 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe LLM Data Auditor: A Metric-oriented Survey on Quality and Trustworthiness in Evaluating Synthetic Data
Jan 27, 2026Large Language Models (LLMs) have emerged as powerful tools for generating data across various modalities. By transforming data from a scarce resource into a controllable asset, LLMs mitigate the bottlenecks imposed by the acquisition costs of real-world data for model training, evaluation, and system iteration. However, ensuring the high quality of LLM-generated synthetic data remains a critical challenge. Existing research primarily focuses on generation methodologies, with limited direct attention to the quality of the resulting data. Furthermore, most studies are restricted to single modalities, lacking a unified perspective across different data types. To bridge this gap, we propose the \textbf{LLM Data Auditor framework}. In this framework, we first describe how LLMs are utilized to generate data across six distinct modalities. More importantly, we systematically categorize intrinsic metrics for evaluating synthetic data from two dimensions: quality and trustworthiness. This approach shifts the focus from extrinsic evaluation, which relies on downstream task performance, to the inherent properties of the data itself. Using this evaluation system, we analyze the experimental evaluations of representative generation methods for each modality and identify substantial deficiencies in current evaluation practices. Based on these findings, we offer concrete recommendations for the community to improve the evaluation of data generation. Finally, the framework outlines methodologies for the practical application of synthetic data across different modalities.
Catastrophic Forgetting in Kolmogorov-Arnold Networks
Nov 16, 2025Catastrophic forgetting is a longstanding challenge in continual learning, where models lose knowledge from earlier tasks when learning new ones. While various mitigation strategies have been proposed for Multi-Layer Perceptrons (MLPs), recent architectural advances like Kolmogorov-Arnold Networks (KANs) have been suggested to offer intrinsic resistance to forgetting by leveraging localized spline-based activations. However, the practical behavior of KANs under continual learning remains unclear, and their limitations are not well understood. To address this, we present a comprehensive study of catastrophic forgetting in KANs and develop a theoretical framework that links forgetting to activation support overlap and intrinsic data dimension. We validate these analyses through systematic experiments on synthetic and vision tasks, measuring forgetting dynamics under varying model configurations and data complexity. Further, we introduce KAN-LoRA, a novel adapter design for parameter-efficient continual fine-tuning of language models, and evaluate its effectiveness in knowledge editing tasks. Our findings reveal that while KANs exhibit promising retention in low-dimensional algorithmic settings, they remain vulnerable to forgetting in high-dimensional domains such as image classification and language modeling. These results advance the understanding of KANs' strengths and limitations, offering practical insights for continual learning system design.
AutoL2S: Auto Long-Short Reasoning for Efficient Large Language Models
May 28, 2025The reasoning-capable large language models (LLMs) demonstrate strong performance on complex reasoning tasks but often suffer from overthinking, generating unnecessarily long chain-of-thought (CoT) reasoning paths for easy reasoning questions, thereby increasing inference cost and latency. Recent approaches attempt to address this challenge by manually deciding when to apply long or short reasoning. However, they lack the flexibility to adapt CoT length dynamically based on question complexity. In this paper, we propose Auto Long-Short Reasoning (AutoL2S), a dynamic and model-agnostic framework that enables LLMs to dynamically compress their generated reasoning path based on the complexity of the reasoning question. AutoL2S enables a learned paradigm, in which LLMs themselves can decide when longer reasoning is necessary and when shorter reasoning suffices, by training on data annotated with our proposed method, which includes both long and short CoT paths and a special <EASY> token. We then use <EASY> token to indicate when the model can skip generating lengthy CoT reasoning. This proposed annotation strategy can enhance the LLMs' ability to generate shorter CoT reasoning paths with improved quality after training. Extensive evaluation results show that AutoL2S reduces the length of reasoning generation by up to 57% without compromising performance, demonstrating the effectiveness of AutoL2S for scalable and efficient LLM reasoning.
