 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-imagine the Negative Prompt Algorithm: Transform 2D Diffusion into 3D, alleviate Janus problem and Beyond
Apr 26, 2023



Although text-to-image diffusion models have made significant strides in generating images from text, they are sometimes more inclined to generate images like the data on which the model was trained rather than the provided text. This limitation has hindered their usage in both 2D and 3D applications. To address this problem, we explored the use of negative prompts but found that the current implementation fails to produce desired results, particularly when there is an overlap between the main and negative prompts. To overcome this issue, we propose Perp-Neg, a new algorithm that leverages the geometrical properties of the score space to address the shortcomings of the current negative prompts algorithm. Perp-Neg does not require any training or fine-tuning of the model. Moreover, we experimentally demonstrate that Perp-Neg provides greater flexibility in generating images by enabling users to edit out unwanted concepts from the initially generated images in 2D cases. Furthermore, to extend the application of Perp-Neg to 3D, we conducted a thorough exploration of how Perp-Neg can be used in 2D to condition the diffusion model to generate desired views, rather than being biased toward the canonical views. Finally, we applied our 2D intuition to integrate Perp-Neg with the state-of-the-art text-to-3D (DreamFusion) method, effectively addressing its Janus (multi-head) problem. Our project page is available at https://Perp-Neg.github.io/
3SD: Self-Supervised Saliency Detection With No Labels
Mar 09, 2022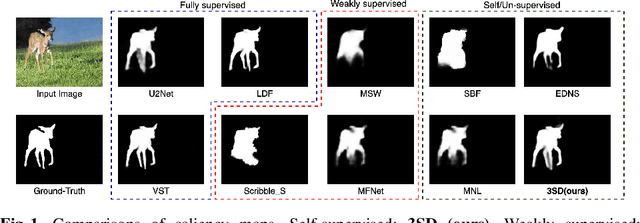
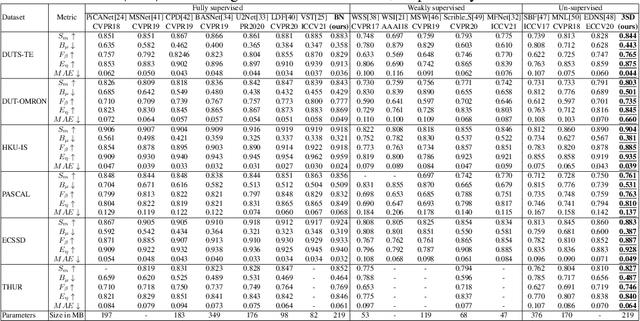

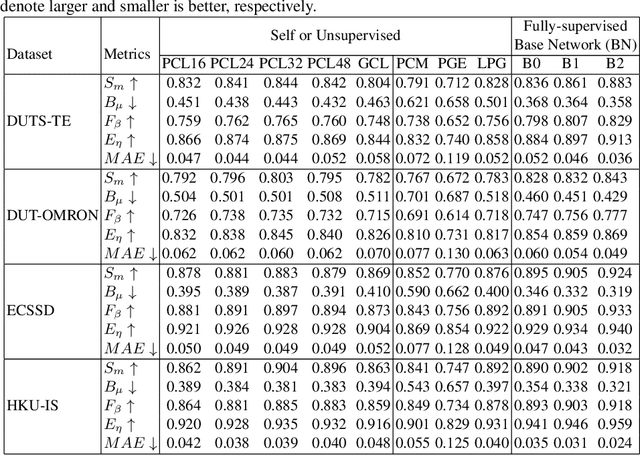
We present a conceptually simple self-supervised method for saliency detection. Our method generates and uses pseudo-ground truth labels for training. The generated pseudo-GT labels don't require any kind of human annotations (e.g., pixel-wise labels or weak labels like scribbles). Recent works show that features extracted from classification tasks provide important saliency cues like structure and semantic information of salient objects in the image. Our method, called 3SD, exploits this idea by adding a branch