 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverse Probing: Supervised Token-level Uncertainty Quantification for Large Language Models in Clinical Text
May 27, 2026As large language models are increasingly deployed for clinical text, ensuring they can reliably signal their own uncertainty becomes critical. Most existing uncertainty quantification (UQ) methods are designed for open-domain generation and cannot localize uncertainty at the token or span level in long clinical text. We propose Reverse Probing, the first UQ framework specialized for clinical summarization, which estimates token-level uncertainty directly from pre-existing labeled summaries. Rather than sampling new outputs, Reverse Probing treats the text as a probe into the model's internal state, extracting uncertainty signals from four categories of internal activations. We evaluate on two expert-annotated clinical datasets and outperform eight adapted baselines on all metrics, achieving up to 4 times higher AUPRC while reducing inference time and computational costs. Feature analysis reveals that delta energy and neighborhood context are the most consistent predictors across all models. This study offers interpretable insights into how models internally respond to unsupported clinical content.
Retrieval-Augmented Long-Context Translation for Cultural Image Captioning: Gators submission for AmericasNLP 2026 shared task
May 20, 2026We present the University of Florida Gators submission to the AmericasNLP 2026 shared task on cultural image captioning for Indigenous languages. Our two-stage pipeline generates a Spanish intermediate caption with Qwen2.5-VL, then produces the target-language caption using retrieval-augmented many-shot prompting with Gemini 2.5 Flash. We achieve 164.1%, 131.7%, and 122.6% improvements over the shared task baseline for Bribri, Guaraní, and Orizaba Nahuatl captioning, respectively, in our dev set evaluation and maintain >150% improvements for the Bribri and Orizaba Nahuatl languages in the test set evaluation. We find retrieval is highly language-dependent, beneficial only for large, in-domain corpora, and that synthetic data augmentation accounts for around 28 chrF++ of the dev set Guaraní performance gain. Our submission is the overall winner of the shared task, placing second out of five finalist submissions in human evaluations of target-language captions.
Meta Engine: A Unified Semantic Query Engine on Heterogeneous LLM-Based Query Systems
Feb 02, 2026With the increasingly use of multi-modal data, semantic query has become more and more demanded in data management systems, which is an important way to access and analyze multi-modal data. As unstructured data, most information of multi-modal data (text, image, video, etc) hides in the semantics, which cannot be accessed by the traditional database queries like SQL. Given the power of Large Language Model (LLM) in understanding semantics and processing natural language, in recent years several LLM-based semantic query systems have been proposed, to support semantic querying over unstructured data. However, this rapid growth has produced a fragmented ecosystem. Applications face significant integration challenges due to (1) disparate APIs of different semantic query systems and (2) a fundamental trade-off between specialization and generality. Many semantic query systems are highly specialized, offering state-of-the-art performance within a single modality but struggling with multi-modal data. Conversely, some "all-in-one" systems handle multiple modalities but often exhibit suboptimal performance compared to their specialized counterparts in specific modalities. This paper introduces Meta Engine, a novel "query system on query systems", designed to resolve those aforementioned challenges. Meta Engine is a unified semantic query engine that integrates heterogeneous, specialized LLM-based query systems. Its architecture comprises five key components: (1) a Natural Language (NL) Query Parser, (2) an Operator Generator, (3) a Query Router, (4) a set of Adapters, and (5) a Result Aggregator. In the evaluation, Meta Engine consistently outperforms all baselines, yielding 3-6x higher F1 in most cases and up to 24x on specific datasets.
Improving Indigenous Language Machine Translation with Synthetic Data and Language-Specific Preprocessing
Jan 06, 2026Low-resource indigenous languages often lack the parallel corpora required for effective neural machine translation (NMT). Synthetic data generation offers a practical strategy for mitigating this limitation in data-scarce settings. In this work, we augment curated parallel datasets for indigenous languages of the Americas with synthetic sentence pairs generated using a high-capacity multilingual translation model. We fine-tune a multilingual mBART model on curated-only and synthetically augmented data and evaluate translation quality using chrF++, the primary metric used in recent AmericasNLP shared tasks for agglutinative languages. We further apply language-specific preprocessing, including orthographic normalization and noise-aware filtering, to reduce corpus artifacts. Experiments on Guarani--Spanish and Quechua--Spanish translation show consistent chrF++ improvements from synthetic data augmentation, while diagnostic experiments on Aymara highlight the limitations of generic preprocessing for highly agglutinative languages.