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
Mar 20, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in complex tasks. Recent advancements in Large Reasoning Models (LRMs), such as OpenAI o1 and DeepSeek-R1, have further improved performance in System-2 reasoning domains like mathematics and programming by harnessing supervised fine-tuning (SFT) and reinforcement learning (RL) techniques to enhance the Chain-of-Thought (CoT) reasoning. However, while longer CoT reasoning sequences improve performance, they also introduce significant computational overhead due to verbose and redundant outputs, known as the "overthinking phenomenon". In this paper, we provide the first structured survey to systematically investigate and explore the current progress toward achieving efficient reasoning in LLMs. Overall, relying on the inherent mechanism of LLMs, we categorize existing works into several key directions: (1) model-based efficient reasoning, which considers optimizing full-length reasoning models into more concise reasoning models or directly training efficient reasoning models; (2) reasoning output-based efficient reasoning, which aims to dynamically reduce reasoning steps and length during inference; (3) input prompts-based efficient reasoning, which seeks to enhance reasoning efficiency based on input prompt properties such as difficulty or length control. Additionally, we introduce the use of efficient data for training reasoning models, explore the reasoning capabilities of small language models, and discuss evaluation methods and benchmarking.
I3S: Importance Sampling Subspace Selection for Low-Rank Optimization in LLM Pretraining
Feb 09, 2025



Low-rank optimization has emerged as a promising approach to enabling memory-efficient training of large language models (LLMs). Existing low-rank optimization methods typically project gradients onto a low-rank subspace, reducing the memory cost of storing optimizer states. A key challenge in these methods is identifying suitable subspaces to ensure an effective optimization trajectory. Most existing approaches select the dominant subspace to preserve gradient information, as this intuitively provides the best approximation. However, we find that in practice, the dominant subspace stops changing during pretraining, thereby constraining weight updates to similar subspaces. In this paper, we propose importance sampling subspace selection (I3S) for low-rank optimization, which theoretically offers a comparable convergence rate to the dominant subspace approach. Empirically, we demonstrate that I3S significantly outperforms previous methods in LLM pretraining tasks.
Confident or Seek Stronger: Exploring Uncertainty-Based On-device LLM Routing From Benchmarking to Generalization
Feb 06, 2025Large language models (LLMs) are increasingly deployed and democratized on edge devices. To improve the efficiency of on-device deployment, small language models (SLMs) are often adopted due to their efficient decoding latency and reduced energy consumption. However, these SLMs often generate inaccurate responses when handling complex queries. One promising solution is uncertainty-based SLM routing, offloading high-stakes queries to stronger LLMs when resulting in low-confidence responses on SLM. This follows the principle of "If you lack confidence, seek stronger support" to enhance reliability. Relying on more powerful LLMs is yet effective but increases invocation costs. Therefore, striking a routing balance between efficiency and efficacy remains a critical challenge. Additionally, efficiently generalizing the routing strategy to new datasets remains under-explored. In this paper, we conduct a comprehensive investigation into benchmarking and generalization of uncertainty-driven routing strategies from SLMs to LLMs over 1500+ settings. Our findings highlight: First, uncertainty-correctness alignment in different uncertainty quantification (UQ) methods significantly impacts routing performance. Second, uncertainty distributions depend more on both the specific SLM and the chosen UQ method, rather than downstream data. Building on the insight, we propose a calibration data construction instruction pipeline and open-source a constructed hold-out set to enhance routing generalization on new downstream scenarios. The experimental results indicate calibration data effectively bootstraps routing performance without any new data.
Survey and Improvement Strategies for Gene Prioritization with Large Language Models
Jan 30, 2025


Rare diseases are challenging to diagnose due to limited patient data and genetic diversity. Despite advances in variant prioritization, many cases remain undiagnosed. While large language models (LLMs) have performed well in medical exams, their effectiveness in diagnosing rare genetic diseases has not been assessed. To identify causal genes, we benchmarked various LLMs for gene prioritization. Using multi-agent and Human Phenotype Ontology (HPO) classification, we categorized patients based on phenotypes and solvability levels. As gene set size increased, LLM performance deteriorated, so we used a divide-and-conquer strategy to break the task into smaller subsets. At baseline, GPT-4 outperformed other LLMs, achieving near 30% accuracy in ranking causal genes correctly. The multi-agent and HPO approaches helped distinguish confidently solved cases from challenging ones, highlighting the importance of known gene-phenotype associations and phenotype specificity. We found that cases with specific phenotypes or clear associations were more accurately solved. However, we observed biases toward well-studied genes and input order sensitivity, which hindered gene prioritization. Our divide-and-conquer strategy improved accuracy by overcoming these biases. By utilizing HPO classification, novel multi-agent techniques, and our LLM strategy, we improved causal gene identification accuracy compared to our baseline evaluation. This approach streamlines rare disease diagnosis, facilitates reanalysis of unsolved cases, and accelerates gene discovery, supporting the development of targeted diagnostics and therapies.
