 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Engine: A Unified Semantic Query Engine on Heterogeneous LLM-Based Query Systems
Feb 02, 2026With the increasingly use of multi-modal data, semantic query has become more and more demanded in data management systems, which is an important way to access and analyze multi-modal data. As unstructured data, most information of multi-modal data (text, image, video, etc) hides in the semantics, which cannot be accessed by the traditional database queries like SQL. Given the power of Large Language Model (LLM) in understanding semantics and processing natural language, in recent years several LLM-based semantic query systems have been proposed, to support semantic querying over unstructured data. However, this rapid growth has produced a fragmented ecosystem. Applications face significant integration challenges due to (1) disparate APIs of different semantic query systems and (2) a fundamental trade-off between specialization and generality. Many semantic query systems are highly specialized, offering state-of-the-art performance within a single modality but struggling with multi-modal data. Conversely, some "all-in-one" systems handle multiple modalities but often exhibit suboptimal performance compared to their specialized counterparts in specific modalities. This paper introduces Meta Engine, a novel "query system on query systems", designed to resolve those aforementioned challenges. Meta Engine is a unified semantic query engine that integrates heterogeneous, specialized LLM-based query systems. Its architecture comprises five key components: (1) a Natural Language (NL) Query Parser, (2) an Operator Generator, (3) a Query Router, (4) a set of Adapters, and (5) a Result Aggregator. In the evaluation, Meta Engine consistently outperforms all baselines, yielding 3-6x higher F1 in most cases and up to 24x on specific datasets.
Transformer-Based Multimodal Knowledge Graph Completion with Link-Aware Contexts
Jan 26, 2025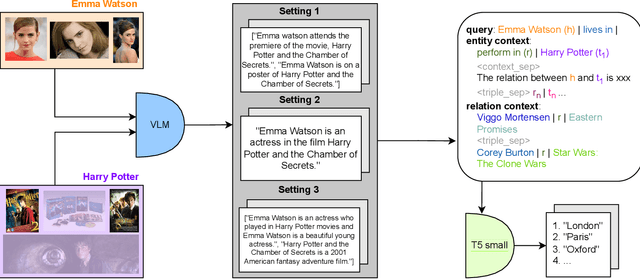
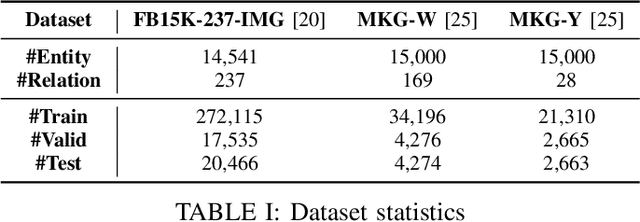
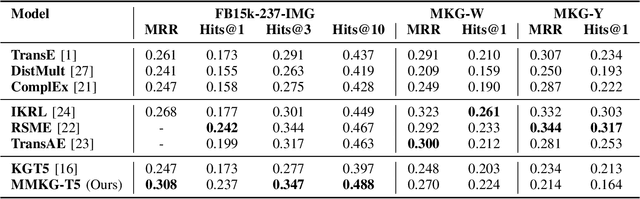

Multimodal knowledge graph completion (MMKGC) aims to predict missing links in multimodal knowledge graphs (MMKGs) by leveraging information from various modalities alongside structural data. Existing MMKGC approaches primarily extend traditional knowledge graph embedding (KGE) models, which often require creating an embedding for every entity. This results in large model sizes and inefficiencies in integrating multimodal information, particularly for real-world graphs. Meanwhile, Transformer-based models have demonstrated competitive performance in knowledge graph completion (KGC). However, their focus on single-modal knowledge limits their capacity to utilize cross-modal information. Recently, Large vision-language models (VLMs) have shown potential in cross-modal tasks but are constrained by the high cost of training. In this work, we propose a novel approach that integrates Transformer-based KGE models with cross-modal context generated by pre-trained VLMs, thereby extending their applicability to MMKGC. Specifically, we employ a pre-trained VLM to transform relevant visual information from entities and their neighbors into textual sequences. We then frame KGC as a sequence-to-sequence task, fine-tuning the model with the generated cross-modal context. This simple yet effective method significantly reduces model size compared to traditional KGE approaches while achieving competitive performance across multiple large-scale datasets with minimal hyperparameter tuning.
