 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Rule Injection for ComplEx Embeddings
Aug 07, 2023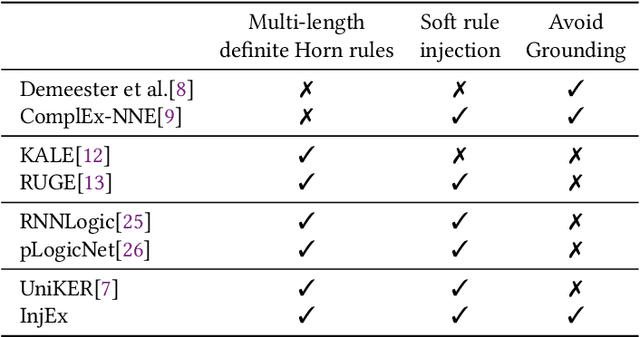
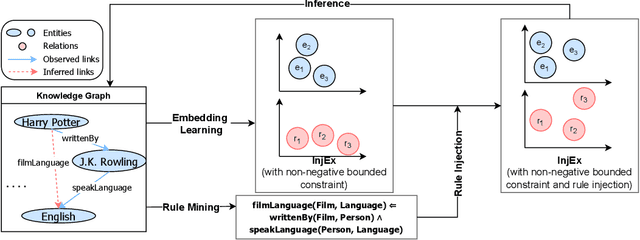
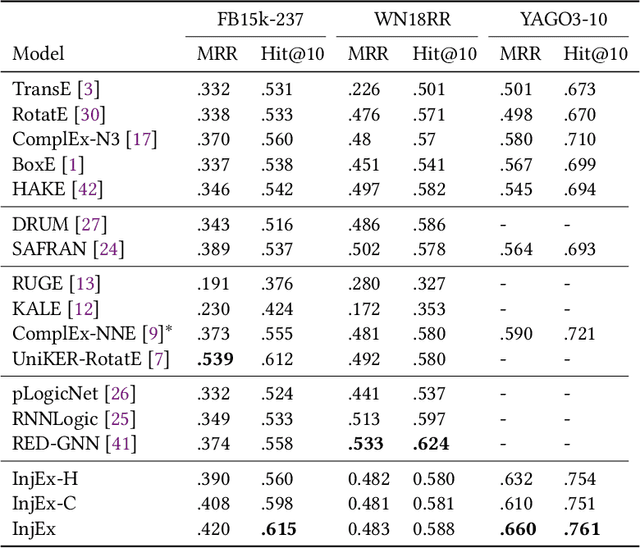
Recent works in neural knowledge graph inference attempt to combine logic rules with knowledge graph embeddings to benefit from prior knowledge. However, they usually cannot avoid rule grounding, and injecting a diverse set of rules has still not been thoroughly explored. In this work, we propose InjEx, a mechanism to inject multiple types of rules through simple constraints, which capture definite Horn rules. To start, we theoretically prove that InjEx can inject such rules. Next, to demonstrate that InjEx infuses interpretable prior knowledge into the embedding space, we evaluate InjEx on both the knowledge graph completion (KGC) and few-shot knowledge graph completion (FKGC) settings. Our experimental results reveal that InjEx outperforms both baseline KGC models as well as specialized few-shot models while maintaining its scalability and efficiency.
