 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransactionGPT
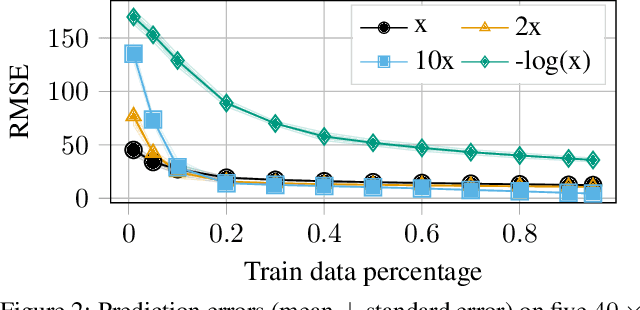
Nov 12, 2025We present TransactionGPT (TGPT), a foundation model for consumer transaction data within one of world's largest payment networks. TGPT is designed to understand and generate transaction trajectories while simultaneously supporting a variety of downstream prediction and classification tasks. We introduce a novel 3D-Transformer architecture specifically tailored for capturing the complex dynamics in payment transaction data. This architecture incorporates design innovations that enhance modality fusion and computational efficiency, while seamlessly enabling joint optimization with downstream objectives. Trained on billion-scale real-world transactions, TGPT significantly improves downstream classification performance against a competitive production model and exhibits advantages over baselines in generating future transactions. We conduct extensive empirical evaluations utilizing a diverse collection of company transaction datasets spanning multiple downstream tasks, thereby enabling a thorough assessment of TGPT's effectiveness and efficiency in comparison to established methodologies. Furthermore, we examine the incorporation of LLM-derived embeddings within TGPT and benchmark its performance against fine-tuned LLMs, demonstrating that TGPT achieves superior predictive accuracy as well as faster training and inference. We anticipate that the architectural innovations and practical guidelines from this work will advance foundation models for transaction-like data and catalyze future research in this emerging field.
MAIN-RAG: Multi-Agent Filtering Retrieval-Augmented Generation
Dec 31, 2024



Large Language Models (LLMs) are becoming essential tools for various natural language processing tasks but often suffer from generating outdated or incorrect information. Retrieval-Augmented Generation (RAG) addresses this issue by incorporating external, real-time information retrieval to ground LLM responses. However, the existing RAG systems frequently struggle with the quality of retrieval documents, as irrelevant or noisy documents degrade performance, increase computational overhead, and undermine response reliability. To tackle this problem, we propose Multi-Agent Filtering Retrieval-Augmented Generation (MAIN-RAG), a training-free RAG framework that leverages multiple LLM agents to collaboratively filter and score retrieved documents. Specifically, MAIN-RAG introduces an adaptive filtering mechanism that dynamically adjusts the relevance filtering threshold based on score distributions, effectively minimizing noise while maintaining high recall of relevant documents. The proposed approach leverages inter-agent consensus to ensure robust document selection without requiring additional training data or fine-tuning. Experimental results across four QA benchmarks demonstrate that MAIN-RAG consistently outperforms traditional RAG approaches, achieving a 2-11% improvement in answer accuracy while reducing the number of irrelevant retrieved documents. Quantitative analysis further reveals that our approach achieves superior response consistency and answer accuracy over baseline methods, offering a competitive and practical alternative to training-based solutions.
Transformer-based Models for Long-Form Document Matching: Challenges and Empirical Analysis
Feb 07, 2023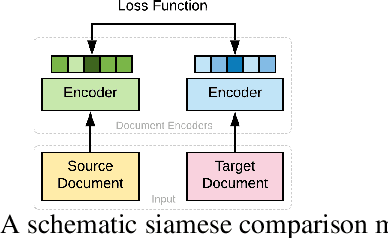
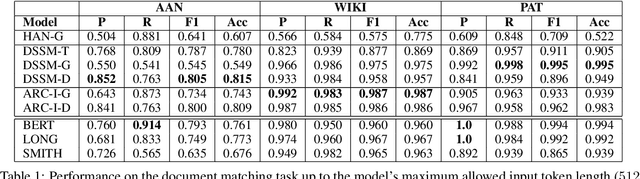
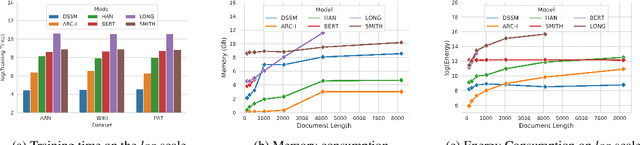