LLM Reasoners: New Evaluation, Library, and Analysis of Step-by-Step Reasoning with Large Language Models
Apr 08, 2024Generating accurate step-by-step reasoning is essential for Large Language Models (LLMs) to address complex problems and enhance robustness and interpretability. Despite the flux of research on developing advanced reasoning approaches, systematically analyzing the diverse LLMs and reasoning strategies in generating reasoning chains remains a significant challenge. The difficulties stem from the lack of two key elements: (1) an automatic method for evaluating the generated reasoning chains on different tasks, and (2) a unified formalism and implementation of the diverse reasoning approaches for systematic comparison. This paper aims to close the gap: (1) We introduce AutoRace for fully automated reasoning chain evaluation. Existing metrics rely on expensive human annotations or pre-defined LLM prompts not adaptable to different tasks. In contrast, AutoRace automatically creates detailed evaluation criteria tailored for each task, and uses GPT-4 for accurate evaluation following the criteria. (2) We develop LLM Reasoners, a library for standardized modular implementation of existing and new reasoning algorithms, under a unified formulation of the search, reward, and world model components. With the new evaluation and library, (3) we conduct extensive study of different reasoning approaches (e.g., CoT, ToT, RAP). The analysis reveals interesting findings about different factors contributing to reasoning, including the reward-guidance, breadth-vs-depth in search, world model, and prompt formats, etc.
No more optimization rules: LLM-enabled policy-based multi-modal query optimizer
Mar 23, 2024Large language model (LLM) has marked a pivotal moment in the field of machine learning and deep learning. Recently its capability for query planning has been investigated, including both single-modal and multi-modal queries. However, there is no work on the query optimization capability of LLM. As a critical (or could even be the most important) step that significantly impacts the execution performance of the query plan, such analysis and attempts should not be missed. From another aspect, existing query optimizers are usually rule-based or rule-based + cost-based, i.e., they are dependent on manually created rules to complete the query plan rewrite/transformation. Given the fact that modern optimizers include hundreds to thousands of rules, designing a multi-modal query optimizer following a similar way is significantly time-consuming since we will have to enumerate as many multi-modal optimization rules as possible, which has not been well addressed today. In this paper, we investigate the query optimization ability of LLM and use LLM to design LaPuda, a novel LLM and Policy based multi-modal query optimizer. Instead of enumerating specific and detailed rules, LaPuda only needs a few abstract policies to guide LLM in the optimization, by which