Re-imagine the Negative Prompt Algorithm: Transform 2D Diffusion into 3D, alleviate Janus problem and Beyond
Apr 26, 2023



Although text-to-image diffusion models have made significant strides in generating images from text, they are sometimes more inclined to generate images like the data on which the model was trained rather than the provided text. This limitation has hindered their usage in both 2D and 3D applications. To address this problem, we explored the use of negative prompts but found that the current implementation fails to produce desired results, particularly when there is an overlap between the main and negative prompts. To overcome this issue, we propose Perp-Neg, a new algorithm that leverages the geometrical properties of the score space to address the shortcomings of the current negative prompts algorithm. Perp-Neg does not require any training or fine-tuning of the model. Moreover, we experimentally demonstrate that Perp-Neg provides greater flexibility in generating images by enabling users to edit out unwanted concepts from the initially generated images in 2D cases. Furthermore, to extend the application of Perp-Neg to 3D, we conducted a thorough exploration of how Perp-Neg can be used in 2D to condition the diffusion model to generate desired views, rather than being biased toward the canonical views. Finally, we applied our 2D intuition to integrate Perp-Neg with the state-of-the-art text-to-3D (DreamFusion) method, effectively addressing its Janus (multi-head) problem. Our project page is available at https://Perp-Neg.github.io/
EventNarrative: A large-scale Event-centric Dataset for Knowledge Graph-to-Text Generation
Oct 30, 2021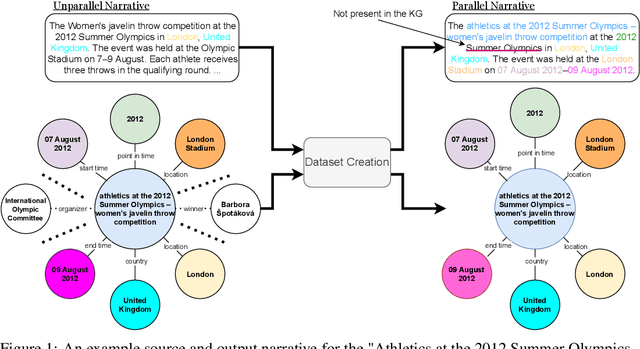



We introduce EventNarrative, a knowledge graph-to-text dataset from publicly available open-world knowledge graphs. Given the recent advances in event-driven Information Extraction (IE), and that prior research on graph-to-text only focused on entity-driven KGs, this paper focuses on event-centric data. However, our data generation system can still be adapted to other other types of KG data. Existing large-scale datasets in the graph-to-text area are non-parallel, meaning there is a large disconnect between the KGs and text. The datasets that have a paired KG and text, are small scale and manually generated or generated without a rich ontology, making the corresponding graphs sparse. Furthermore, these datasets contain many unlinked entities between their KG and text pairs. EventNarrative consists of approximately 230,000 graphs and their corresponding natural language text, 6 times larger than the current largest parallel dataset. It makes use of a rich ontology, all of the KGs entities are linked to the text, and our manual annotations confirm a high data quality. Our aim is two-fold: help break new ground in event-centric research where data is lacking, and to give researchers a well-defined, large-scale dataset in order to better evaluate existing and future knowledge graph-to-text models. We also evaluate two types of baseline on EventNarrative: a graph-to-text specific model and two state-of-the-art language models, which previous work has shown to be adaptable to the knowledge graph-to-text domain.
Partition-Guided GANs
Apr 02, 2021
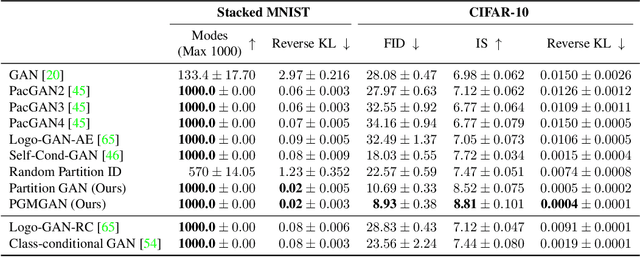
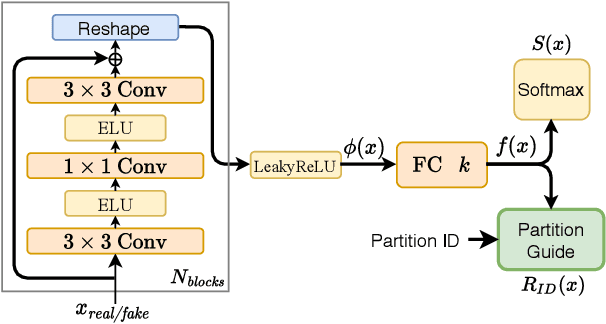

Despite the success of Generative Adversarial Networks (GANs), their training suffers from several well-known problems, including mode collapse and difficulties learning a disconnected set of manifolds. In this paper, we break down the challenging task of learning complex high dimensional distributions, supporting diverse data samples, to simpler sub-tasks. Our solution relies on designing a partitioner that breaks the space into smaller regions, each having a simpler distribution, and training a different generator for each partition. This is done in an unsupervised manner without requiring any labels. We formulate two desired criteria for the space partitioner that aid the training of our mixture of generators: 1) to produce connected partitions and 2) provide a proxy of distance between partitions and data samples, along with a direction for reducing that distance. These criteria are developed to avoid producing samples from places with non-existent data density, and also facilitate training by providing additional direction to the generators. We develop theoretical constraints for a space partitioner to satisfy the above criteria. Guided by our theoretical analysis, we design an effective neural architecture for the space partitioner that empirically assures these conditions. Experimental results on various standard benchmarks show that the proposed unsupervised model outperforms several recent methods.