MultiScript30k: Leveraging Multilingual Embeddings to Extend Cross Script Parallel Data
Dec 11, 2025Multi30k is frequently cited in the multimodal machine translation (MMT) literature, offering parallel text data for training and fine-tuning deep learning models. However, it is limited to four languages: Czech, English, French, and German. This restriction has led many researchers to focus their investigations only on these languages. As a result, MMT research on diverse languages has been stalled because the official Multi30k dataset only represents European languages in Latin scripts. Previous efforts to extend Multi30k exist, but the list of supported languages, represented language families, and scripts is still very short. To address these issues, we propose MultiScript30k, a new Multi30k dataset extension for global languages in various scripts, created by translating the English version of Multi30k (Multi30k-En) using NLLB200-3.3B. The dataset consists of over \(30000\) sentences and provides translations of all sentences in Multi30k-En into Ar, Es, Uk, Zh\_Hans and Zh\_Hant. Similarity analysis shows that Multi30k extension consistently achieves greater than \(0.8\) cosine similarity and symmetric KL divergence less than \(0.000251\) for all languages supported except Zh\_Hant which is comparable to the previous Multi30k extensions ArEnMulti30k and Multi30k-Uk. COMETKiwi scores reveal mixed assessments of MultiScript30k as a translation of Multi30k-En in comparison to the related work. ArEnMulti30k scores nearly equal MultiScript30k-Ar, but Multi30k-Uk scores $6.4\%$ greater than MultiScript30k-Uk per split.
Towards Human Cognition: Visual Context Guides Syntactic Priming in Fusion-Encoded Models
Feb 24, 2025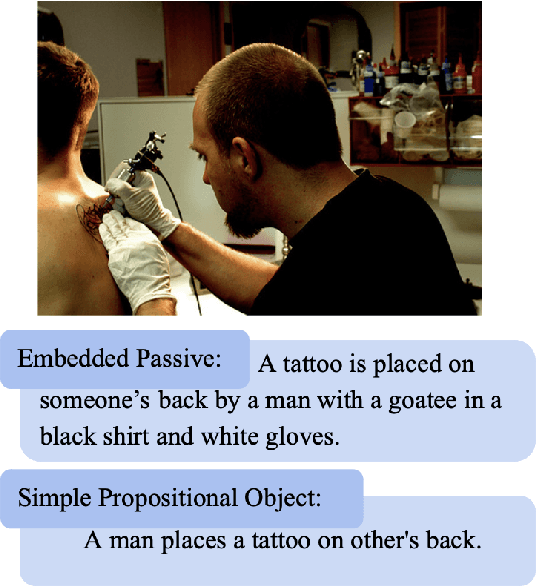
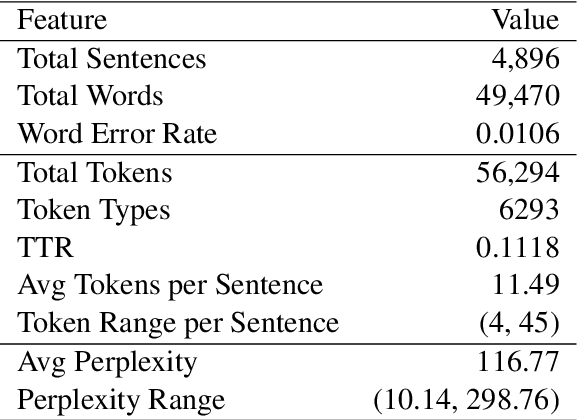
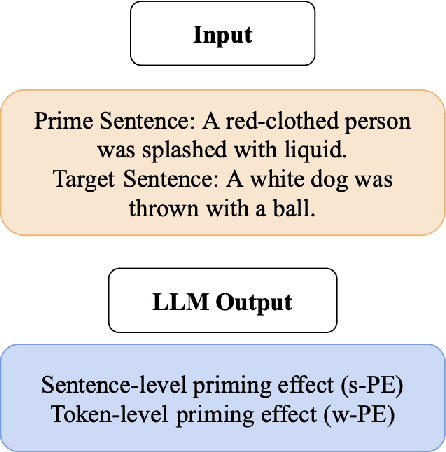
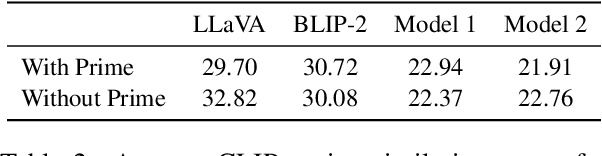
We introduced PRISMATIC, the first multimodal structural priming dataset, and proposed a reference-free evaluation metric that assesses priming effects without predefined target sentences. Using this metric, we constructed and tested models with different multimodal encoding architectures (dual encoder and fusion encoder) to investigate their structural preservation capabilities. Our findings show that models with both encoding methods demonstrate comparable syntactic priming effects. However, only fusion-encoded models exhibit robust positive correlations between priming effects and visual similarity, suggesting a cognitive process more aligned with human psycholinguistic patterns. This work provides new insights into evaluating and understanding how syntactic information is processed in multimodal language models.