for a self-supervised classification task in parallel with salient object detection, to obtain class activation maps (CAM maps). These CAM maps along with the edges of the input image are used to generate the pseudo-GT saliency maps to train our 3SD network. Specifically, we propose a contrastive learning-based training on multiple image patches for the classification task. We show the multi-patch classification with contrastive loss improves the quality of the CAM maps compared to naive classification on the entire image. Experiments on six benchmark datasets demonstrate that without any labels, our 3SD method outperforms all existing weakly supervised and unsupervised methods, and its performance is on par with the fully-supervised methods. Code is available at :https://github.com/rajeevyasarla/3SD
JRMOT: A Real-Time 3D Multi-Object Tracker and a New Large-Scale Dataset
Mar 18, 2020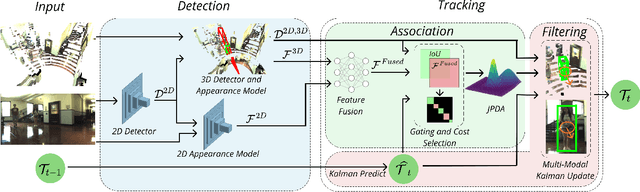
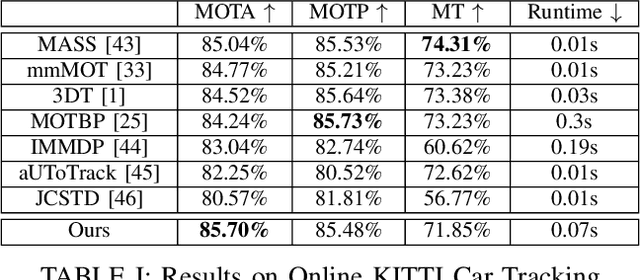
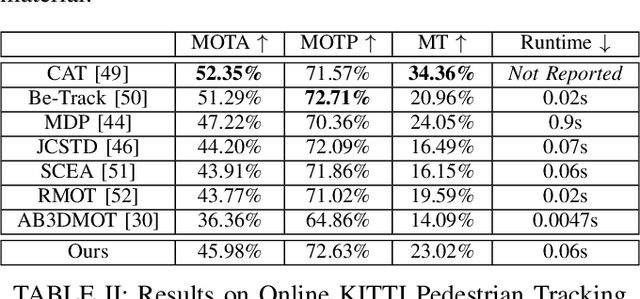
An autonomous navigating agent needs to perceive and track the motion of objects and other agents in its surroundings to achieve robust and safe motion planning and execution. While autonomous navigation requires a multi-object tracking (MOT) system to provide 3D information, most research has been done in 2D MOT from RGB videos. In this work we present JRMOT, a novel 3D MOT system that integrates information from 2D RGB images and 3D point clouds into a real-time performing framework. Our system leverages advancements in neural-network based re-identification as well as 2D and 3D detection and descriptors. We incorporate this into a joint probabilistic data-association framework within a multi-modal recursive Kalman architecture to achieve online, real-time 3D MOT. As part of our work, we release the JRDB dataset, a novel large scale 2D+3D dataset and benchmark annotated with over 2 million boxes and 3500 time consistent 2D+3D trajectories across 54 indoor and outdoor scenes. The dataset contains over 60 minutes of data including 360 degree cylindrical RGB video and 3D pointclouds. The presented 3D MOT system demonstrates state-of-the-art performance against competing methods on the popular 2D tracking KITTI benchmark and serves as a competitive 3D tracking baseline for our dataset and benchmark.
