 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXling: A Learned Filter Framework for Accelerating High-Dimensional Approximate Similarity Join
Feb 20, 2024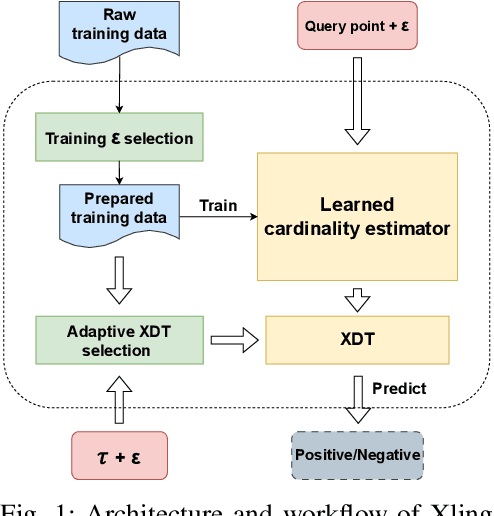
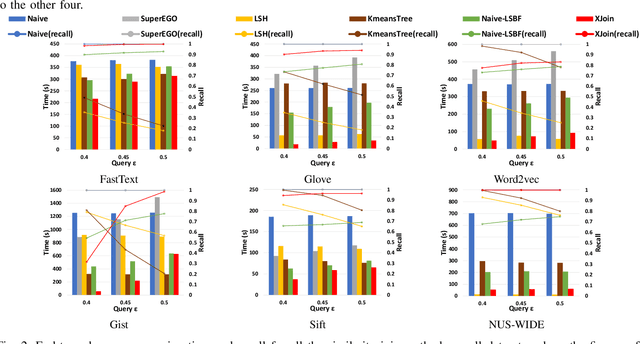
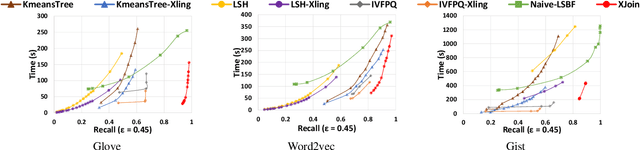
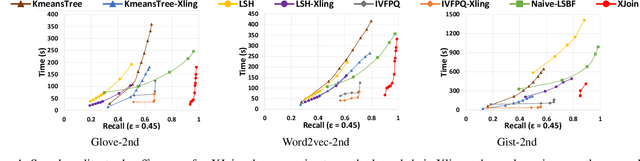
Similarity join finds all pairs of close points within a given distance threshold. Many similarity join methods have been proposed, but they are usually not efficient on high-dimensional space due to the curse of dimensionality and data-unawareness. We investigate the possibility of using metric space Bloom filter (MSBF), a family of data structures checking if a query point has neighbors in a multi-dimensional space, to speed up similarity join. However, there are several challenges when applying MSBF to similarity join, including excessive information loss, data-unawareness and hard constraint on the distance metric. In this paper, we propose Xling, a generic framework to build a learning-based metric space filter with any existing regression model, aiming at accurately predicting whether a query point has enough number of neighbors. The framework provides a suite of optimization strategies to further improve the prediction quality based on the learning model, which has demonstrated significantly higher prediction quality than existing MSBF. We also propose XJoin, one of the first filter-based similarity join methods, based on Xling. By predicting and skipping those queries without enough neighbors, XJoin can effectively reduce unnecessary neighbor searching and therefore it achieves a remarkable acceleration. Benefiting from the generalization capability of deep learning models, XJoin can be easily transferred onto new dataset (in similar distribution) without re-training. Furthermore, Xling is not limited to being applied in XJoin, instead, it acts as a flexible plugin that can be inserted to any loop-based similarity join methods for a speedup.