ChronoR: Rotation Based Temporal Knowledge Graph Embedding
Mar 18, 2021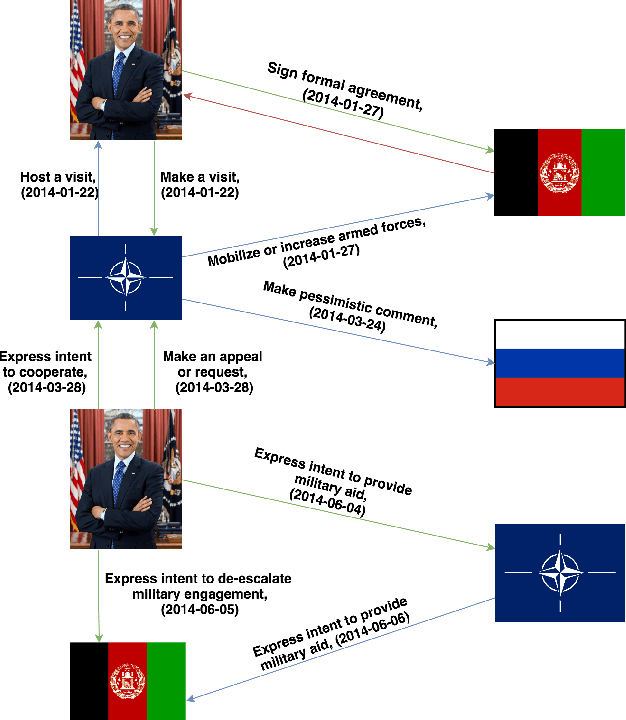
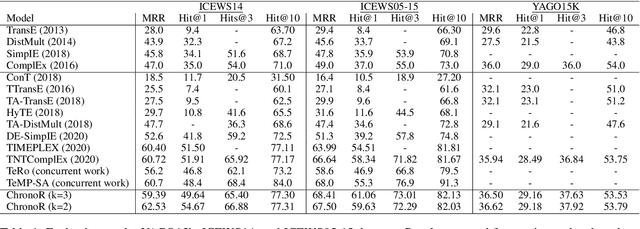
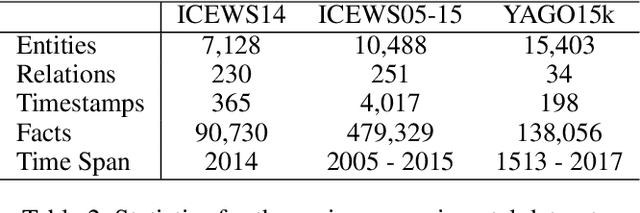
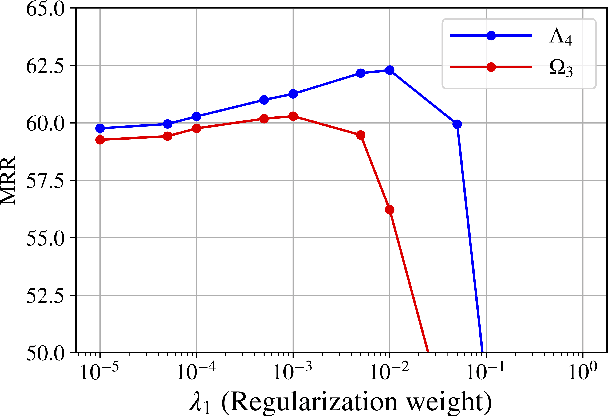
Despite the importance and abundance of temporal knowledge graphs, most of the current research has been focused on reasoning on static graphs. In this paper, we study the challenging problem of inference over temporal knowledge graphs. In particular, the task of temporal link prediction. In general, this is a difficult task due to data non-stationarity, data heterogeneity, and its complex temporal dependencies. We propose Chronological Rotation embedding (ChronoR), a novel model for learning representations for entities, relations, and time. Learning dense representations is frequently used as an efficient and versatile method to perform reasoning on knowledge graphs. The proposed model learns a k-dimensional rotation transformation parametrized by relation and time, such that after each fact's head entity is transformed using the rotation, it falls near its corresponding tail entity. By using high dimensional rotation as its transformation operator, ChronoR captures rich interaction between the temporal and multi-relational characteristics of a Temporal Knowledge Graph. Experimentally, we show that ChronoR is able to outperform many of the state-of-the-art methods on the benchmark datasets for temporal knowledge graph link prediction.
