 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
CommonCanvas: An Open Diffusion Model Trained with Creative-Commons Images
Oct 25, 2023



We assemble a dataset of Creative-Commons-licensed (CC) images, which we use to train a set of open diffusion models that are qualitatively competitive with Stable Diffusion 2 (SD2). This task presents two challenges: (1) high-resolution CC images lack the captions necessary to train text-to-image generative models; (2) CC images are relatively scarce. In turn, to address these challenges, we use an intuitive transfer learning technique to produce a set of high-quality synthetic captions paired with curated CC images. We then develop a data- and compute-efficient training recipe that requires as little as 3% of the LAION-2B data needed to train existing SD2 models, but obtains comparable quality. These results indicate that we have a sufficient number of CC images (~70 million) for training high-quality models. Our training recipe also implements a variety of optimizations that achieve ~3X training speed-ups, enabling rapid model iteration. We leverage this recipe to train several high-quality text-to-image models, which we dub the CommonCanvas family. Our largest model achieves comparable performance to SD2 on a human evaluation, despite being trained on our CC dataset that is significantly smaller than LAION and using synthetic captions for training. We release our models, data, and code at https://github.com/mosaicml/diffusion/blob/main/assets/common-canvas.md
JRMOT: A Real-Time 3D Multi-Object Tracker and a New Large-Scale Dataset
Mar 18, 2020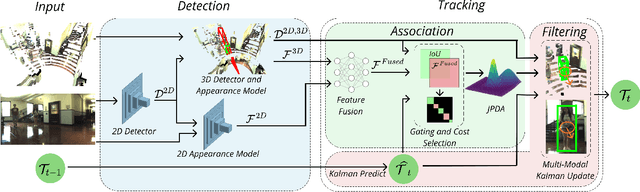
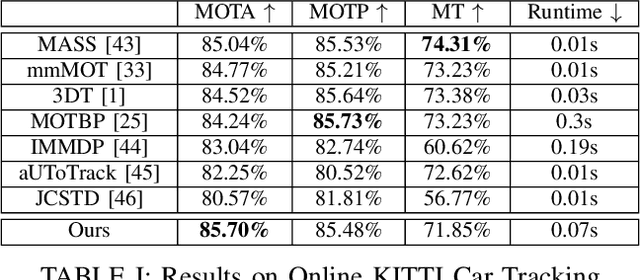
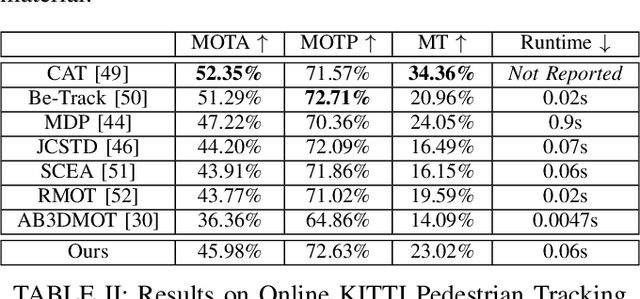
An autonomous navigating agent needs to perceive and track the motion of objects and other agents in its surroundings to achieve robust and safe motion planning and execution. While autonomous navigation requires a multi-object tracking (MOT) system to provide 3D information, most research has been done in 2D MOT from RGB videos. In this work we present JRMOT, a novel 3D MOT system that integrates information from 2D RGB images and 3D point clouds into a real-time performing framework. Our system leverages advancements in neural-network based re-identification as well as 2D and 3D detection and descriptors. We incorporate this into a joint probabilistic data-association framework within a multi-modal recursive Kalman architecture to achieve online, real-time 3D MOT. As part of our work, we release the JRDB dataset, a novel large scale 2D+3D dataset and benchmark annotated with over 2 million boxes and 3500 time consistent 2D+3D trajectories across 54 indoor and outdoor scenes. The dataset contains over 60 minutes of data including 360 degree cylindrical RGB video and 3D pointclouds. The presented 3D MOT system demonstrates state-of-the-art performance against competing methods on the popular 2D tracking KITTI benchmark and serves as a competitive 3D tracking baseline for our dataset and benchmark.
