 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIDER: An Efficient High-dimensional Learned Index for Large-scale Dense Passage Retrieval
Paper and Code
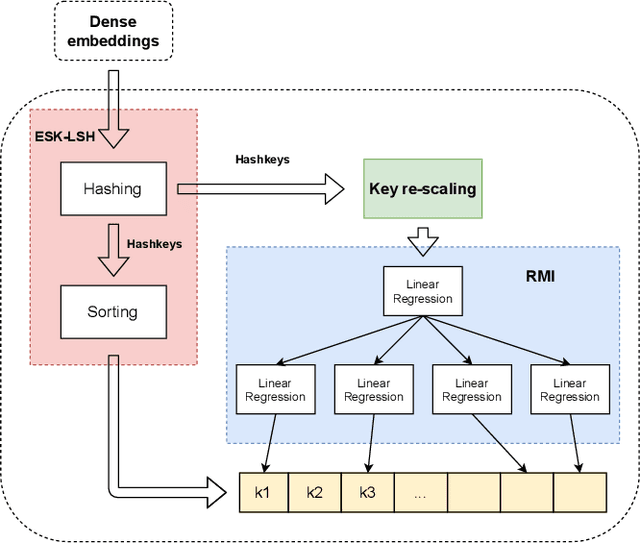
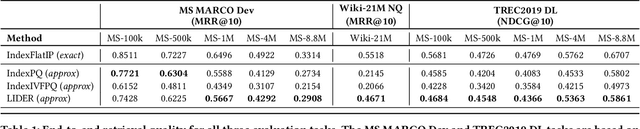
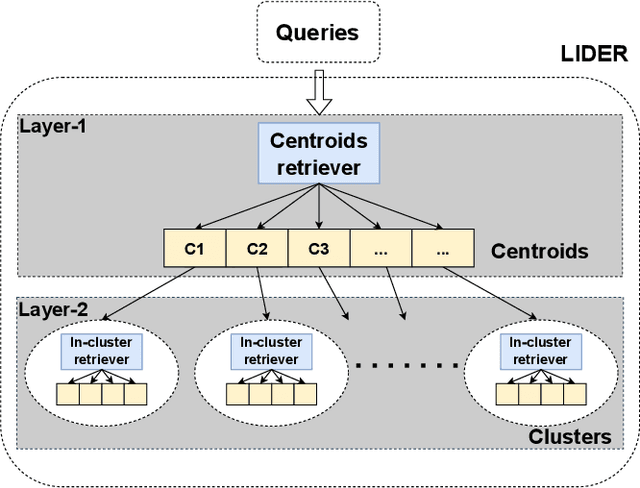
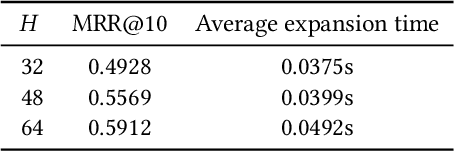
Text retrieval using dense embeddings generated from deep neural models is called "dense passage retrieval". Dense passage retrieval systems normally deploy a deep neural model followed by an approximate nearest neighbor (ANN) search module. The model generates text embeddings, which are then indexed by the ANN module. With the increasing data scale, the ANN module unavoidably becomes the bottleneck on efficiency, because of its linear or sublinear time complexity with data scale. An alternative is the learned index which has a theoretically constant time complexity. But most of the existing learned indexes are designed for low dimensional data. Thus they are not suitable for dense passage retrieval tasks with high-dimensional dense embeddings. We propose LIDER, an efficient high-dimensional Learned Index for large-scale DEnse passage Retrieval. LIDER has a clustering-based hierarchical architecture formed by two layers of core models. As the basic unit of LIDER to index and search data, each core model includes an adapted recursive model index (RMI) and a dimension reduction component which consists of an extended SortingKeys-LSH (SK-LSH) and a key re-scaling module. The dimension reduction component reduces the high-dimensional dense embeddings into one-dimensional keys and sorts them in a specific order, which are then used by the RMI. And the RMI consists of multiple simple linear regression models that make fast prediction in only O(1) time. We successfully optimize and combine SK-LSH and RMI together into the core model, and organize multiple core models into a two-layer structure based on a clustering-based partitioning of the whole data space. Experiments show that LIDER has a higher search speed with high retrieval quality comparing to the state-of-the-art ANN indexes commonly used in dense passage retrieval. Furthermore, LIDER has a better capability of speed-quality trade-off.