 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Reasoners: New Evaluation, Library, and Analysis of Step-by-Step Reasoning with Large Language Models
Apr 08, 2024Generating accurate step-by-step reasoning is essential for Large Language Models (LLMs) to address complex problems and enhance robustness and interpretability. Despite the flux of research on developing advanced reasoning approaches, systematically analyzing the diverse LLMs and reasoning strategies in generating reasoning chains remains a significant challenge. The difficulties stem from the lack of two key elements: (1) an automatic method for evaluating the generated reasoning chains on different tasks, and (2) a unified formalism and implementation of the diverse reasoning approaches for systematic comparison. This paper aims to close the gap: (1) We introduce AutoRace for fully automated reasoning chain evaluation. Existing metrics rely on expensive human annotations or pre-defined LLM prompts not adaptable to different tasks. In contrast, AutoRace automatically creates detailed evaluation criteria tailored for each task, and uses GPT-4 for accurate evaluation following the criteria. (2) We develop LLM Reasoners, a library for standardized modular implementation of existing and new reasoning algorithms, under a unified formulation of the search, reward, and world model components. With the new evaluation and library, (3) we conduct extensive study of different reasoning approaches (e.g., CoT, ToT, RAP). The analysis reveals interesting findings about different factors contributing to reasoning, including the reward-guidance, breadth-vs-depth in search, world model, and prompt formats, etc.
SELFOOD: Self-Supervised Out-Of-Distribution Detection via Learning to Rank
May 24, 2023



Deep neural classifiers trained with cross-entropy loss (CE loss) often suffer from poor calibration, necessitating the task of out-of-distribution (OOD) detection. Traditional supervised OOD detection methods require expensive manual annotation of in-distribution and OOD samples. To address the annotation bottleneck, we introduce SELFOOD, a self-supervised OOD detection method that requires only in-distribution samples as supervision. We cast OOD detection as an inter-document intra-label (IDIL) ranking problem and train the classifier with our pairwise ranking loss, referred to as IDIL loss. Specifically, given a set of in-distribution documents and their labels, for each label, we train the classifier to rank the softmax scores of documents belonging to that label to be higher than the scores of documents that belong to other labels. Unlike CE loss, our IDIL loss function reaches zero when the desired confidence ranking is achieved and gradients are backpropagated to decrease probabilities associated with incorrect labels rather than continuously increasing the probability of the correct label. Extensive experiments with several classifiers on multiple classification datasets demonstrate the effectiveness of our method in both coarse- and fine-grained settings.
Transformer-based Models for Long-Form Document Matching: Challenges and Empirical Analysis
Feb 07, 2023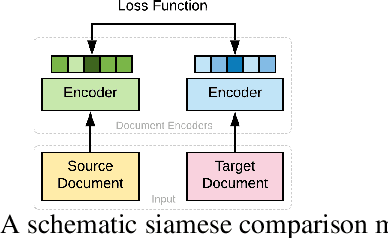
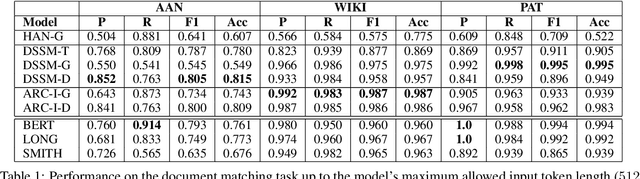
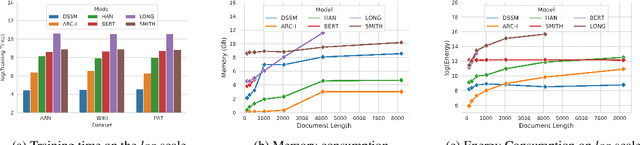

Recent advances in the area of long document matching have primarily focused on using transformer-based models for long document encoding and matching. There are two primary challenges associated with these models. Firstly, the performance gain provided by transformer-based models comes at a steep cost - both in terms of the required training time and the resource (memory and energy) consumption. The second major limitation is their inability to handle more than a pre-defined input token length at a time. In this work, we empirically demonstrate the effectiveness of simple neural models (such as feed-forward networks, and CNNs) and simple embeddings (like GloVe, and Paragraph Vector) over transformer-based models on the task of document matching. We show that simple models outperform the more complex BERT-based models while taking significantly less training time, energy, and memory. The simple models are also more robust to variations in document length and text perturbations.
Supervised Contrastive Learning for Interpretable Long Document Comparison
Aug 20, 2021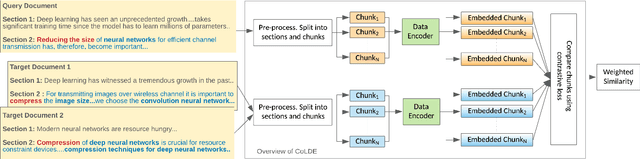
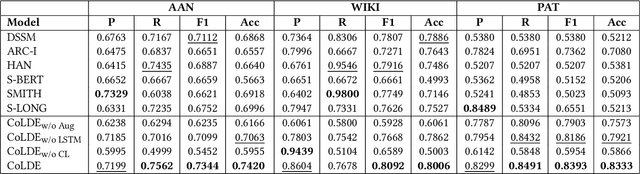
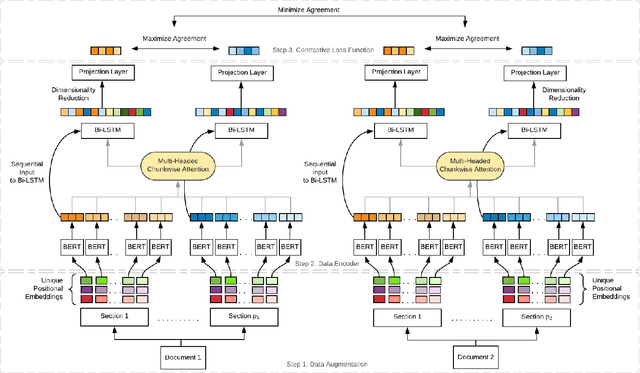

Recent advancements in deep learning techniques have transformed the area of semantic text matching. However, most of the state-of-the-art models are designed to operate with short documents such as tweets, user reviews, comments, etc., and have fundamental limitations when applied to long-form documents such as scientific papers, legal documents, and patents. When handling such long documents, there are three primary challenges: (i) The presence of different contexts for the same word throughout the document, (ii) Small sections of contextually similar text between two documents, but dissimilar text in the remaining parts -- this defies the basic understanding of "similarity", and (iii) The coarse nature of a single global similarity measure which fails to capture the heterogeneity of the document content. In this paper, we describe CoLDE: Contrastive Long Document Encoder -- a transformer-based framework that addresses these challenges and allows for interpretable comparisons of long documents. CoLDE uses unique positional embeddings and a multi-headed chunkwise attention layer in conjunction with a contrastive learning framework to capture similarity at three different levels: (i) high-level similarity scores between a pair of documents, (ii) similarity scores between different sections within and across documents, and (iii) similarity scores between different chunks in the same document and also other documents. These fine-grained similarity scores aid in better interpretability. We evaluate CoLDE on three long document datasets namely, ACL Anthology publications, Wikipedia articles, and USPTO patents. Besides outperforming the state-of-the-art methods on the document comparison task, CoLDE also proves interpretable and robust to changes in document length and text perturbations.