MAIN-RAG: Multi-Agent Filtering Retrieval-Augmented Generation
Dec 31, 2024



Large Language Models (LLMs) are becoming essential tools for various natural language processing tasks but often suffer from generating outdated or incorrect information. Retrieval-Augmented Generation (RAG) addresses this issue by incorporating external, real-time information retrieval to ground LLM responses. However, the existing RAG systems frequently struggle with the quality of retrieval documents, as irrelevant or noisy documents degrade performance, increase computational overhead, and undermine response reliability. To tackle this problem, we propose Multi-Agent Filtering Retrieval-Augmented Generation (MAIN-RAG), a training-free RAG framework that leverages multiple LLM agents to collaboratively filter and score retrieved documents. Specifically, MAIN-RAG introduces an adaptive filtering mechanism that dynamically adjusts the relevance filtering threshold based on score distributions, effectively minimizing noise while maintaining high recall of relevant documents. The proposed approach leverages inter-agent consensus to ensure robust document selection without requiring additional training data or fine-tuning. Experimental results across four QA benchmarks demonstrate that MAIN-RAG consistently outperforms traditional RAG approaches, achieving a 2-11% improvement in answer accuracy while reducing the number of irrelevant retrieved documents. Quantitative analysis further reveals that our approach achieves superior response consistency and answer accuracy over baseline methods, offering a competitive and practical alternative to training-based solutions.
Personalizing Low-Rank Bayesian Neural Networks Via Federated Learning
Oct 18, 2024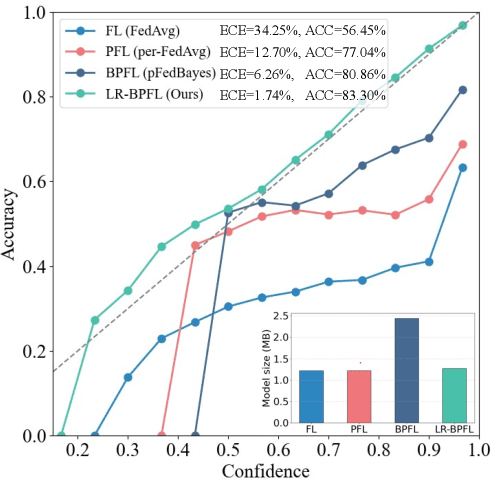
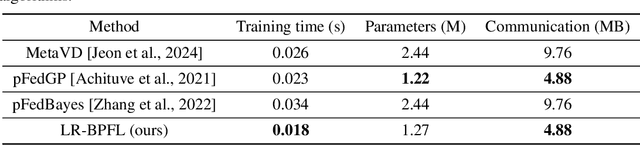
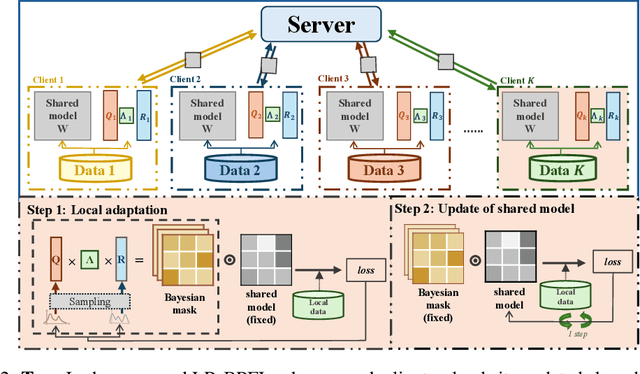

To support real-world decision-making, it is crucial for models to be well-calibrated, i.e., to assign reliable confidence estimates to their predictions. Uncertainty quantification is particularly important in personalized federated learning (PFL), as participating clients typically have small local datasets, making it difficult to unambiguously determine optimal model parameters. Bayesian PFL (BPFL) methods can potentially enhance calibration, but they often come with considerable computational and memory requirements due to the need to track the variances of all the individual model parameters. Furthermore, different clients may exhibit heterogeneous uncertainty levels owing to varying local dataset sizes and distributions. To address these challenges, we propose LR-BPFL, a novel BPFL method that learns a global deterministic model along with personalized low-rank Bayesian corrections. To tailor the local model to each client's inherent uncertainty level, LR-BPFL incorporates an adaptive rank selection mechanism. We evaluate LR-BPFL across a variety of datasets, demonstrating its advantages in terms of calibration, accuracy, as well as computational and memory requirements.