Transformer-Based Multimodal Knowledge Graph Completion with Link-Aware Contexts
Jan 26, 2025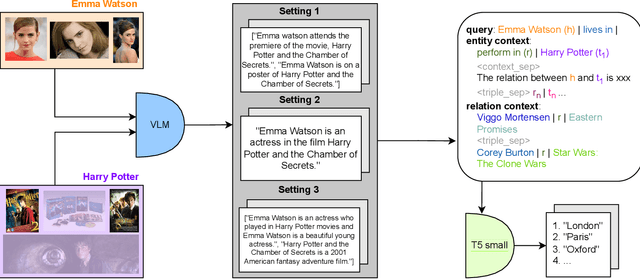
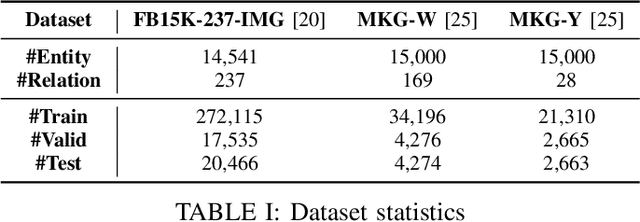
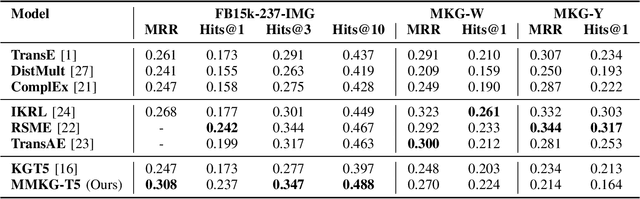

Multimodal knowledge graph completion (MMKGC) aims to predict missing links in multimodal knowledge graphs (MMKGs) by leveraging information from various modalities alongside structural data. Existing MMKGC approaches primarily extend traditional knowledge graph embedding (KGE) models, which often require creating an embedding for every entity. This results in large model sizes and inefficiencies in integrating multimodal information, particularly for real-world graphs. Meanwhile, Transformer-based models have demonstrated competitive performance in knowledge graph completion (KGC). However, their focus on single-modal knowledge limits their capacity to utilize cross-modal information. Recently, Large vision-language models (VLMs) have shown potential in cross-modal tasks but are constrained by the high cost of training. In this work, we propose a novel approach that integrates Transformer-based KGE models with cross-modal context generated by pre-trained VLMs, thereby extending their applicability to MMKGC. Specifically, we employ a pre-trained VLM to transform relevant visual information from entities and their neighbors into textual sequences. We then frame KGC as a sequence-to-sequence task, fine-tuning the model with the generated cross-modal context. This simple yet effective method significantly reduces model size compared to traditional KGE approaches while achieving competitive performance across multiple large-scale datasets with minimal hyperparameter tuning.
TTQA-RS- A break-down prompting approach for Multi-hop Table-Text Question Answering with Reasoning and Summarization
Jun 20, 2024
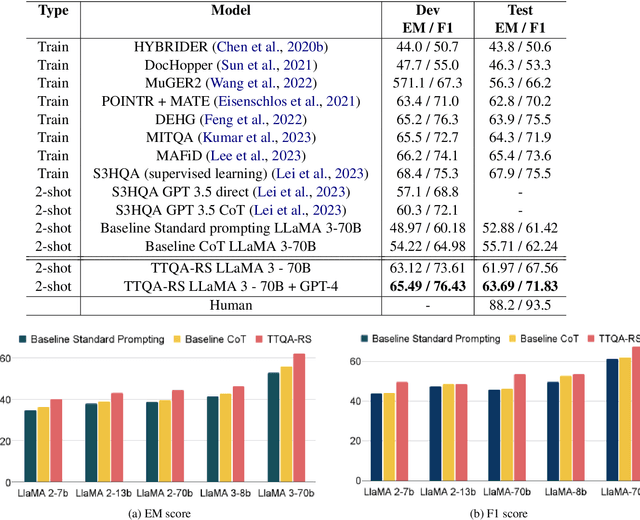
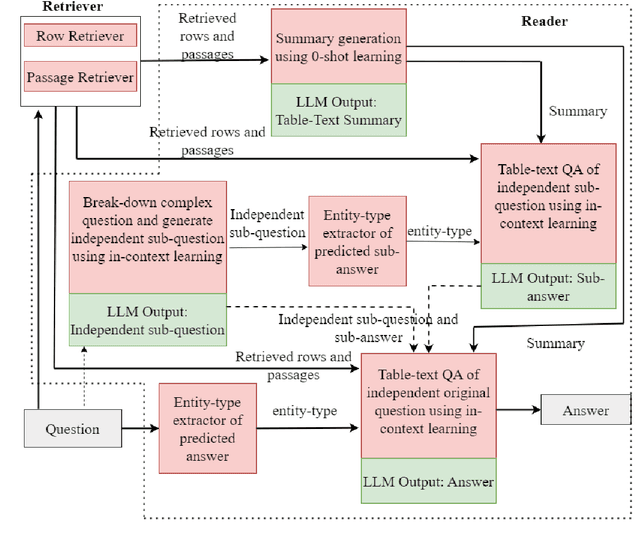
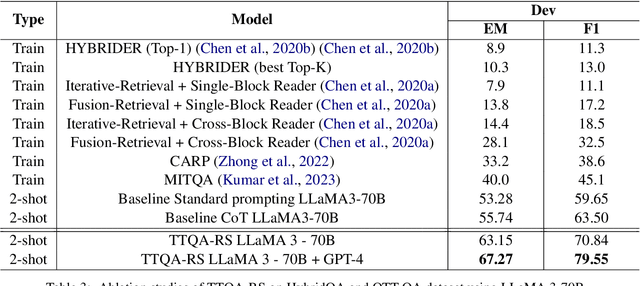
Question answering (QA) over tables and text has gained much popularity over the years. Multi-hop table-text QA requires multiple hops between the table and text, making it a challenging QA task. Although several works have attempted to solve the table-text QA task, most involve training the models and requiring labeled data. In this paper, we have proposed a model - TTQA-RS: A break-down prompting approach for Multi-hop Table-Text Question Answering with Reasoning and Summarization. Our model uses augmented knowledge including table-text summary with decomposed sub-question with answer for a reasoning-based table-text QA. Using open-source language models our model outperformed all existing prompting methods for table-text QA tasks on existing table-text QA datasets like HybridQA and OTT-QA's development set. Our results are comparable with the training-based state-of-the-art models, demonstrating the potential of prompt-based approaches using open-source LLMs. Additionally, by using GPT-4 with LLaMA3-70B, our model achieved state-of-the-art performance for prompting-based methods on multi-hop table-text QA.