Social-BiGAT: Multimodal Trajectory Forecasting using Bicycle-GAN and Graph Attention Networks
Jul 17, 2019
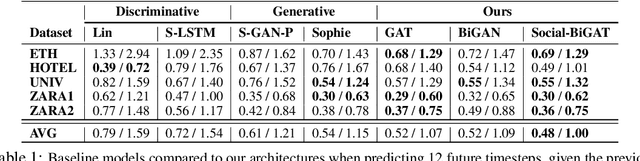
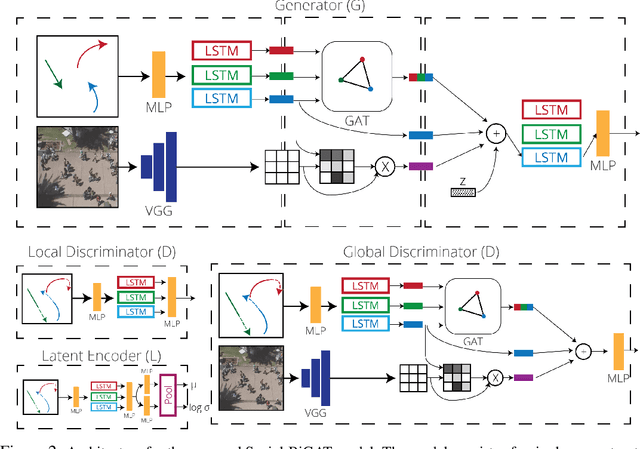
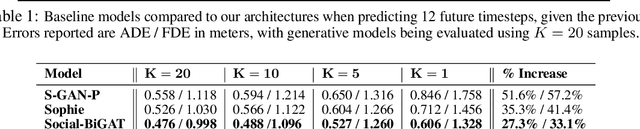
Predicting the future trajectories of multiple interacting agents in a scene has become an increasingly important problem for many different applications ranging from control of autonomous vehicles and social robots to security and surveillance. This problem is compounded by the presence of social interactions between humans and their physical interactions with the scene. While the existing literature has explored some of these cues, they mainly ignored the multimodal nature of each human's future trajectory. In this paper, we present Social-BiGAT, a graph-based generative adversarial network that generates realistic, multimodal trajectory predictions by better modelling the social interactions of pedestrians in a scene. Our method is based on a graph attention network (GAT) that learns reliable feature representations that encode the social interactions between humans in the scene, and a recurrent encoder-decoder architecture that is trained adversarially to predict, based on the features, the humans' paths. We explicitly account for the multimodal nature of the prediction problem by forming a reversible transformation between each scene and its latent noise vector, as in Bicycle-GAN. We show that our framework achieves state-of-the-art performance comparing it to several baselines on existing trajectory forecasting benchmarks.
Time-Varying Interaction Estimation Using Ensemble Methods
Jun 25, 2019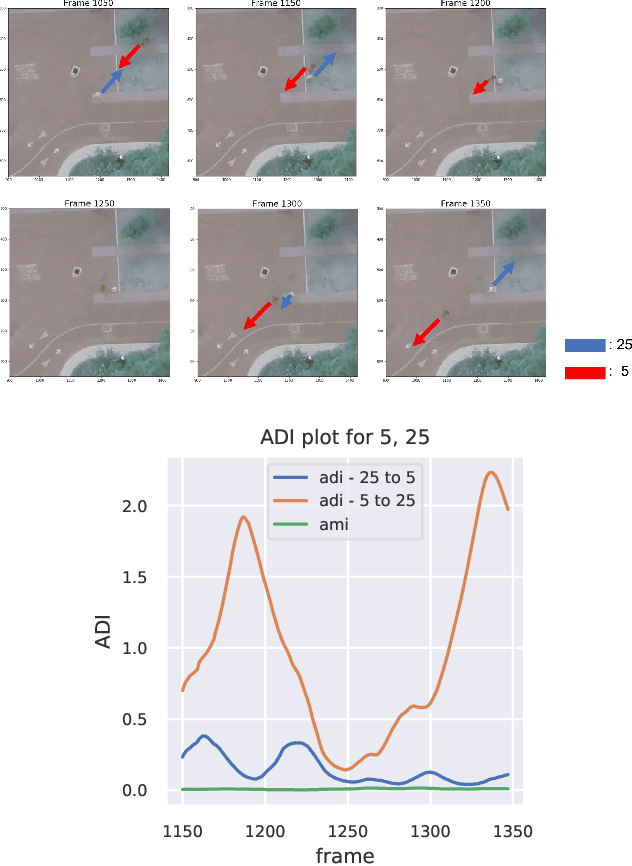
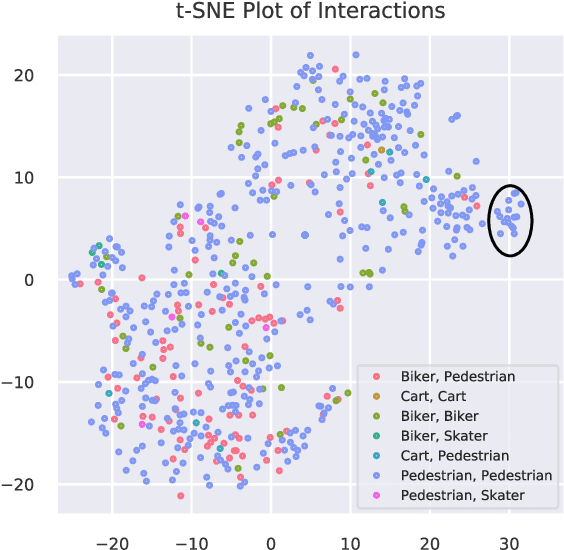
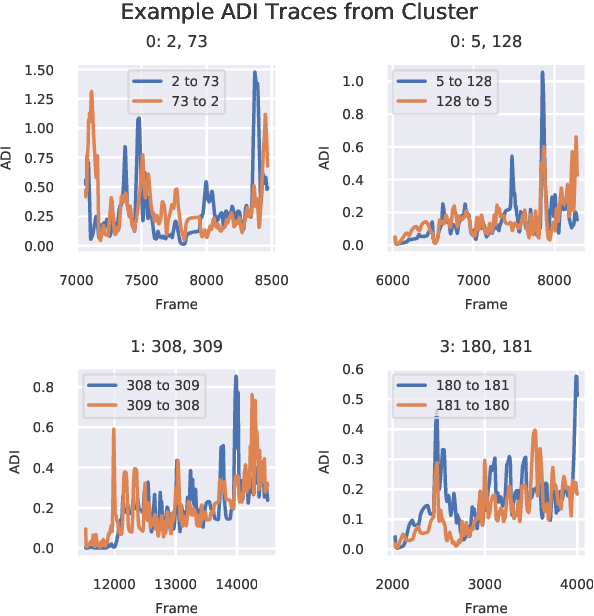
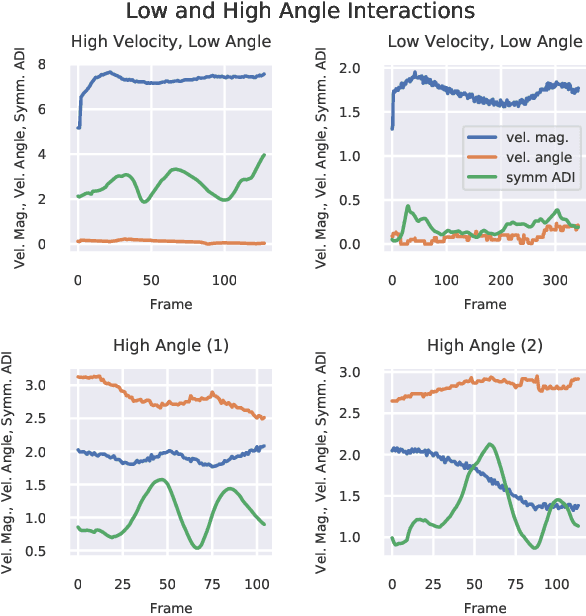