much time and human effort are saved. Furthermore, to prevent LLM from making mistakes or negative optimization, we borrow the idea of gradient descent and propose a guided cost descent (GCD) algorithm to perform the optimization, such that the optimization can be kept in the correct direction. In our evaluation, our methods consistently outperform the baselines in most cases. For example, the optimized plans generated by our methods result in 1~3x higher execution speed than those by the baselines.
Can Knowledge Graphs Simplify Text?
Aug 17, 2023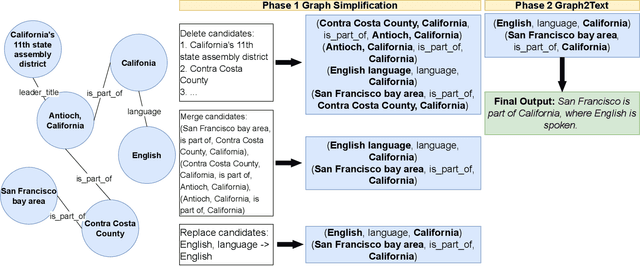
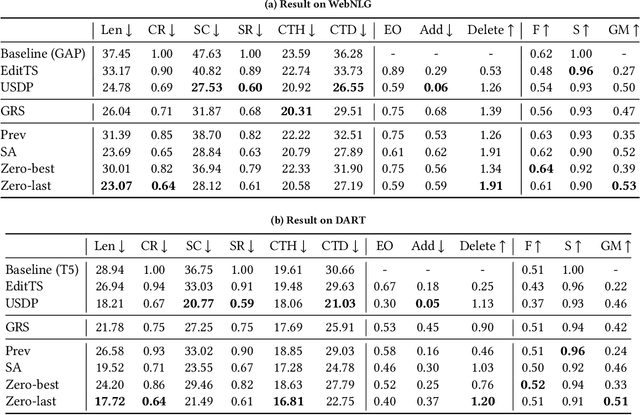
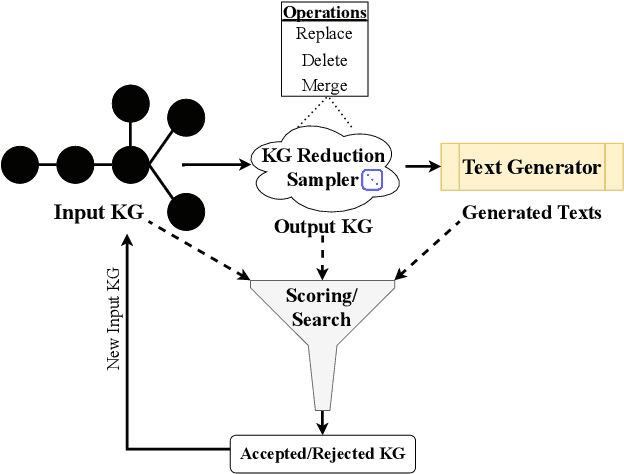
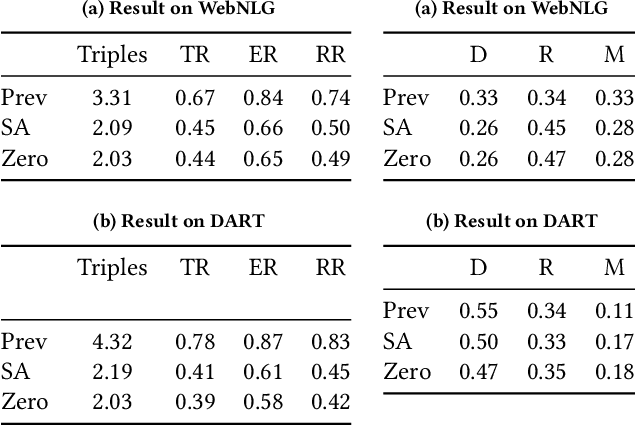
Knowledge Graph (KG)-to-Text Generation has seen recent improvements in generating fluent and informative sentences which describe a given KG. As KGs are widespread across multiple domains and contain important entity-relation information, and as text simplification aims to reduce the complexity of a text while preserving the meaning of the original text, we propose KGSimple, a novel approach to unsupervised text simplification which infuses KG-established techniques in order to construct a simplified KG path and generate a concise text which preserves the original input's meaning. Through an iterative and sampling KG-first approach, our model is capable of simplifying text when starting from a KG by learning to keep important information while harnessing KG-to-text generation to output fluent and descriptive sentences. We evaluate various settings of the KGSimple model on currently-available KG-to-text datasets, demonstrating its effectiveness compared to unsupervised text simplification models which start with a given complex text. Our code is available on GitHub.
Simple Rule Injection for ComplEx Embeddings
Aug 07, 2023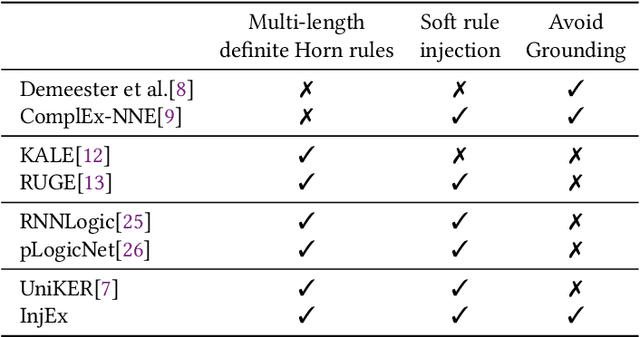
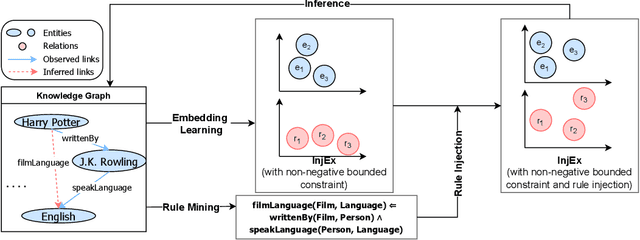
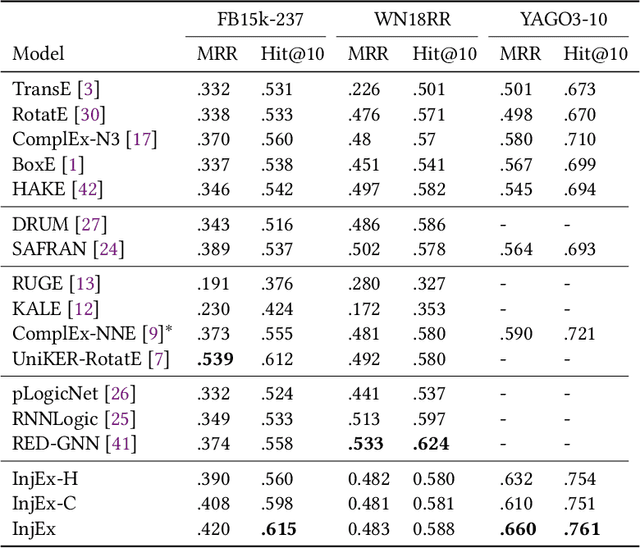
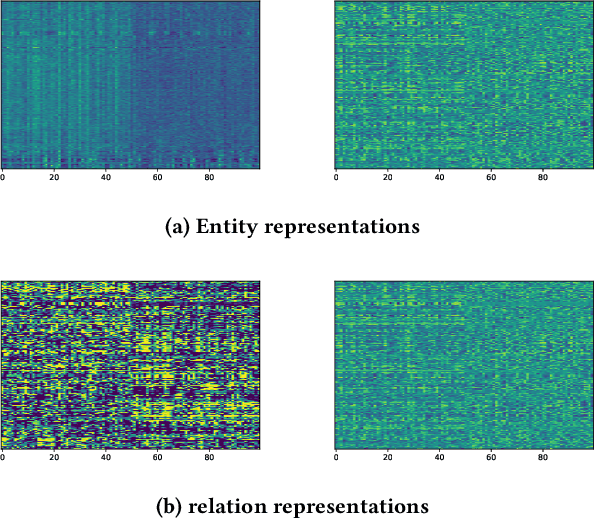
Recent works in neural knowledge graph inference attempt to combine logic rules with knowledge graph embeddings to benefit from prior knowledge. However, they usually cannot avoid rule grounding, and injecting a diverse set of rules has still not been thoroughly explored. In this work, we propose InjEx, a mechanism to inject multiple types of rules through simple constraints, which capture definite Horn rules. To start, we theoretically prove that InjEx can inject such rules. Next, to demonstrate that InjEx infuses interpretable prior knowledge into the embedding space, we evaluate InjEx on both the knowledge graph completion (KGC) and few-shot knowledge graph completion (FKGC) settings. Our experimental results reveal that InjEx outperforms both baseline KGC models as well as specialized few-shot models while maintaining its scalability and efficiency.
Reasoning with Language Model is Planning with World Model
May 24, 2023