DRUM: End-To-End Differentiable Rule Mining On Knowledge Graphs
Oct 31, 2019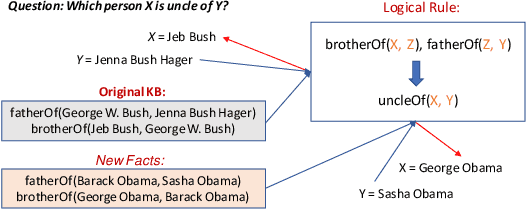
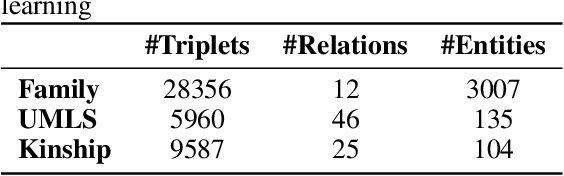

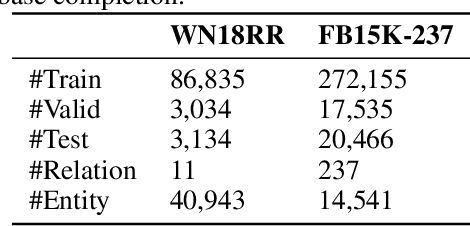
In this paper, we study the problem of learning probabilistic logical rules for inductive and interpretable link prediction. Despite the importance of inductive link prediction, most previous works focused on transductive link prediction and cannot manage previously unseen entities. Moreover, they are black-box models that are not easily explainable for humans. We propose DRUM, a scalable and differentiable approach for mining first-order logical rules from knowledge graphs which resolves these problems. We motivate our method by making a connection between learning confidence scores for each rule and low-rank tensor approximation. DRUM uses bidirectional RNNs to share useful information across the tasks of learning rules for different relations. We also empirically demonstrate the efficiency of DRUM over existing rule mining methods for inductive link prediction on a variety of benchmark datasets.
Hotel2vec: Learning Attribute-Aware Hotel Embeddings with Self-Supervision
Sep 30, 2019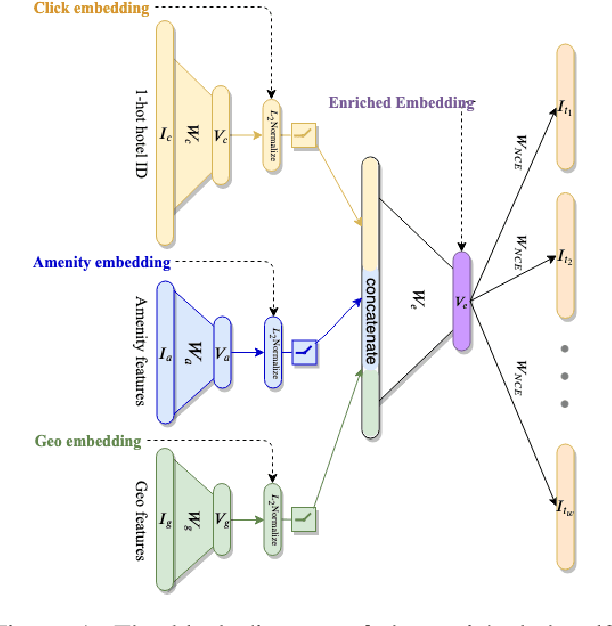
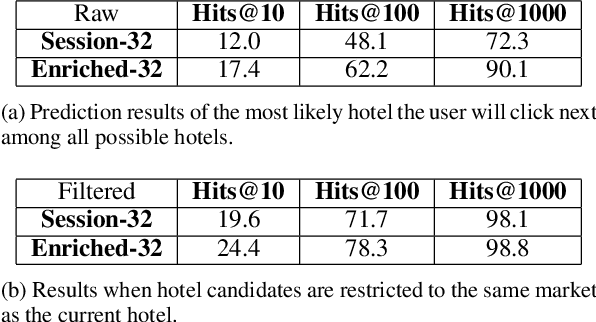

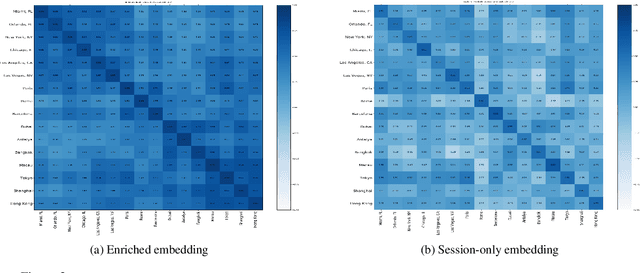
We propose a neural network architecture for learning vector representations of hotels. Unlike previous works, which typically only use user click information for learning item embeddings, we propose a framework that combines several sources of data, including user clicks, hotel attributes (e.g., property type, star rating, average user rating), amenity information (e.g., the hotel has free Wi-Fi or free breakfast), and geographic information. During model training, a joint embedding is learned from all of the above information. We show that including structured attributes about hotels enables us to make better predictions in a downstream task than when we rely exclusively on click data. We train our embedding model on more than 40 million user click