No more optimization rules: LLM-enabled policy-based multi-modal query optimizer
Mar 23, 2024Large language model (LLM) has marked a pivotal moment in the field of machine learning and deep learning. Recently its capability for query planning has been investigated, including both single-modal and multi-modal queries. However, there is no work on the query optimization capability of LLM. As a critical (or could even be the most important) step that significantly impacts the execution performance of the query plan, such analysis and attempts should not be missed. From another aspect, existing query optimizers are usually rule-based or rule-based + cost-based, i.e., they are dependent on manually created rules to complete the query plan rewrite/transformation. Given the fact that modern optimizers include hundreds to thousands of rules, designing a multi-modal query optimizer following a similar way is significantly time-consuming since we will have to enumerate as many multi-modal optimization rules as possible, which has not been well addressed today. In this paper, we investigate the query optimization ability of LLM and use LLM to design LaPuda, a novel LLM and Policy based multi-modal query optimizer. Instead of enumerating specific and detailed rules, LaPuda only needs a few abstract policies to guide LLM in the optimization, by which much time and human effort are saved. Furthermore, to prevent LLM from making mistakes or negative optimization, we borrow the idea of gradient descent and propose a guided cost descent (GCD) algorithm to perform the optimization, such that the optimization can be kept in the correct direction. In our evaluation, our methods consistently outperform the baselines in most cases. For example, the optimized plans generated by our methods result in 1~3x higher execution speed than those by the baselines.
M3: A Multi-Task Mixed-Objective Learning Framework for Open-Domain Multi-Hop Dense Sentence Retrieval
Mar 21, 2024In recent research, contrastive learning has proven to be a highly effective method for representation learning and is widely used for dense retrieval. However, we identify that relying solely on contrastive learning can lead to suboptimal retrieval performance. On the other hand, despite many retrieval datasets supporting various learning objectives beyond contrastive learning, combining them efficiently in multi-task learning scenarios can be challenging. In this paper, we introduce M3, an advanced recursive Multi-hop dense sentence retrieval system built upon a novel Multi-task Mixed-objective approach for dense text representation learning, addressing the aforementioned challenges. Our approach yields state-of-the-art performance on a large-scale open-domain fact verification benchmark dataset, FEVER. Code and data are available at: https://github.com/TonyBY/M3