Directed information (DI) is a useful tool to explore time-directed interactions in multivariate data. However, as originally formulated DI is not well suited to interactions that change over time. In previous work, adaptive directed information was introduced to accommodate non-stationarity, while still preserving the utility of DI to discover complex dependencies between entities. There are many design decisions and parameters that are crucial to the effectiveness of ADI. Here, we apply ideas from ensemble learning in order to alleviate this issue, allowing for a more robust estimator for exploratory data analysis. We apply these techniques to interaction estimation in a crowded scene, utilizing the Stanford drone dataset as an example.
Deep Local Trajectory Replanning and Control for Robot Navigation
May 13, 2019
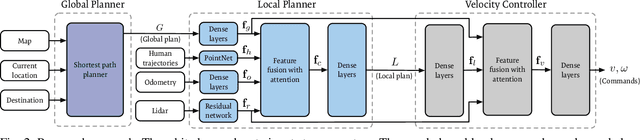
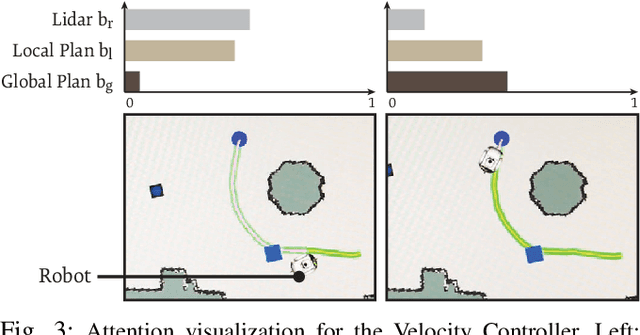
We present a navigation system that combines ideas from hierarchical planning and machine learning. The system uses a traditional global planner to compute optimal paths towards a goal, and a deep local trajectory planner and velocity controller to compute motion commands. The latter components of the system adjust the behavior of the robot through attention mechanisms such that it moves towards the goal, avoids obstacles, and respects the space of nearby pedestrians. Both the structure of the proposed deep models and the use of attention mechanisms make the system's execution interpretable. Our simulation experiments suggest that the proposed architecture outperforms baselines that try to map global plan information and sensor data directly to velocity commands. In comparison to a hand-designed traditional navigation system, the proposed approach showed more consistent performance.
Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression
Apr 15, 2019



Intersection over Union (IoU) is the most popular evaluation metric used in the object detection benchmarks. However, there is a gap between optimizing the commonly used distance losses for regressing the parameters of a bounding box and maximizing this metric value. The optimal objective for a metric is the metric itself. In the case of axis-aligned 2D bounding boxes, it can be shown that $IoU$ can be directly used as a regression loss. However, $IoU$ has a plateau making it infeasible to optimize in the case of non-overlapping bounding boxes. In this paper, we address the weaknesses of $IoU$ by introducing a generalized version as both a new loss and a new metric. By incorporating this generalized $IoU$ ($GIoU$) as a loss into the state-of-the art object detection frameworks, we show a consistent improvement on their performance using both the standard, $IoU$ based, and new, $GIoU$ based, performance measures on popular object detection benchmarks such as PASCAL VOC and MS COCO.
Deep Visual MPC-Policy Learning for Navigation
Mar 07, 2019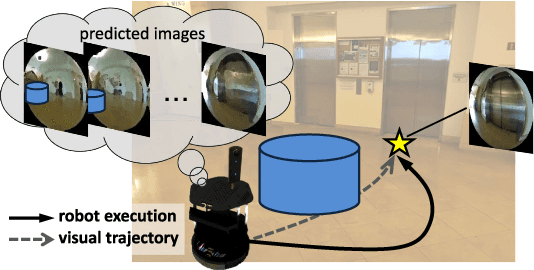
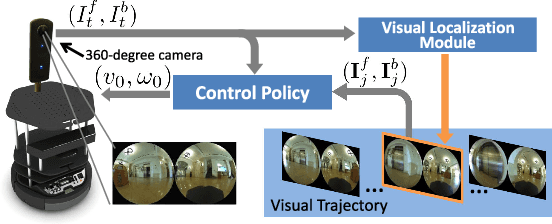


Humans can routinely follow a trajectory defined by a list of images/landmarks. However, traditional robot navigation methods require accurate mapping of the environment, localization, and planning. Moreover, these methods are sensitive to subtle changes in the environment. In this paper, we propose a Deep Visual MPC-policy learning method that can perform visual navigation while avoiding collisions with unseen objects on the navigation path. Our model PoliNet takes in as input a visual trajectory and the image of the robot's current view and outputs velocity commands for a planning horizon of $N$ steps that optimally balance between trajectory following and obstacle avoidance. PoliNet is trained using a strong image predictive model and traversability estimation model in a MPC setup, with minimal human supervision. Different from prior work, PoliNet can be applied to new scenes without retraining. We show experimentally that the robot can follow a visual trajectory when varying start position and in the presence of previously unseen obstacles. We validated our algorithm with tests both in a realistic simulation environment and in the real world. We also show that we can generate visual trajectories in simulation and execute the corresponding path in the real environment. Our approach outperforms classical approaches as well as previous learning-based baselines in success rate of goal reaching, sub-goal coverage rate, and computational load.