sessions from a leading online travel platform and learn embeddings for more than one million hotels. Our final learned embeddings integrate distinct sub-embeddings for user clicks, hotel attributes, and geographic information, providing an interpretable representation that can be used flexibly depending on the application. We show empirically that our model generates high-quality representations that boost the performance of a hotel recommendation system in addition to other applications. An important advantage of the proposed neural model is that it addresses the cold-start problem for hotels with insufficient historical click information by incorporating additional hotel attributes which are available for all hotels.
Mining Rules Incrementally over Large Knowledge Bases
Apr 20, 2019

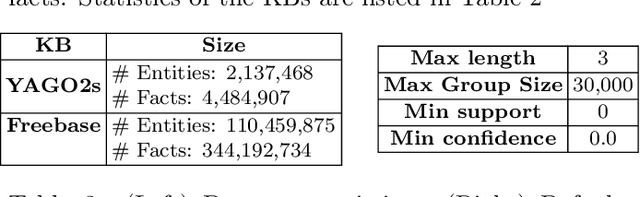
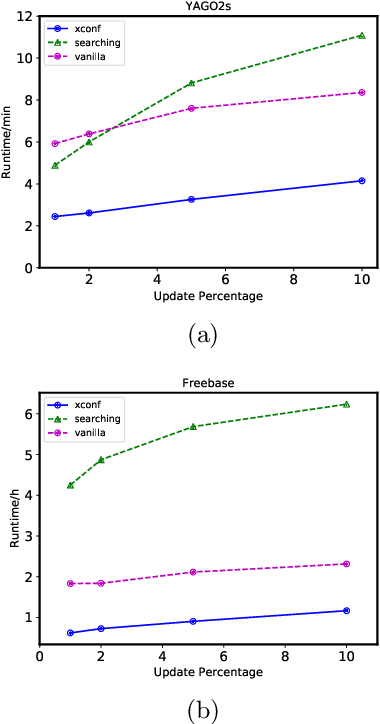
Multiple web-scale Knowledge Bases, e.g., Freebase, YAGO, NELL, have been constructed using semi-supervised or unsupervised information extraction techniques and many of them, despite their large sizes, are continuously growing. Much research effort has been put into mining inference rules from knowledge bases. To address the task of rule mining over evolving web-scale knowledge bases, we propose a parallel incremental rule mining framework. Our approach is able to efficiently mine rules based on the relational model and apply updates to large knowledge bases; we propose an alternative metric that reduces computation complexity without compromising quality; we apply multiple optimization techniques that reduce runtime by more than 2 orders of magnitude. Experiments show that our approach efficiently scales to web-scale knowledge bases and saves over 90% time compared to the state-of-the-art batch rule mining system. We also apply our optimization techniques to the batch rule mining algorithm, reducing runtime by more than half compared to the state-of-the-art. To the best of our knowledge, our incremental rule mining system is the first that handles updates to web-scale knowledge bases.