Large language models (LLMs) have shown remarkable reasoning capabilities, especially when prompted to generate intermediate reasoning steps (e.g., Chain-of-Thought, CoT). However, LLMs can still struggle with problems that are easy for humans, such as generating action plans for executing tasks in a given environment, or performing complex math, logical, and commonsense reasoning. The deficiency stems from the key fact that LLMs lack an internal $\textit{world model}$ to predict the world $\textit{state}$ (e.g., environment status, intermediate variable values) and simulate long-term outcomes of actions. This prevents LLMs from performing deliberate planning akin to human brains, which involves exploring alternative reasoning paths, anticipating future states and rewards, and iteratively refining existing reasoning steps. To overcome the limitations, we propose a new LLM reasoning framework, $\underline{R}\textit{easoning vi}\underline{a} \underline{P}\textit{lanning}$ $\textbf{(RAP)}$. RAP repurposes the LLM as both a world model and a reasoning agent, and incorporates a principled planning algorithm (based on Monto Carlo Tree Search) for strategic exploration in the vast reasoning space. During reasoning, the LLM (as agent) incrementally builds a reasoning tree under the guidance of the LLM (as world model) and task-specific rewards, and obtains a high-reward reasoning path efficiently with a proper balance between exploration $\textit{vs.}$ exploitation. We apply RAP to a variety of challenging reasoning problems including plan generation, math reasoning, and logical inference. Empirical results on these tasks demonstrate the superiority of RAP over various strong baselines, including CoT and least-to-most prompting with self-consistency. RAP on LLAMA-33B surpasses CoT on GPT-4 with 33% relative improvement in a plan generation setting.
A Survey On Few-shot Knowledge Graph Completion with Structural and Commonsense Knowledge
Jan 03, 2023



Knowledge graphs (KG) have served as the key component of various natural language processing applications. Commonsense knowledge graphs (CKG) are a special type of KG, where entities and relations are composed of free-form text. However, previous works in KG completion and CKG completion suffer from long-tail relations and newly-added relations which do not have many know triples for training. In light of this, few-shot KG completion (FKGC), which requires the strengths of graph representation learning and few-shot learning, has been proposed to challenge the problem of limited annotated data. In this paper, we comprehensively survey previous attempts on such tasks in the form of a series of methods and applications. Specifically, we first introduce FKGC challenges, commonly used KGs, and CKGs. Then we systematically categorize and summarize existing works in terms of the type of KGs and the methods. Finally, we present applications of FKGC models on prediction tasks in different areas and share our thoughts on future research directions of FKGC.