JRDB: A Dataset and Benchmark for Visual Perception for Navigation in Human Environments
Oct 25, 2019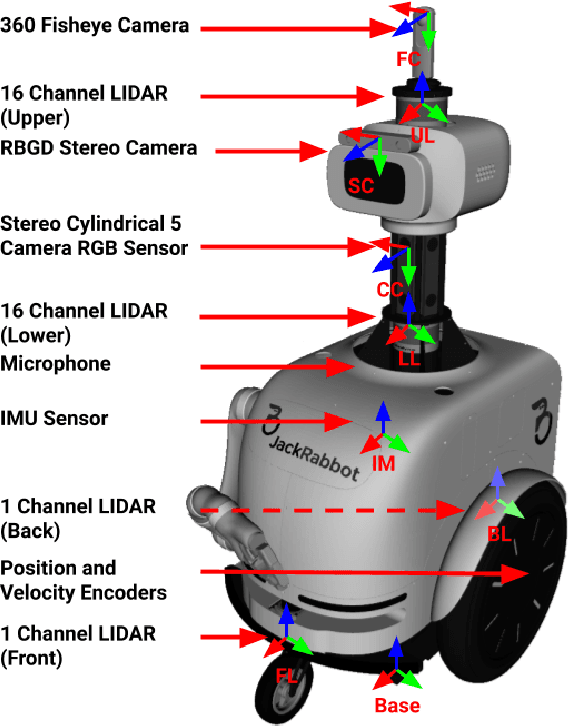
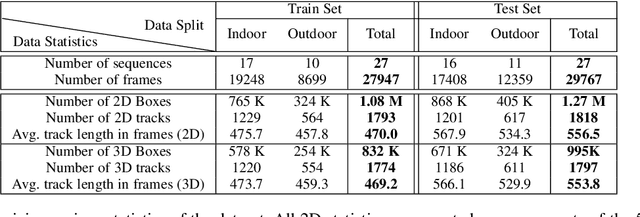
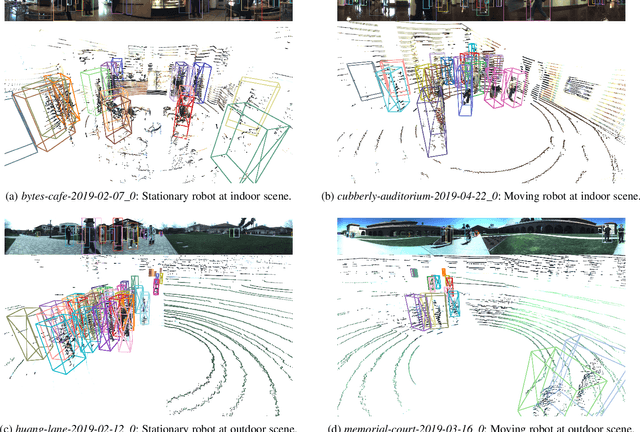
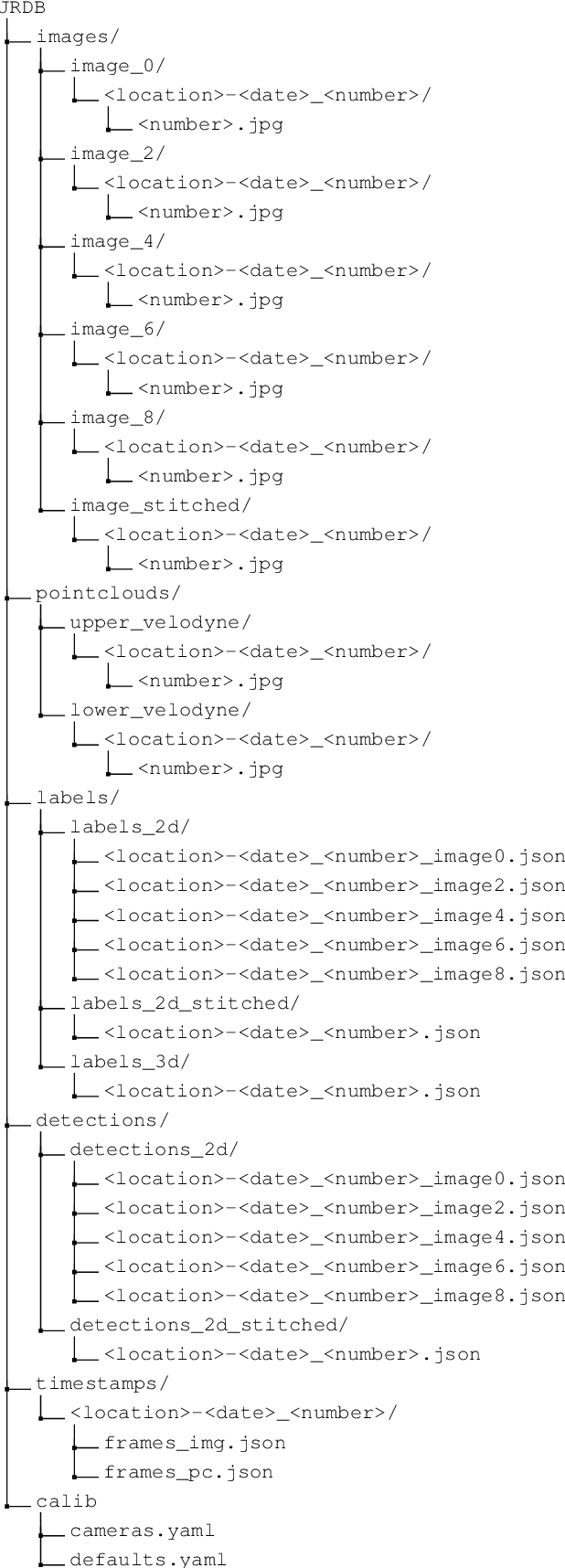
We present JRDB, a novel dataset collected from our social mobile manipulator JackRabbot. The dataset includes 64 minutes of multimodal sensor data including stereo cylindrical 360$^\circ$ RGB video at 15 fps, 3D point clouds from two Velodyne 16 Lidars, line 3D point clouds from two Sick Lidars, audio signal, RGBD video at 30 fps, 360$^\circ$ spherical image from a fisheye camera and encoder values from the robot's wheels. Our dataset includes data from traditionally underrepresented scenes such as indoor environments and pedestrian areas, from both stationary and navigating robot platform. The dataset has been annotated with over 2.3 million bounding boxes spread over 5 individual cameras and 1.8 million associated 3D cuboids around all people in the scenes totalling over 3500 time consistent trajectories. Together with our dataset and the annotations, we launch a benchmark and metrics for 2D and 3D person detection and tracking. With this dataset, that we plan on further annotating in the future, we hope to provide a new source of data and a test-bench for research in the areas of robot autonomous navigation and all perceptual tasks around social robotics in human environments.