Recent advances in the area of long document matching have primarily focused on using transformer-based models for long document encoding and matching. There are two primary challenges associated with these models. Firstly, the performance gain provided by transformer-based models comes at a steep cost - both in terms of the required training time and the resource (memory and energy) consumption. The second major limitation is their inability to handle more than a pre-defined input token length at a time. In this work, we empirically demonstrate the effectiveness of simple neural models (such as feed-forward networks, and CNNs) and simple embeddings (like GloVe, and Paragraph Vector) over transformer-based models on the task of document matching. We show that simple models outperform the more complex BERT-based models while taking significantly less training time, energy, and memory. The simple models are also more robust to variations in document length and text perturbations.
SMARTQUERY: An Active Learning Framework for Graph Neural Networks through Hybrid Uncertainty Reduction
Dec 02, 2022



Graph neural networks have achieved significant success in representation learning. However, the performance gains come at a cost; acquiring comprehensive labeled data for training can be prohibitively expensive. Active learning mitigates this issue by searching the unexplored data space and prioritizing the selection of data to maximize model's performance gain. In this paper, we propose a novel method SMARTQUERY, a framework to learn a graph neural network with very few labeled nodes using a hybrid uncertainty reduction function. This is achieved using two key steps: (a) design a multi-stage active graph learning framework by exploiting diverse explicit graph information and (b) introduce label propagation to efficiently exploit known labels to assess the implicit embedding information. Using a comprehensive set of experiments on three network datasets, we demonstrate the competitive performance of our method against state-of-the-arts on very few labeled data (up to 5 labeled nodes per class).
Supervised Contrastive Learning for Interpretable Long Document Comparison
Aug 20, 2021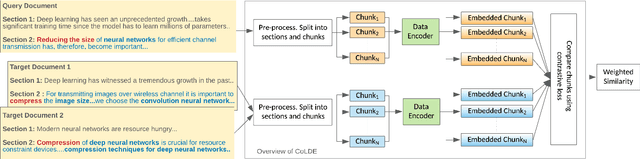
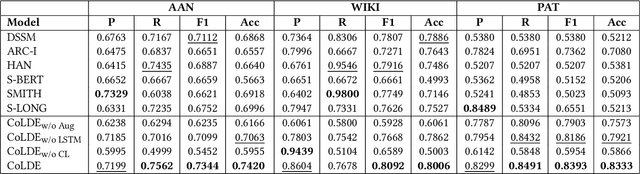
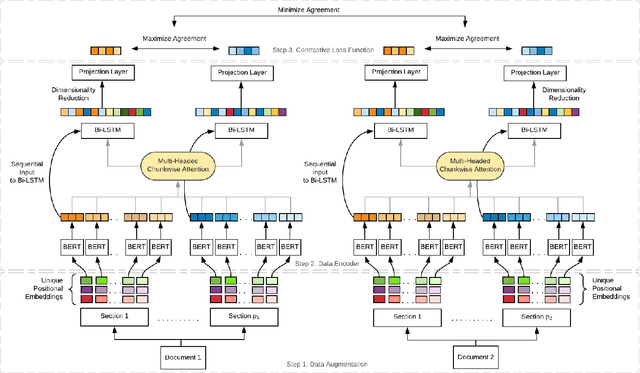

Recent advancements in deep learning techniques have transformed the area of semantic text matching. However, most of the state-of-the-art models are designed to operate with short documents such as tweets, user reviews, comments, etc., and have fundamental limitations when applied to long-form documents such as scientific papers, legal documents, and patents. When handling such long documents, there are three primary challenges: (i) The presence of different contexts for the same word throughout the document, (ii) Small sections of contextually similar text between two documents, but dissimilar text in the remaining parts -- this defies the basic understanding of "similarity", and (iii) The coarse nature of a single global similarity measure which fails to capture the heterogeneity of the document content. In this paper, we describe CoLDE: Contrastive Long Document Encoder -- a transformer-based framework that addresses these challenges and allows for interpretable comparisons of long documents. CoLDE uses unique positional embeddings and a multi-headed chunkwise attention layer in conjunction with a contrastive learning framework to capture similarity at three different levels: (i) high-level similarity scores between a pair of documents, (ii) similarity scores between different sections within and across documents, and (iii) similarity scores between different chunks in the same document and also other documents. These fine-grained similarity scores aid in better interpretability. We evaluate CoLDE on three long document datasets namely, ACL Anthology publications, Wikipedia articles, and USPTO patents. Besides outperforming the state-of-the-art methods on the document comparison task, CoLDE also proves interpretable and robust to changes in document length and text perturbations.
Efficacy of Bayesian Neural Networks in Active Learning
Apr 19, 2021