LIDER: An Efficient High-dimensional Learned Index for Large-scale Dense Passage Retrieval
May 02, 2022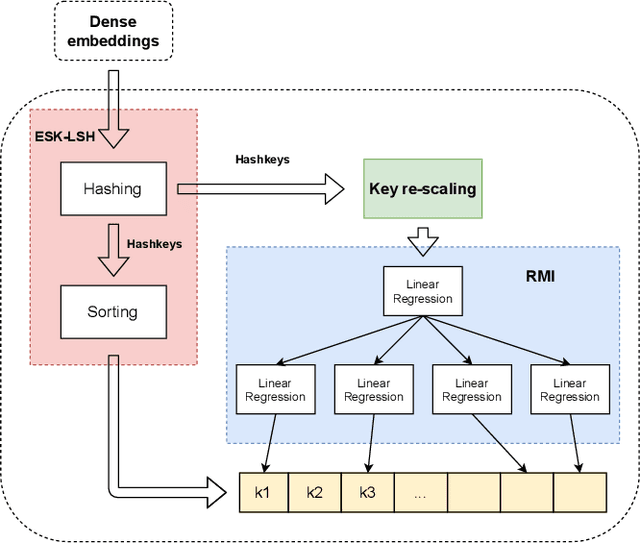
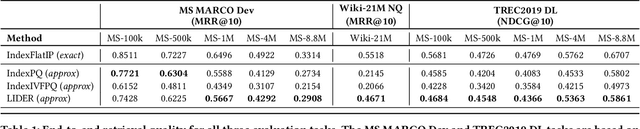
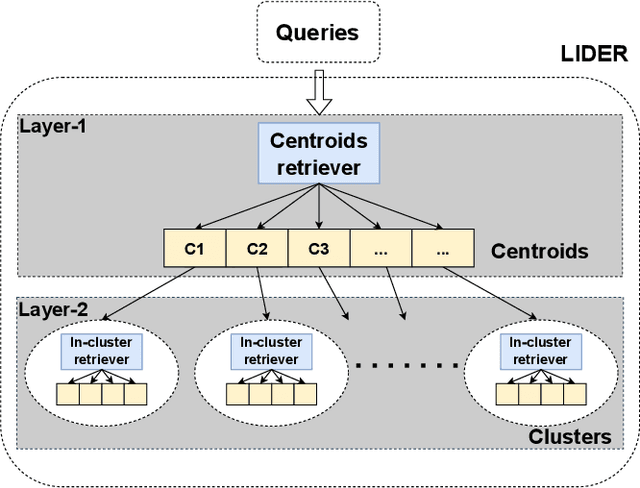
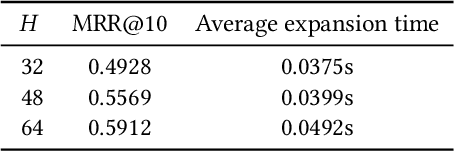
Text retrieval using dense embeddings generated from deep neural models is called "dense passage retrieval". Dense passage retrieval systems normally deploy a deep neural model followed by an approximate nearest neighbor (ANN) search module. The model generates text embeddings, which are then indexed by the ANN module. With the increasing data scale, the ANN module unavoidably becomes the bottleneck on efficiency, because of its linear or sublinear time complexity with data scale. An alternative is the learned index which has a theoretically constant time complexity. But most of the existing learned indexes are designed for low dimensional data. Thus they are not suitable for dense passage retrieval tasks with high-dimensional dense embeddings. We propose LIDER, an efficient high-dimensional Learned Index for large-scale DEnse passage Retrieval. LIDER has a clustering-based hierarchical architecture formed by two layers of core models. As the basic unit of LIDER to index and search data, each core model includes an adapted recursive model index (RMI) and a dimension reduction component which consists of an extended SortingKeys-LSH (SK-LSH) and a key re-scaling module. The dimension reduction component reduces the high-dimensional dense embeddings into one-dimensional keys and sorts them in a specific order, which are then used by the RMI. And the RMI consists of multiple simple linear regression models that make fast prediction in only O(1) time. We successfully optimize and combine SK-LSH and RMI together into the core model, and organize multiple core models into a two-layer structure based on a clustering-based partitioning of the whole data space. Experiments show that LIDER has a higher search speed with high retrieval quality comparing to the state-of-the-art ANN indexes commonly used in dense passage retrieval. Furthermore, LIDER has a better capability of speed-quality trade-off.