Automatic Target Recognition Using Discrimination Based on Optimal Transport
Apr 06, 2019
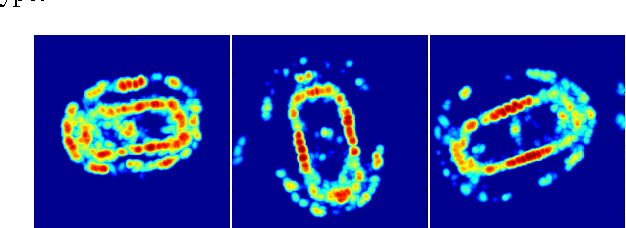
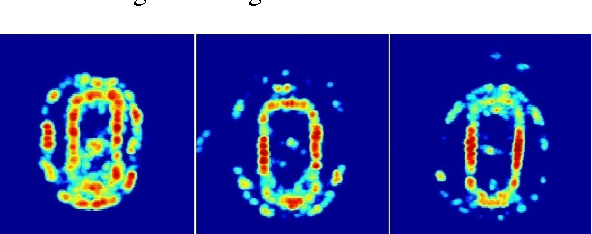
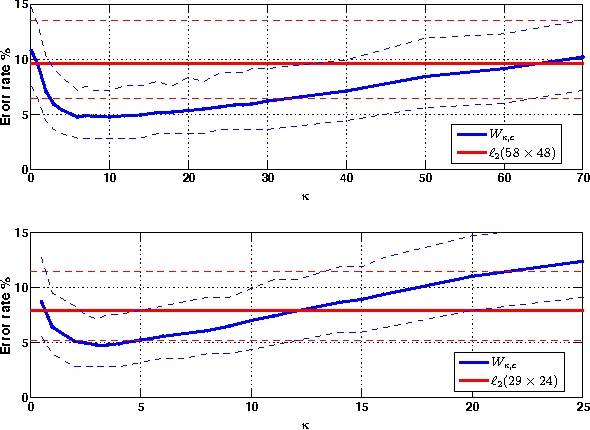
The use of distances based on optimal transportation has recently shown promise for discrimination of power spectra. In particular, spectral estimation methods based on l1 regularization as well as covariance based methods can be shown to be robust with respect to such distances. These transportation distances provide a geometric framework where geodesics corresponds to smooth transition of spectral mass, and have been useful for tracking. In this paper, we investigate the use of these distances for automatic target recognition. We study the use of the Monge-Kantorovich distance compared to the standard l2 distance for classifying civilian vehicles based on SAR images. We use a version of the Monge-Kantorovich distance that applies also for the case where the spectra may have different total mass, and we formulate the optimization problem as a minimum flow problem that can be computed using efficient algorithms.
SoPhie: An Attentive GAN for Predicting Paths Compliant to Social and Physical Constraints
Sep 20, 2018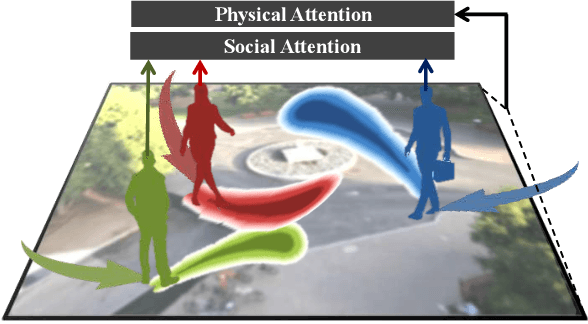
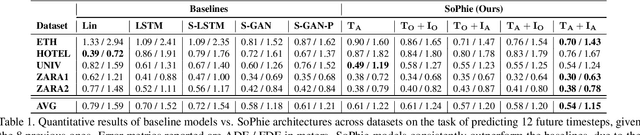
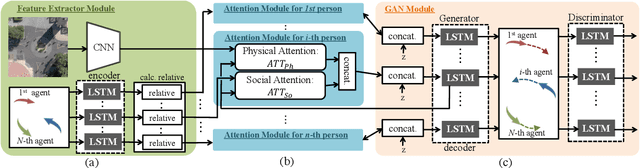

This paper addresses the problem of path prediction for multiple interacting agents in a scene, which is a crucial step for many autonomous platforms such as self-driving cars and social robots. We present \textit{SoPhie}; an interpretable framework based on Generative Adversarial Network (GAN), which leverages two sources of information, the path history of all the agents in a scene, and the scene context information, using images of the scene. To predict a future path for an agent, both physical and social information must be leveraged. Previous work has not been successful to jointly model physical and social interactions. Our approach blends a social attention mechanism with a physical attention that helps the model to learn where to look in a large scene and extract the most salient parts of the image relevant to the path. Whereas, the social attention component aggregates information across the different agent interactions and extracts the most important trajectory information from the surrounding neighbors. SoPhie also takes advantage of GAN to generates more realistic samples and to capture the uncertain nature of the future paths by modeling its distribution. All these mechanisms enable our approach to predict socially and physically plausible paths for the agents and to achieve state-of-the-art performance on several different trajectory forecasting benchmarks.