VUNet: Dynamic Scene View Synthesis for Traversability Estimation using an RGB Camera
Jan 10, 2019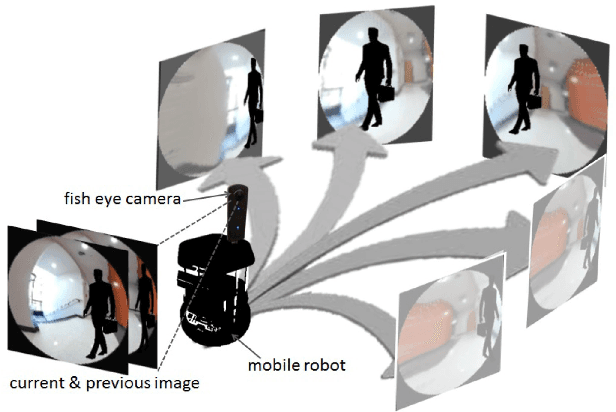

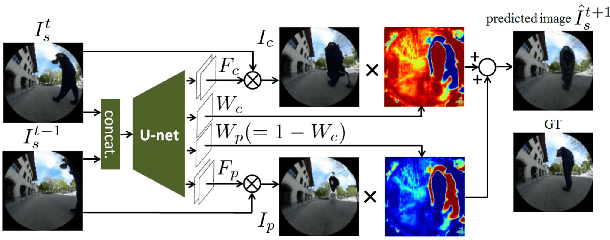
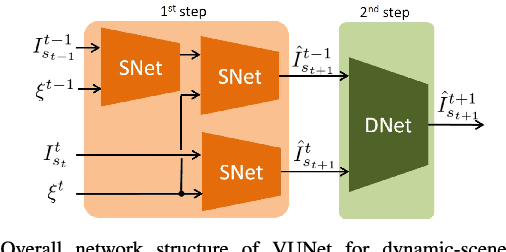
We present VUNet, a novel view(VU) synthesis method for mobile robots in dynamic environments, and its application to the estimation of future traversability. Our method predicts future images for given virtual robot velocity commands using only RGB images at previous and current time steps. The future images result from applying two types of image changes to the previous and current images: 1) changes caused by different camera pose, and 2) changes due to the motion of the dynamic obstacles. We learn to predict these two types of changes disjointly using two novel network architectures, SNet and DNet. We combine SNet and DNet to synthesize future images that we pass to our previously presented method GONet to estimate the traversable areas around the robot. Our quantitative and qualitative evaluation indicate that our approach for view synthesis predicts accurate future images in both static and dynamic environments. We also show that these virtual images can be used to estimate future traversability correctly. We apply our view synthesis-based traversability estimation method to two applications for assisted teleoperation.
* website: http://svl.stanford.edu/projects/vunet/
SoPhie: An Attentive GAN for Predicting Paths Compliant to Social and Physical Constraints
Sep 20, 2018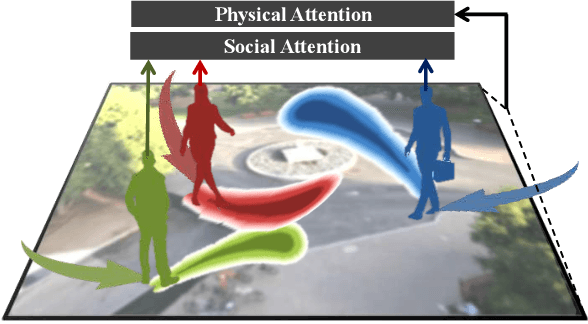
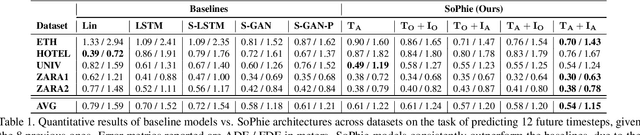
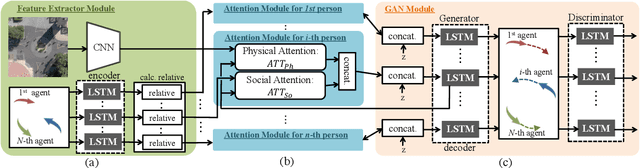

This paper addresses the problem of path prediction for multiple interacting agents in a scene, which is a crucial step for many autonomous platforms such as self-driving cars and social robots. We present \textit{SoPhie}; an interpretable framework based on Generative Adversarial Network (GAN), which leverages two sources of information, the path history of all the agents in a scene, and the scene context information, using images of the scene. To predict a future path for an agent, both physical and social information must be leveraged. Previous work has not been successful to jointly model physical and social interactions. Our approach blends a social attention mechanism with a physical attention that helps the model to learn where to look in a large scene and extract the most salient parts of the image relevant to the path. Whereas, the social attention component aggregates information across the different agent interactions and extracts the most important trajectory information from the surrounding neighbors. SoPhie also takes advantage of GAN to generates more realistic samples and to capture the uncertain nature of the future paths by modeling its distribution. All these mechanisms enable our approach to predict socially and physically plausible paths for the agents and to achieve state-of-the-art performance on several different trajectory forecasting benchmarks.