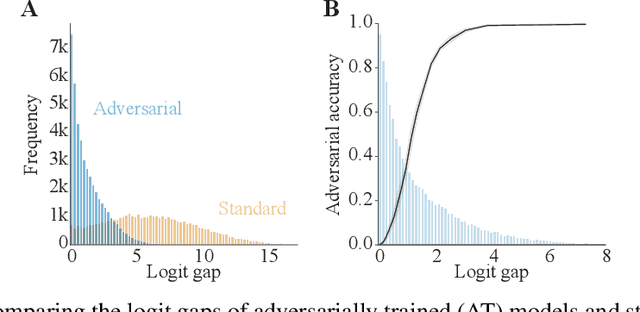

Adversarial defenses train deep neural networks to be invariant to the input perturbations from adversarial attacks. Almost all defense strategies achieve this invariance through adversarial training i.e. training on inputs with adversarial perturbations. Although adversarial training is successful at mitigating adversarial attacks, the behavioral differences between adversarially-trained (AT) models and standard models are still poorly understood. Motivated by a recent study on learning robustness without input perturbations by distilling an AT model, we explore what is learned during adversarial training by analyzing the distribution of logits in AT models. We identify three logit characteristics essential to learning adversarial robustness. First, we provide a theoretical justification for the finding that adversarial training shrinks two important characteristics of the logit distribution: the max logit values and the "logit gaps" (difference between the logit max and next largest values) are on average lower for AT models. Second, we show that AT and standard models differ significantly on which samples are high or low confidence, then illustrate clear qualitative differences by visualizing samples with the largest confidence difference. Finally, we find learning information about incorrect classes to be essential to learning robustness by manipulating the non-max logit information during distillation and measuring the impact on the student's robustness. Our results indicate that learning some adversarial robustness without input perturbations requires a model to learn specific sample-wise confidences and incorrect class orderings that follow complex distributions.