Taylor Unswift: Secured Weight Release for Large Language Models via Taylor Expansion
Oct 06, 2024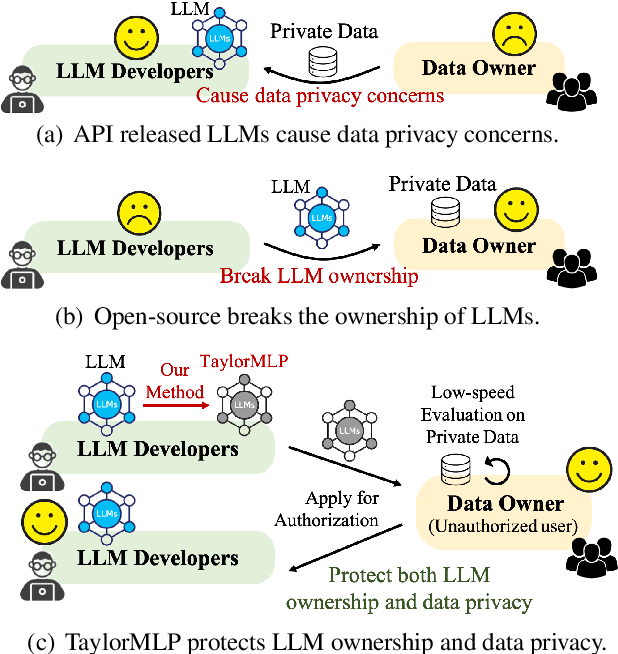
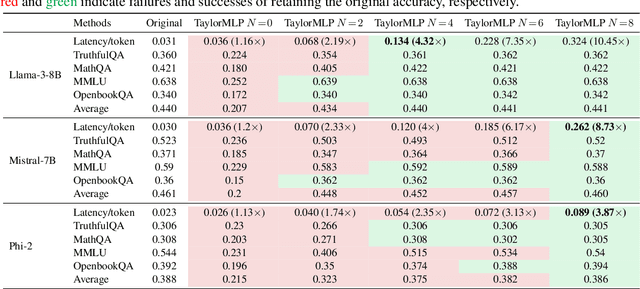
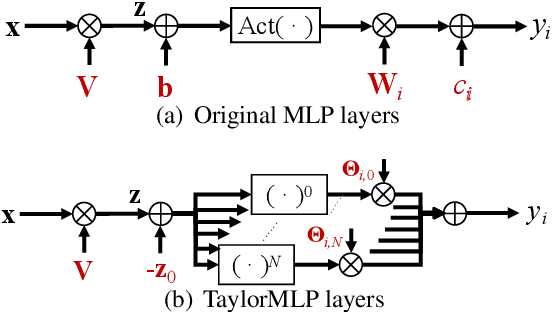

Ensuring the security of released large language models (LLMs) poses a significant dilemma, as existing mechanisms either compromise ownership rights or raise data privacy concerns. To address this dilemma, we introduce TaylorMLP to protect the ownership of released LLMs and prevent their abuse. Specifically, TaylorMLP preserves the ownership of LLMs by transforming the weights of LLMs into parameters of Taylor-series. Instead of releasing the original weights, developers can release the Taylor-series parameters with users, thereby ensuring the security of LLMs. Moreover, TaylorMLP can prevent abuse of LLMs by adjusting the generation speed. It can induce low-speed token generation for the protected LLMs by increasing the terms in the Taylor-series. This intentional delay helps LLM developers prevent potential large-scale unauthorized uses of their models. Empirical experiments across five datasets and three LLM architectures demonstrate that TaylorMLP induces over 4x increase in latency, producing the tokens precisely matched with original LLMs. Subsequent defensive experiments further confirm that TaylorMLP effectively prevents users from reconstructing the weight values based on downstream datasets.