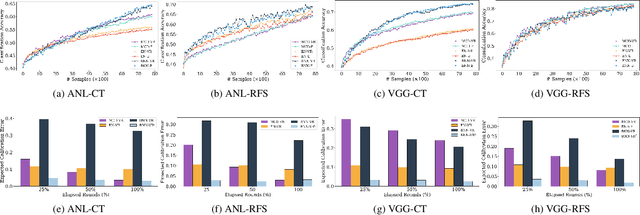
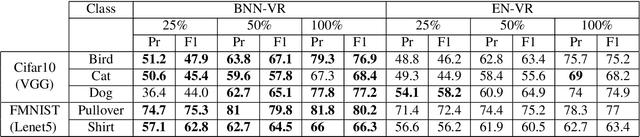
Obtaining labeled data for machine learning tasks can be prohibitively expensive. Active learning mitigates this issue by exploring the unlabeled data space and prioritizing the selection of data that can best improve the model performance. A common approach to active learning is to pick a small sample of data for which the model is most uncertain. In this paper, we explore the efficacy of Bayesian neural networks for active learning, which naturally models uncertainty by learning distribution over the weights of neural networks. By performing a comprehensive set of experiments, we show that Bayesian neural networks are more efficient than ensemble based techniques in capturing uncertainty. Our findings also reveal some key drawbacks of the ensemble techniques, which was recently shown to be more effective than Monte Carlo dropouts.
Matrix Completion in the Unit Hypercube via Structured Matrix Factorization
May 30, 2019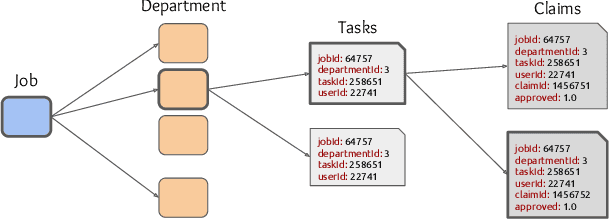


Several complex tasks that arise in organizations can be simplified by mapping them into a matrix completion problem. In this paper, we address a key challenge faced by our company: predicting the efficiency of artists in rendering visual effects (VFX) in film shots. We tackle this challenge by using a two-fold approach: first, we transform this task into a constrained matrix completion problem with entries bounded in the unit interval [0, 1]; second, we propose two novel matrix factorization models that leverage our knowledge of the VFX environment. Our first approach, expertise matrix factorization (EMF), is an interpretable method that structures the latent factors as weighted user-item interplay. The second one, survival matrix factorization (SMF), is instead a probabilistic model for the underlying process defining employees' efficiencies. We show the effectiveness of our proposed models by extensive numerical tests on our VFX dataset and two additional datasets with values that are also bounded in the [0, 1] interval.
Linked Causal Variational Autoencoder for Inferring Paired Spillover Effects
Oct 03, 2018
Modeling spillover effects from observational data is an important problem in economics, business, and other fields of research. % It helps us infer the causality between two seemingly unrelated set of events. For example, if consumer spending in the United States declines, it has spillover effects on economies that depend on the U.S. as their largest export market. In this paper, we aim to infer the causation that results in spillover effects between pairs of entities (or units), we call this effect as \textit{paired spillover}. To achieve this, we leverage the recent developments in variational inference and deep learning techniques to propose a generative model called Linked Causal Variational Autoencoder (LCVA). Similar to variational autoencoders (VAE), LCVA incorporates an encoder neural network to learn the latent attributes and a decoder network to reconstruct the inputs. However, unlike VAE, LCVA treats the \textit{latent attributes as confounders that are assumed to affect both the treatment and the outcome of units}. Specifically, given a pair of units $u$ and $\bar{u}$, their individual treatment and outcomes, the encoder network of LCVA samples the confounders by conditioning on the observed covariates of $u$, the treatments of both $u$ and $\bar{u}$ and the outcome of $u$. Once inferred, the latent attributes (or confounders) of $u$ captures the spillover effect of $\bar{u}$ on $u$. Using a network of users from job training dataset (LaLonde (1986)) and co-purchase dataset from Amazon e-commerce domain, we show that LCVA is significantly more robust than existing methods in capturing spillover effects.