 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Contrastive Learning for Interpretable Long Document Comparison
Aug 20, 2021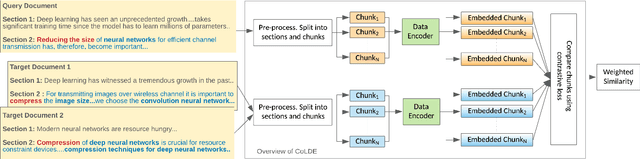
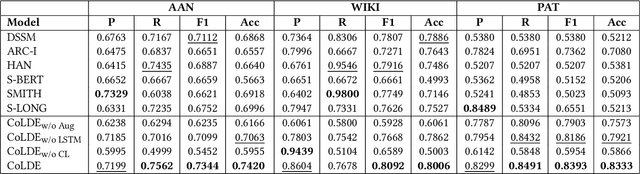
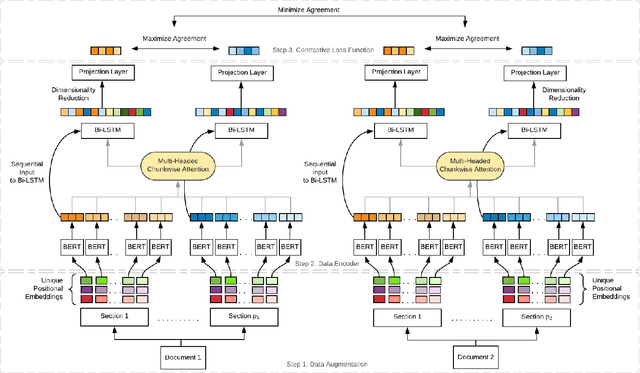

Recent advancements in deep learning techniques have transformed the area of semantic text matching. However, most of the state-of-the-art models are designed to operate with short documents such as tweets, user reviews, comments, etc., and have fundamental limitations when applied to long-form documents such as scientific papers, legal documents, and patents. When handling such long documents, there are three primary challenges: (i) The presence of different contexts for the same word throughout the document, (ii) Small sections of contextually similar text between two documents, but dissimilar text in the remaining parts -- this defies the basic understanding of "similarity", and (iii) The coarse nature of a single global similarity measure which fails to capture the heterogeneity of the document content. In this paper, we describe CoLDE: Contrastive Long Document Encoder -- a transformer-based framework that addresses these challenges and allows for interpretable comparisons of long documents. CoLDE uses unique positional embeddings and a multi-headed chunkwise attention layer in conjunction with a contrastive learning framework to capture similarity at three different levels: (i) high-level similarity scores between a pair of documents, (ii) similarity scores between different sections within and across documents, and (iii) similarity scores between different chunks in the same document and also other documents. These fine-grained similarity scores aid in better interpretability. We evaluate CoLDE on three long document datasets namely, ACL Anthology publications, Wikipedia articles, and USPTO patents. Besides outperforming the state-of-the-art methods on the document comparison task, CoLDE also proves interpretable and robust to changes in document length and text perturbations.